Interpreting Kafka's Exactly-Once Semantics
Apache Kafka comes out-of-the-box packed with great data science features. We take a look at few of them in this post.
Join the DZone community and get the full member experience.
Join For FreeUntil recently most organizations have been struggling to achieve the holy grail of message delivery, the exactly-once delivery semantic. Although this has been an out-of-the-box feature since Apache Kafkas 0.11, people are still slow in picking up this feature. Let's take a moment in understanding exactly-once semantics. What is the big deal about it and how does Kafka solve the problem?
Apache Kafka offers following delivery guarantees. Let's understand what this really means:
At Most Once Delivery: It guarantees that a particular message can either be delivered once or not at all. There can be a loss of messages but a message can never be delivered more than once.
At Least Once Delivery: It guarantees that a particular message will always be delivered. It can be delivered multiple times but there will never be any messages lost.
Exactly Once Delivery: It guarantees that all messages will always be delivered exactly once. Exactly once does not mean that there will be no failures or no retries. These are inevitable. The important thing is that the retries succeed. In other words, the result should be the same, whether it has been successfully processed exactly once or not.
Why Exactly-Once Is Important
There are certain use cases (like financial applications, IoT applications, and other streaming applications) which cannot afford anything less than exactly-once. You cannot afford to have duplicates or lose messages when depositing or withdrawing money from a bank account. It needs exactly-once as a final outcome.
Why it Is Difficult to Achieve
Assuming you have a small Kafka stream application with few inputs feeding partitions and few output partitions. The intent and expectation of the application is to receive data from input partitions, process the data, and write the same to output partitions. This is where one wants to achieve exactly-once as a guarantee. There are scenarios due to network glitches, system crashes, and other errors where duplicates get introduced during the process.
Problem 1: Duplicate or Multiple Writes
Refer to Figure 1a. Message m1 is being processed and being written to Topic B. Message m1 gets successfully written to Topic B (as m1') but the acknowledgment is not received. The reason could be, let's say, network delay and this eventually gets timed out.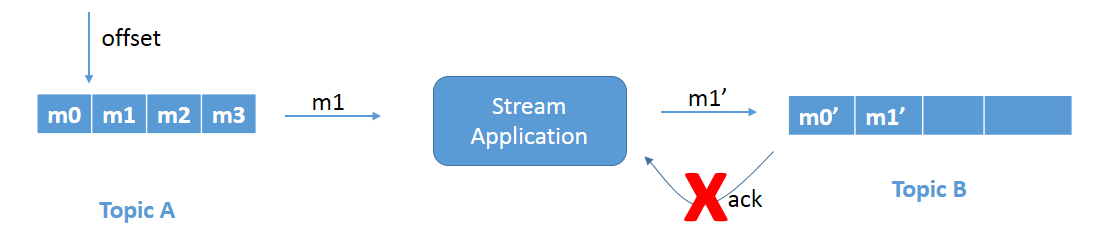
Figure 1a: Duplicate write problem.
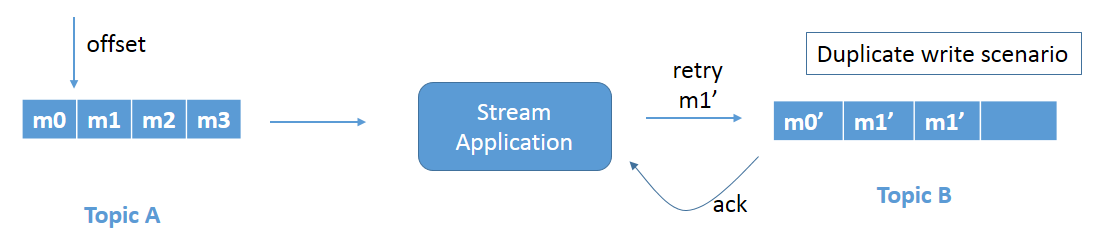
Figure 1b: Duplicate write problem due to retry.
Since the application does not know that the message is already successfully written, as it never received the acknowledgment, it retries and leads to a duplicate write. Refer to Figure 1b. Message m1' gets rewritten to Topic B. This is a duplicate write issue and needs to be fixed.
Problem 2: Reread Input Record
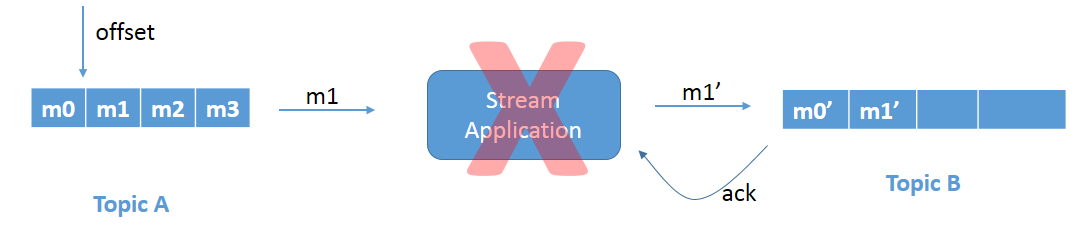
Figure 2a: Reread problem due to the application crashing.
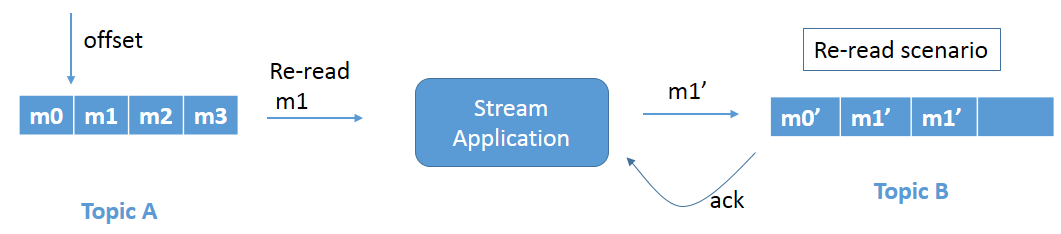
Figure 2b: Reread problem when the crashed application restarts.
Refer to Figure 2a. We have the same scenario as above, but, in this case, the stream application crashes just before committing the offset. Since the offset is not committed, when the stream application comes up again it rereads message m1 and processes the data again (Figure 2b). This again leads to duplicate writes of message m1 in Topic B.
How Apache Kafka Helps
Apache Kafka solves the above problems via exactly-once semantics using the following.
Idempotent Producer
Idempotency on the producer side can be achieved by preventing messages from being processed multiple times. This is achieved by persisting the message only once. With idempotency turned on, each Kafka message gets two things: a producer id (PID) and sequence number (seq). The PID assignment is completely transparent to users and is never exposed by clients.
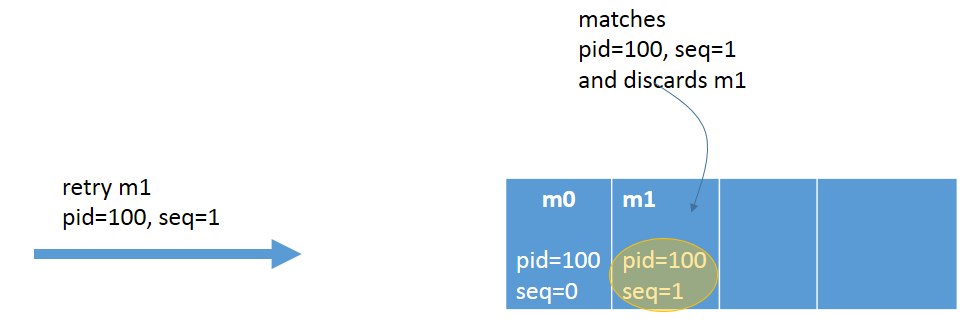
Figure 3: Idempotent Producer
producerProps.put("enable.idempotence", "true");
producerProps.put("transactional.id", "100");In the case of broker failure or client failure, during retry of message send, the topic will only accept messages that have a new unique sequence number and producer id. The broker automatically deduplicates any message(s) sent by this producer, ensuring idempotency. No additional code changes are required.
Transactions Across Partitions
To ensure that each message gets processed exactly-once, transactions can be used. Transactions have an all-or-nothing approach. They ensure that after picking a message, that the message can be transformed and atomically written to multiple topics/partitions along with an offset of the consumed message.
Code Snippet for Atomic Transactions
producer.initTransactions();
try {
producer.beginTxn();
// ... read from input topic
// ... transform
producer.send(rec1); // topic A
producer.send(rec2); // topic B
producer.send(rec3); // topic C
producer.sendOffsetsToTxn(offsetsToCommit, “group-id”);
producer.commitTransaction();
} catch ( Exception e ) {
producer.abortTransaction();
}Apache Kafka v0.11 introduced two components — the Transaction Coordinator and Transaction Log — which maintain the state of the atomic writes.
The below diagram details a high-level flow of events that enables atomic transactions across various partitions:
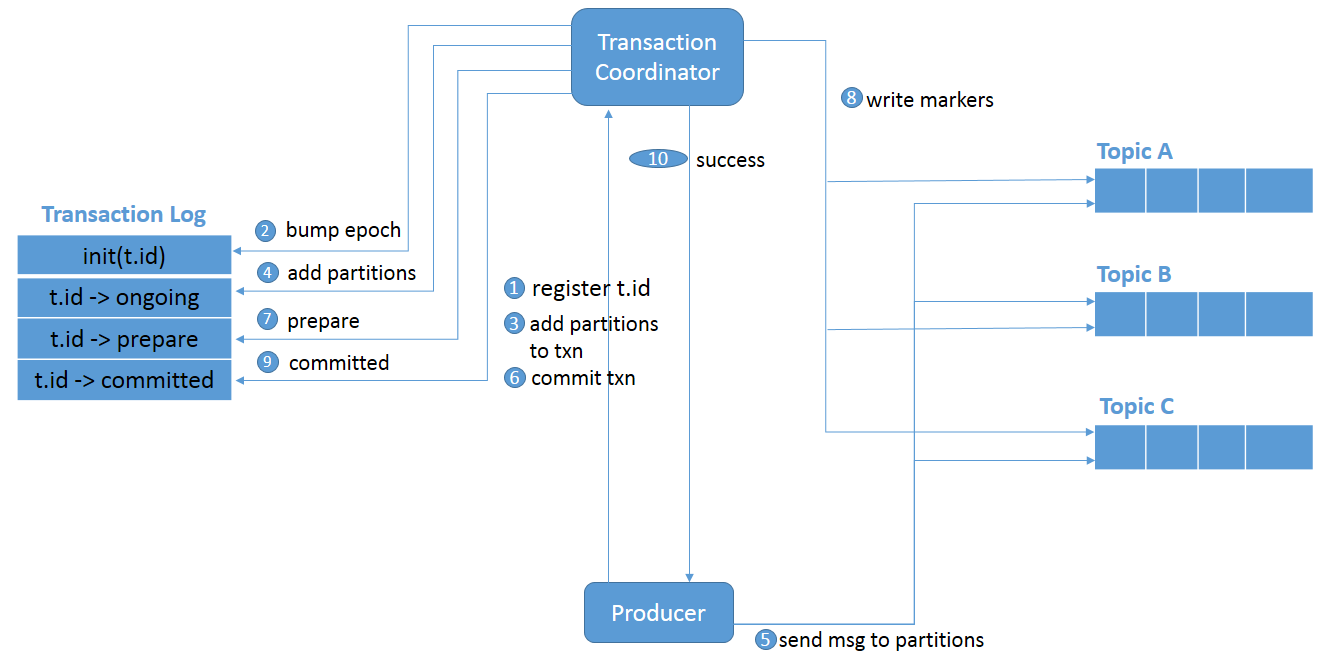
Figure 4: Transactions across a partition.
initTransactions()registers atransactional.idwith the coordinator.- The coordinator bumps up the epoch of the PID so that previous instance of that PID is considered a zombie and fenced off. No writes in the future are accepted from these zombies.
- The producer adds a partition with the coordinator when the producer is about to send data to a partition.
- The transaction coordinator keeps the state of each transaction it owns in memory, and also writes that state to the transaction log (partition information, in this case).
- The producer sends data to the actual partitions.
- The producer initiates a commit transaction and, as a result, the coordinator begins the two-phase commit protocol.
- This is where the first phase begins and the coordinator updates the transaction log to “prepare_commit”.
- The coordinator then begins Phase 2, where it writes the transaction commit markers to the topic-partitions which are part of the transaction.
- After writing the markers, the transaction coordinator marks the transaction as “committed.”
Transactional Consumer
If a consumer is transactional, we should use the isolation level, read_committed. This ensures that it reads only committed data.
The default value of isolation.level is read_uncommitted.
This just a high-level view of how transactions work in Apache Kafka. I'd recommend exploring the docs if you're interested in taking a deeper dive.
Conclusion
In this post, we talked about various delivery guarantee semantics such as at-least-once, at-most-once, and exactly-once. We also talked about why exactly-once is important, the issues in the way of achieving exactly-once, and how Kafka supports it out-of-the-box with a simple configuration and minimal coding.
References
Opinions expressed by DZone contributors are their own.
Comments