Design Twitter Like Application Using Lambda Architecture
Lambda Architecture is one of the most useful frameworks to design big data applications and distributed data processing systems like social network platforms.
Join the DZone community and get the full member experience.
Join For FreeThe key necessity of the private social community application is to build a platform for a individuals' network who come together online to socialize and communicate through posting information in the form of images, comments, or messages. Apart from functional aspects, other important dimensions to be considered for designing the social networking platform include:
- Fault tolerance against hardware failures and human errors.
- Must include low latency querying as well as updates.
- Support active communities of millions of users.
- Usage of open-source big data solutions to reduce costs.
Lambda Architecture
Lambda Architecture is a very useful framework to think about designing big data applications and distributed data processing systems like social network platforms. It provides a data-processing platform that can support both historic as well as real-time data processing, which is a key necessity for a social community application. The below diagram depicts a suitable architecture of the social community application and high-level details of components involved using this architecture.
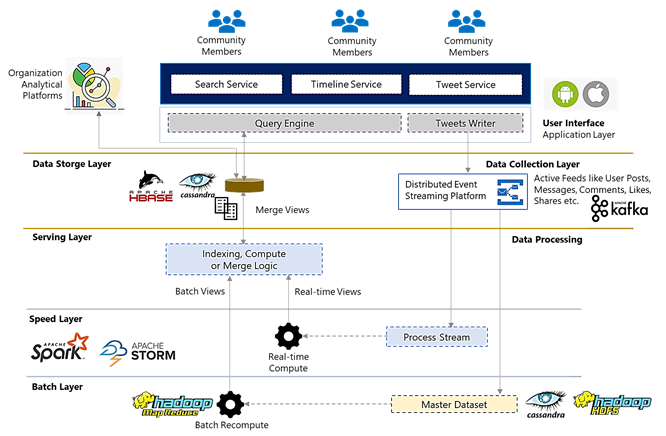
Major components of any such architecture include:
- Application layer
- Data Collection layer
- Data Processing layer
Application Layer (User Interface)
The application layer will be generally a user interface that can be used by authenticated and authorized community users or groups. This layer would include major services like Tweet, Timeline, User, or Search services. A tweet service would be a service that could be used to create active feeds, posts, or share messages while a timeline services to view the tweets.
Timeline service would further include home timeline service (display tweets from friends or the people user follows) and user timeline service (display his/her own tweets). The other services of this layer like search service can be used to get finetuned information based on keywords or hashtags and user-related services for updating user profile data.
Data Collection Layer
In general tweets, the writer service of the application layer would insert all the incoming feed into the data collection layer. The data collection layer is a distributed event streaming platform and technologies like Apache Kafka can be used for the data collection layer. The major purpose of this data collection layer is to:
- Provide required delivery semantics at least once in the streaming data systems and ensure safe message delivery.
- Prevent the data processing layer from a huge processing backlog.
Data Processing Layer
The data processing layer is further divided into the batch, speed, and serving layers. The active data feed coming continuously from the data collection layer is pushed into the master dataset which is an immutable set of raw data) of batch layer and simultaneously to the speed layer for real-time data processing. The batch layer mostly follows the traditional ETL and data warehouse approach. This layer is built using a pre-defined schedule, looks at all the data at once, and pre-computes the batch views.
The speed layer processes only recent data and creates real-time views. The outputs from the batch layer (batch views) and speed layer (near real-time views) get forwarded to the serving layer. This layer is used to index the batch views to be queried in a low-latency, ad-hoc way. Let’s understand the data flow of the proposed architecture with the use case of tweet feed and user timeline.
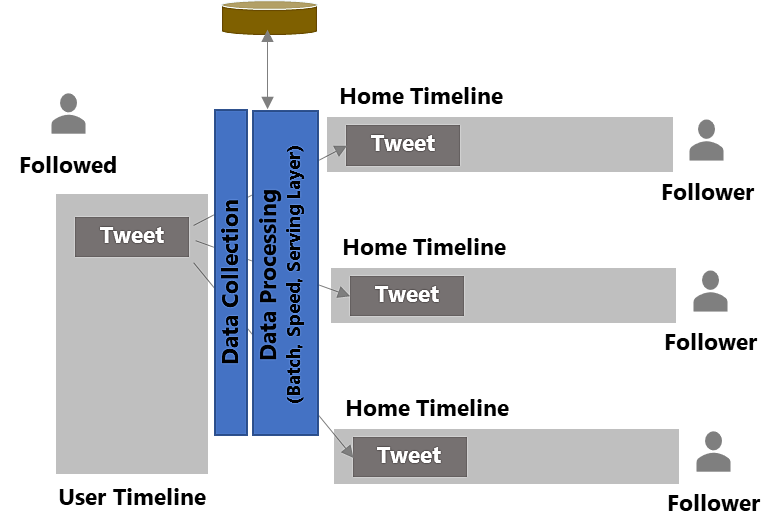
Whenever a user posts a tweet on his timeline, the tweet writer service of the proposed architecture would trigger an event with all the associated tweet data (e.g., TweetID, UserID, Tweet Message, Time Stamp, etc.) and sends that to the topic of distributed event streaming platform. The producer associated with the message service gets notified about the event and its associated data, which in turn would direct the incoming tweet data to both batch and speed layers for further processing.
Batch Layer
The batch layer is extremely reliable for processing large datasets and the batch processing job is run on a pre-defined schedule (usually once or twice a day). Batch layer datasets can be stored in a distributed file system while MapReduce can be used for batch processing. Let us assume that all the incoming tweet feed is inserted into the “Tweets” table of the master dataset in the batch layer. Once a batch is processed, batch views would be created and stored for further processing in the serving layer.
Speed Layer
Speed layer deals with only the recent data i.e. the data that is not delivered in batch view due to latency of batch layer. The tweet messages that are passed to this layer are quickly processed as they are received and the corresponding real-time views are generated and stored. Technologies like Apache Spark or Storm can be utilized for real-time and near real-time processing.
Serving Layer
The serving layer indexes the batch views and also contains the logic for merging real-time and batch views. The lambda architecture pre-computes the timeline feed once and simply updates it with the latest real-time views. This way the user timeline with real-time plus historic data is pre-computed and stored in distributed storage systems like HBase or Cassandra. Fields like tweet id, user id, user name, location, friends count can be stored in the tweets table which would be part of the master dataset, while fields like user id, friend count, created date as part of a real-time, batch, or merge views.
So we have understood the data flow of Lambda architecture. But, how does Lambda architecture help with other dimensions of fault tolerance, robustness, and scalability?
Robustness and fault tolerance: It helps systems to be tolerant to machines failure and human errors such as data corruption. The batch and real-time views can always be recomputed from the master dataset.
Low latency read and update: Lambda architecture allows to achieve both the low latency and update without compromising robustness.
Scalability: All the layers from data collection to processing can be scaled independently.
Generalization: Lambda architecture can be used across many different applications.
Though Lambda architecture is most suited for designing twitter-like apps, maintaining separate code bases for batch and stream layers can be extremely difficult, making design and maintenance of this kind of architecture highly complex.
Opinions expressed by DZone contributors are their own.
Comments