Lambda Architecture: How to Build a Big Data Pipeline, Part 2 [Video]
We walk you through how to provide a robust system that is fault-tolerant against hardware failures and human mistakes using the Lambda architecture approach.
Join the DZone community and get the full member experience.
Join For FreeThis is the second part of a series of articles that present a Lambda architecture. If you haven’t seen Part 1, check it out.
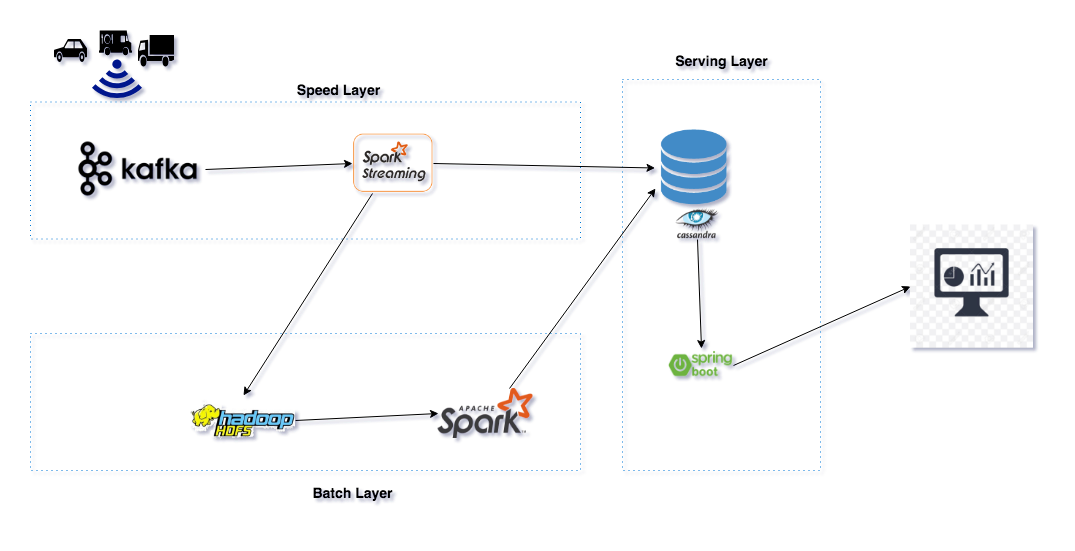
The idea of this post is to walk you through how we provide a robust system that is fault-tolerant against hardware failures and human mistakes using the Lambda architecture approach.
Lambda architecture handles these issues by processing the data twice, once in the real-time streaming to give a quick view of the data/metrics that get generated and a second time in a scheduled batch process to give a more reliable view of the data/metrics.
Video Tutorial: Building a Big Data Pipeline, Part 1
Video Tutorial: Building a Big Data Pipeline, Part 2
Video Tutorial: Building a Big Data Pipeline, Part 3
Published at DZone with permission of Alexsandro Souza. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments