ETL and How it Changed Over Time
Join the DZone community and get the full member experience.
Join For FreeWhat Is ETL?
ETL is the abbreviation for Extract, Transformation, and Load. In simple terms, it is just copying data between two locations.[1]
- Extract: The process of reading the data from different types of sources including databases.
- Transform: Converting the extracted data to a particular format. Conversion also involves enriching the data using other data in the system.
- Load: The process of writing the data to a target database, data warehouse, or another system.
ETL can be differentiated into 2 categories with regards to the infrastructure.
Traditional ETL
Back in the day, data was normally located in popular locations known to us as operational databases, files, and data-warehouses. Data was moved between these locations a few times a day. ETL tools and scripts were plugged in an ad hoc manner to connect the sources and destinations as they arrived.
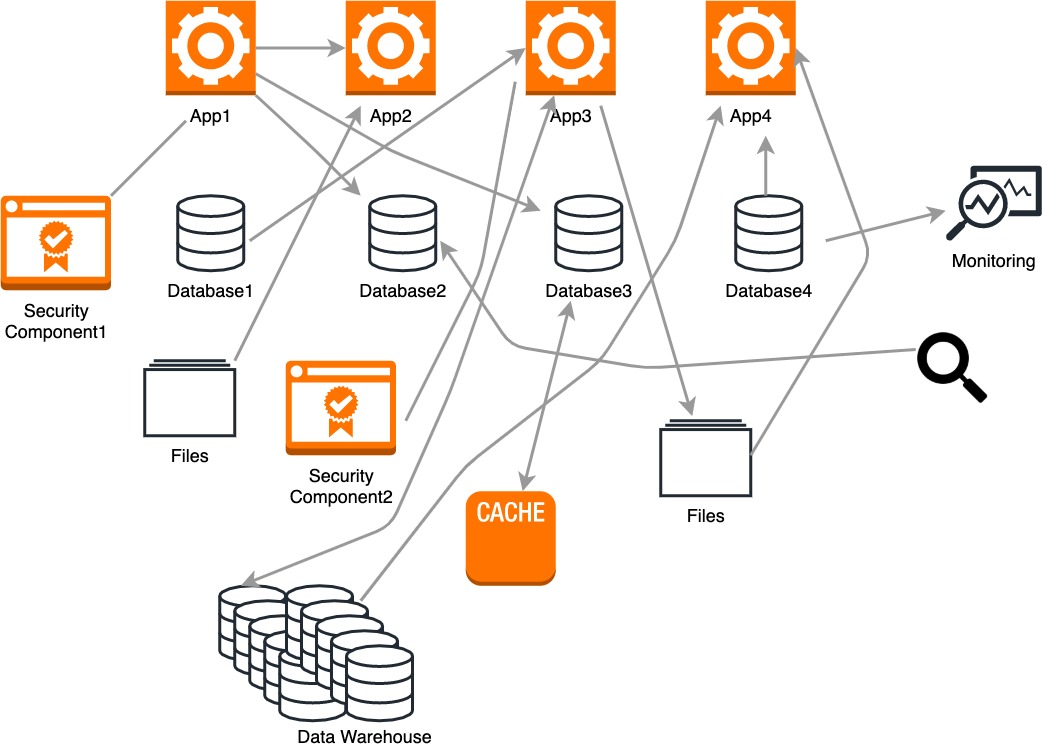
This particular architecture was unmanageable and quite complicated. The following are some disadvantages of traditional ETL architecture:
- Processing between databases, files, and data-warehouses is done in batch fashion.
- Currently, most companies tend to analyze and do operations on the real-time data. However, traditional tools were not designed to process logs, sensor data, metrics data, etc.
- Data modeling for a very large domain required a global schema.
- The traditional ETL process is slow, time-consuming, and resource-intensive.
- The traditional architecture is focussed only on the technology back then. Hence, new technology was introduced, the applications and the tools had to be written from scratch to connect.
With time, big data changed the order of the process. The data is extracted and loaded to a repository and kept there in the original format. Data is transformed whenever it is needed by data analysts or other systems. This is called ELT. However, this is most advantageous when processing data in warehouses. Systems, such as Oracle Data Integration Platform Cloud, offer this capability.
You may also like: Real-Time Stream Processing With Apache Kafka Part One.
Current State of ETL
Modern world data and its usage has drastically changed when compared to a decade ago. There is a gap caused by the traditional ETL processes when processing modern data. The following are some of the main reasons for this:
- Modern data processes often include real-time streaming data, and organizations need real-time insights into processes.
- The systems need to perform ETL on data streams without using batch processing, and they should handle high data rates by scaling the system.
- Some single-server databases are now replaced by distributed data platforms (e.g., Cassandra, MongoDB, Elasticsearch, SAAS apps), message brokers(e.g., Kafka, ActiveMQ, etc.) and several other types of endpoints.
- The system should have the capability to plugin additional sources or sinks to connect on the go in a manageable way.
- Repeated data processing due to ad hoc architecture has to be eliminated.
- Change data capture technologies used with traditional ETL has to be integrated to also support traditional operations.
- Heterogeneous data sources are available and should look at maintenance with new requirements.
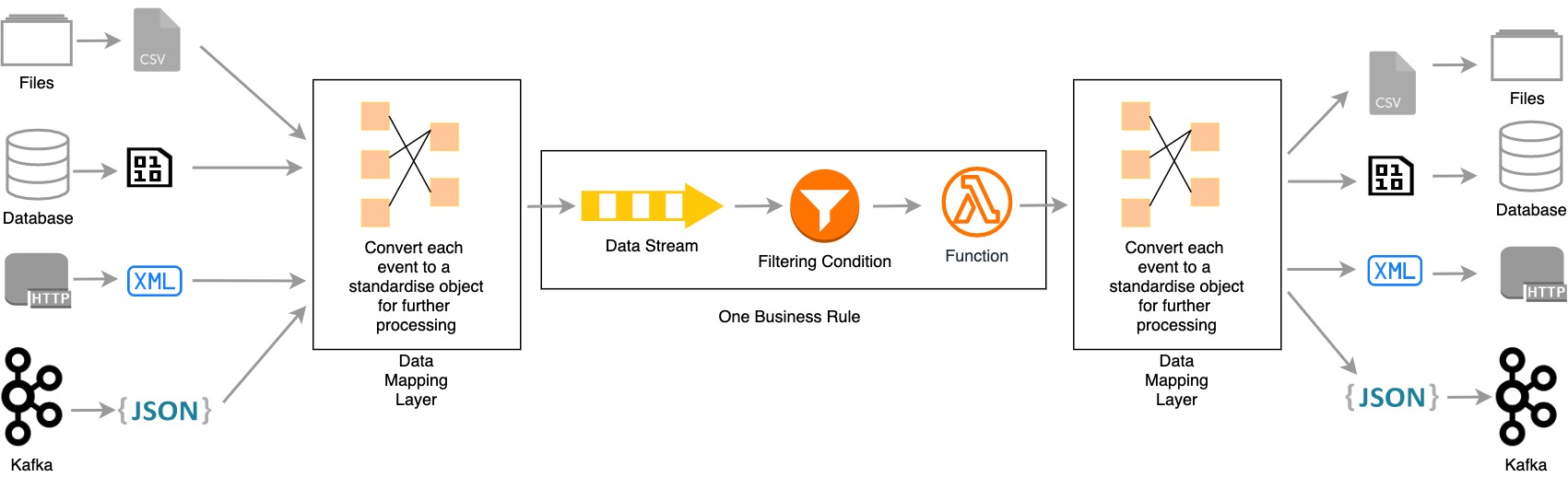
Sources and Target endpoints should be decoupled from the business logic. Data mapper layers should allow new sources and endpoints to be plugged in seamlessly in a manner that does not affect the transformation.
![Data mapping layer]()
Data mapping layer - Received data should be standardized before transformation (or executing business rules).
- Data should be converted to specific formats after transformation and before publishing to endpoints.
- Data cleansing is not the only process defined in transformation in the modern world. There are many business requirements that organizations need to be fulfilled.
- Current data processing should use filters, joins, aggregations, sequences, patterns, and enriching mechanisms to execute complex business rules.
![Data processing workflow]()
Data processing workflow
- Current data processing should use filters, joins, aggregations, sequences, patterns, and enriching mechanisms to execute complex business rules.
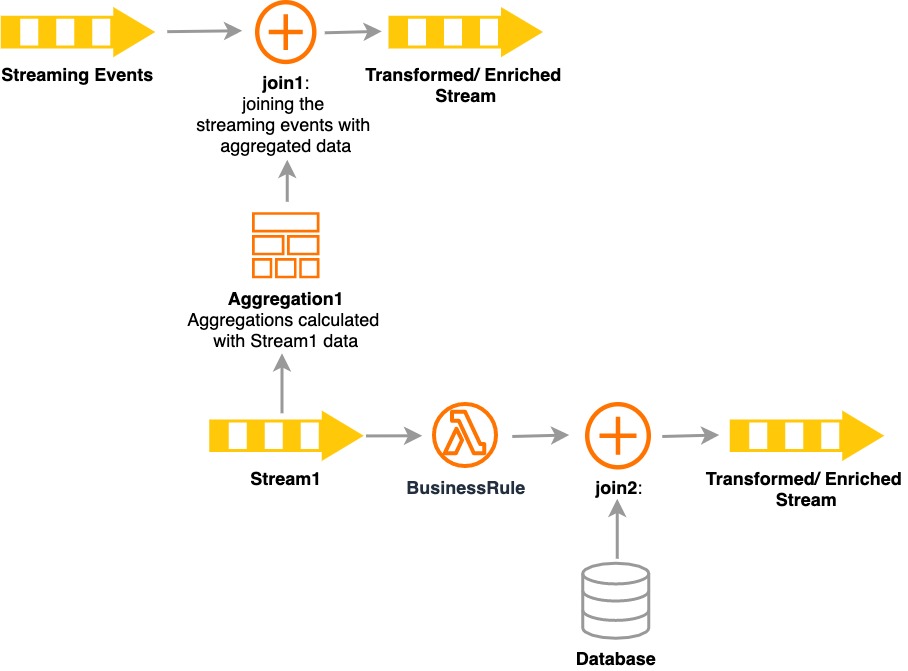
Streaming ETL to the Rescue
Data is the fuel that drives an organization due to the new demand of data. Most of the traditional systems are still operational in most organizations, and it uses databases and file systems. The same organizations are now trying to move towards new systems and new technologies. These technologies have the capability to handle the growth of big data and high data rates, such as tens of thousands of records per second, such as Kafka, ActiveMQ, etc.
With a streaming ETL integration architecture, the organizations do not need to plan, design and implement a complex architecture to fill the gap between traditional and current systems. The streaming ETL architecture is scalable and manageable while catering to a high volume of real-time data with a high diversity including evolving schemas.
The source sink model is introduced by decoupling extract and loading from transformation and that has also made the system forward compatible with new technologies and functionalities. This functionality can be achieved via several systems, such as Apache Kafka (with KSQL), Talend, Hazelcast, Striim, and WSO2 Streaming Integrator (with Siddhi IO).
Modern ETL Functions
As mentioned above, legacy systems usually dump all the data to databases and to file systems that are available for processing in batches. This scenario explains how traditional event sources, such as files and Change Data Capture (CDC) are integrated with new streaming integrator platforms.
Let’s consider a practical scenario in a production factory that has following functionalities.
The traditional system,
- Dumps all the production data into a file system and a database with a variety of different schemas.
- Processes the dumped files hourly or daily.
- Processes events, received from CDC.
- Processes the event-centric data that is received by new systems (via HTTP).
- Sends processed events to multiple destinations.
- Monitors the current stock and sends a notification when new stock is needed.
- Views analytics using stock numbers.
In traditional ETL tools:
- ETL processing logic is duplicated for the following:
- For each file and database with a different schema.
- When the number of target or source endpoints increases.
- Duplicated business logic is hard to manage and scale.
- Calculating processes are repeated when data retrieved for analytics and monitoring.
How Streaming Platform Architecture Resolves Modern ETL Issues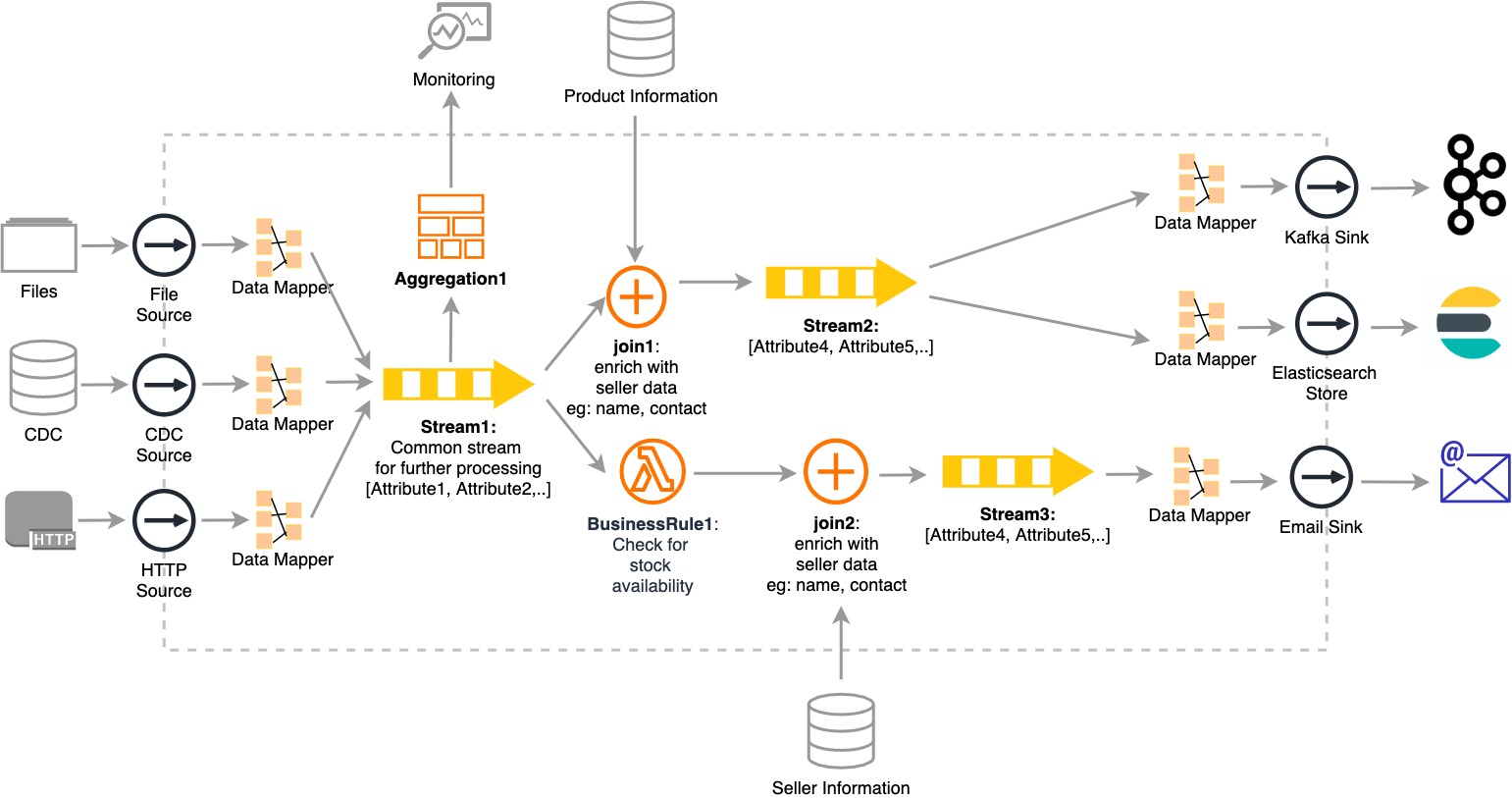
- Sources (e.g., Files, CDC, HTTP) and Target endpoints (e.g., Kafka, Elasticsearch, Email) are decoupled from processing:
- Sink, Source, and Store APIs connect a numerous number of data sources.
- Even though there are different data schemas throughout the sources and sinks, the Data Mapping (e.g., data mapper) layer and Streaming SQL (e.g., Query1) convert events received via multiple sources to a common stream definition (Stream1) for further processing.
- Streaming Platform Architecture connects traditional types of sources, such as Files and CDC, and also widely used modern sources like HTTP.
- Events generated from legacy and modern systems are received and analyzed in a single flow.
- Aggregations (e.g., Aggregation1) are computed for necessary attributes by the minute, hour, etc.
- Data is summarized on the go without the requirement to process and summarize the whole dataset when needed. Applications and visualizing and monitoring tools can access summarized data via the provided APIs.
- One or several statements of business logic (e.g., BusinessRule1) can be added and changed seamlessly.
- Any logic can be added without doing any changes to the existing components. As in the example, an email message flow is triggered when critical levels come up according to the BusinessRule1.
With the above architecture, we can see how Streaming Platform integrates legacy systems, such as file and CDC with modern systems that use Kafka and HTTP for ETL processing.
You can refer to this Streaming ETL With WSO2 Streaming Integrator article on how WSO2 Streaming Integrator provided a solution for a complex ETL scenario.
Opinions expressed by DZone contributors are their own.
Comments