Building an LLM-Powered Product to Learn the AI Stack: Part 1
Building a Meal Planning Bot to Deep Dive into LLMs, Product Development, and Cloud Skills. From Data Generation, to Model Training, to Deployment and App building
Join the DZone community and get the full member experience.
Join For FreeForget what you think you know about AI. It's not just for tech giants and universities with deep pockets and armies of engineers and grad students. The power to build useful intelligent systems is within your reach. Thanks to incredible advancements in Large Language Models (LLMs) – like the ones powering Gemini and ChatGPT – you can create AI-driven products that used to require a team of engineers. In this series, we'll demystify the process of building LLM-powered applications, starting with a delicious use case: creating a personalized AI meal planner.
Our Use Case
As an example use case for our journey, we're going to be building a meal-planning app. There’s no shortage of meal plans available online, including those customized for different needs (varying goals, underlying health conditions, etc.). The problem is that it’s often difficult (sometimes impossible) to find guidance tailored specifically for you without hiring a health professional.
Let's consider a realistic example: Sarah, a 32-year-old software engineer, is training for her first marathon. She needs a meal plan that not only meets her increased caloric needs but also accounts for her lactose intolerance and preference for plant-based proteins. Traditional meal planning apps struggle with this level of customization, making this a perfect application of an LLM-powered solution that could easily generate a tailored plan, adjusting macronutrients and suggesting specific foods that meet all of Sarah's requirements.
In this tutorial, we’ll aim to develop a model that can take in a variety of inputs (age, height, weight, activity level, dietary restrictions, personal preferences, etc.) and generate a delicious and nutritious meal plan tailored specifically to the user.
What We’ll Cover
In this article, we’ll walk step by step through the creation of the application. We’ll cover data preparation, the model lifecycle, and finally how to wrap it all together into a usable product.
- In “Part 1: The Right Ingredients: Dataset Creation,” we’ll set the foundation for the quality of our model by constructing a dataset specific to our use case. We’ll discuss why data is so important, the various ways of preparing a dataset, and how to avoid common pitfalls by cleaning your data.
- In “Part 2: Shake and Bake: Training and Deploying Your LLM,” we’ll actually go through the process of using our dataset to train a new model that we can actually interact with. Then, we’ll deploy the model on the cloud.
- In “Part 3: Taste Testing and Fine-tuning: Evaluating Your Meal Planning Bot,” we’ll explore the science of evaluating an LLM and determining whether it meets our goals or not. We’ll set up a rough evaluation that we’ll use to look at our own model.
- In “Part 4: Building an Interface: Presenting Your Masterpiece,” we’ll bring everything together in a working application that we’ll deploy to the cloud. We’ll also discuss how to think about exposing your model to the world and real users
- We’ll close with “Part 5: Beyond the Plate: Conclusion and Next Steps” where we’ll reflect on the experience of putting an LLM-powered application together and putting it out in the world. We’ll also consider some next-step actions we can take from there.
Part 1, The Right Ingredients: Dataset Creation

Software engineering is an excellent metaphor for modeling. We’ll even use it heavily later on in this post. However, when it comes to using data to modify model performance, there’s hardly a better analogy than sculpting. The process of creating a sculpture from solid material is generally rough shaping, followed by successive rounds of refinement, until the material has "converged" to the artist’s vision.
In this way, modeling involves starting with a featureless blob of 1s and 0s and slowly tuning it until it behaves in the way that the modeler intends. Where the sculptor may pick up various chisels, picks, or hammers, however, the modeler’s tool is data.
This particular tool is immensely versatile. It can be used to inject new knowledge and domain understanding into a model by training on subject matter content and examples or by connecting to external systems as in Retrieval Augmented Generation (RAG). It can also be debugged by teaching it to behave in a particular way in specific edge-case scenarios. Inversely, it can be used to "unlearn" certain behaviors that were introduced in prior rounds of training. Data is useful also as an experimentation tool to learn about model behavior or even user behavior.
With these applications and more, it should be clear that data is nearly everything when it comes to modeling. In this section we’ll provide a comprehensive overview of how to create a dataset for your use case, including:
- Understanding how data is used across the model lifecycle
- Defining your requirements
- Creating the dataset
- Preparing the dataset for model training
Data Across the Model Lifecycle
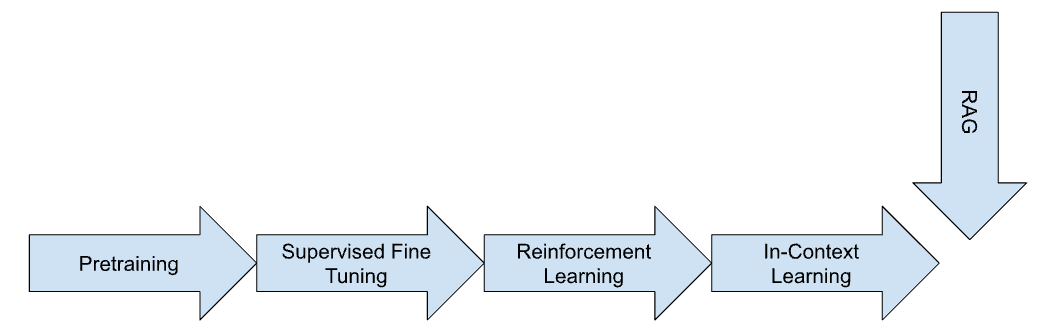
It's tempting to believe that the power of a Large Language Model (LLM) rests solely on its size – the more parameters, the better. But that's only part of the story. While model size plays a role, it's the quality and strategic use of data that truly unlocks an LLM's potential. Think of it this way: you can give a master chef a mountain of ingredients, but without the right recipe and techniques, the result won't be a culinary masterpiece.
Let's explore the key stages where data shapes the mind of an LLM, transforming it from a blank slate into a powerful and versatile AI:
1. Pretraining: Building a Broad Knowledge Base
Pretraining is like sending your LLM to an all-you-can-eat buffet of knowledge. We flood the model with massive datasets of text and code, exposing it to the vastness of the internet and more. This is where the LLM learns fundamental language patterns, absorbs a wide range of concepts, and develops its impressive ability to predict what comes next in a sentence or piece of code.
2. Supervised Fine-Tuning (SFT): Developing Specialized Expertise
Once the LLM has a solid foundation, it's time to hone its skills for specific tasks. In Supervised Fine-Tuning (SFT), we provide the model with carefully curated datasets of prompt-response pairs, guiding it toward the desired behavior. Want your LLM to translate languages? Feed it examples of translated text. Need it to summarize documents? Provide it with well-crafted summaries. SFT is where we mold the LLM from a generalist into a specialist.
3. Reinforcement Learning (RL): Refining Behavior Through Feedback
Reinforcement Learning (RL) is all about feedback and optimization. We present the LLM with choices, observe its decisions, and provide rewards for responses that align with our goals. This iterative process helps the model learn which responses are most favorable, gradually refining its behavior and improving its accuracy.
4. In-Context Learning: Adapting to New Information
Real-world conversations are full of surprises, requiring LLMs to adapt to new information on the fly. In-context learning allows LLMs to process novel information presented within a conversation, even if it wasn't part of their initial training data. This adaptability makes LLMs more dynamic and better equipped to handle the unexpected.
5. Retrieval Augmented Generation (RAG): Expanding Knowledge Horizons
Sometimes, LLMs need access to information that extends beyond their training data. Retrieval Augmented Generation (RAG) bridges this gap by linking the LLM to external databases or knowledge repositories. This enables the model to retrieve up-to-date information, incorporate it into its responses, and provide more comprehensive and insightful answers.
Data: The Key To Unlocking LLM Potential
From its foundational understanding of language to its ability to adapt, learn, and access external knowledge, data shapes every facet of an LLM's capabilities. By strategically utilizing data throughout the model's lifecycle, we unlock its true potential and power the development of truly transformative AI applications.
Defining Your Requirements
You’ve read the theory and understand the importance of data and all the ways it can be used. Are we ready to start creating our dataset? Well, not quite so fast. We need to make sure we understand the problem space and use that to figure out what data we even need.
User Experience
Human-Centered Design is a principle that involves always starting with the user and their need in mind (instead of technology, policy, or other extraneous factors). This can be a very exciting and rewarding activity to better understand target users and how to serve them. Making sure the user experience expectations are clear can also de-risk a modeling project by making sure everyone on the team is attuned to the same definition of success.
Some questions to ask while clarifying the UX include:
- What information do we need from users?
- Will information be provided open-ended or in some structured format?
- How should the model respond to prompts with incomplete information?
- Should our output be structured, or in prose?
- Should we always generate an output, or sometimes ask the user for clarification or more information?
In our case, we’ll stick with open-ended inputs and structured outputs to allow user flexibility while maintaining predictability. We’ll avoid follow-ups to reduce the complexity of our proof of concept.
Various techniques and guides exist elsewhere to assist modeling teams in crafting better requirements through a better understanding of their users.
Entity Relationship Diagrams
ER diagrams show all the entities and relationships involved in a system, and are an extremely powerful tool for understanding systems, use cases, and the like. Painting a picture of our use case, we can use ERDs to hone in on exactly what data we need to capture while making sure we don’t have any blind spots.
The process of creating an ER diagram is quite simple: write out all the entities (nouns) you can think of related to your app. Then write out the relationships between them, and that’s it! In reality, this is done over several rounds, but it creates a rich tool useful for both understanding and communicating your system.
Below is the ER diagram we crafted for RecipeBuddy:
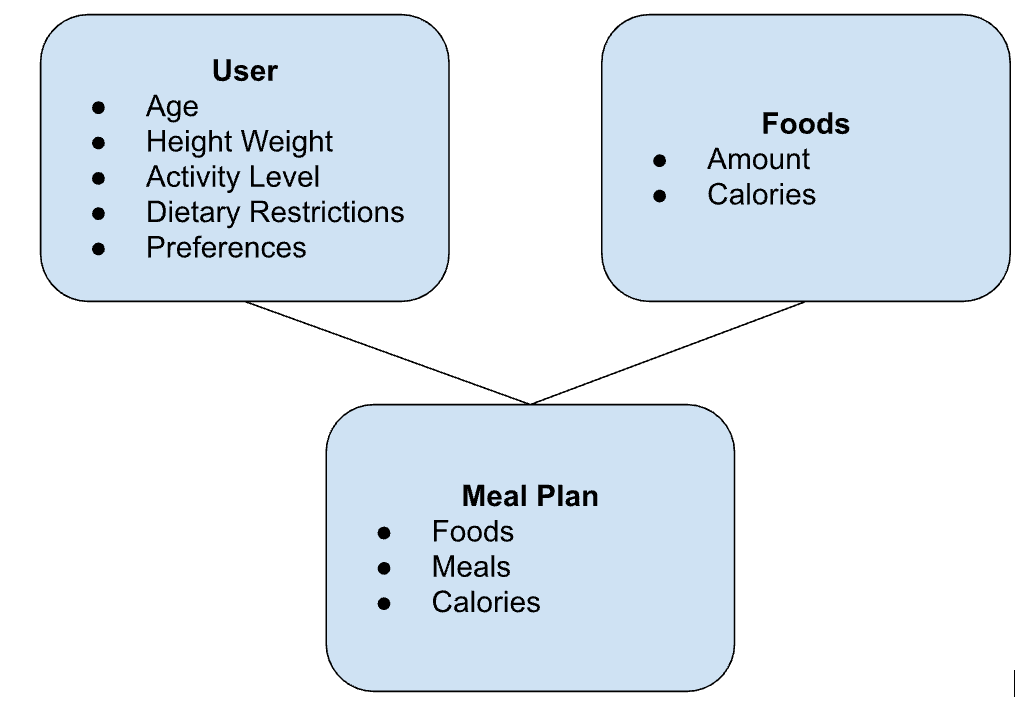
While ours is quite simple, ER Diagrams can get quite complex.
Dataset Attributes
Wait! There’s still more we need to decide on in terms of our dataset. Below are a few considerations, but you’ll have to think deeply about your use case to make sure you cover all the bases for your dataset.
Dataset Type
In this series, we’re sticking to collecting and training on SFT data, but as we covered earlier there are many different types of data to train on.
Input and Output Attributes
The number of variables to consider on an input and to generate on the output are important considerations in modeling, and are an indicator of the complexity of your use case. Great care should be taken in deciding this, as it will impact the diversity of scenarios you’ll need to cover in your data and impact the volume of data you need to collect (which will also impact the required compute and thus cost of training your model).
In our case, let’s use the following inputs:
- Age
- Height
- Weight
- Activity level
- Dietary restrictions
- Personal preferences/Goals
On the output, let’s include a daily meal plan for multiple meals, with specific guidance for each meal:
- Breakfast
- Lunch
- Dinner
- Snack 1
- Snack 2
For each meal:
- Carbs
- Chicken/Fish/Meat
- Whey Protein
- Veggies
- Oil/Fat
Distribution
For each attribute that you are exploring, you should consider the natural diversity of that attribute. Highly diverse attributes require a lot more data to adequately cover than bounded ones. For example, consider creating a dataset that allows users to ask about elements in the periodic table. Simple: there are only so many elements in the periodic table. Now consider an LLM that is trained to identify all possible compounds that are possible when given a list of elements. For any given input, the number of possible outputs is effectively infinite, making this a much more challenging task.
Additionally, note that the more diverse your training data, the better the model will be able to generalize concepts even to examples that it hasn’t seen in the training corpus.
For our proof of concept, we won’t exhaust the distribution of each attribute, instead focusing on a finite number of examples.
Edge Cases
As you define your requirements you may also wish to identify specific edge cases that you wish to avoid.
In our case, let’s avoid answering any questions when the user is pregnant, and instead direct them to seek help from a professional.
We now have a decent spec for our data collection task, except for one thing: how much data do we need? As we described earlier, this is determined by a combination of input/output attributes, distributions of those, and the number of edge cases we want to handle.
One way to quickly get a sense of how many values you need is by considering a simple formula:
- For each input attribute, assess how many "buckets" the values could fall into. Age, for example, might be 0-18, 18-40, 40-60, or 60+ so 4 buckets.
- Across all your attributes, multiply the number of buckets together.
- Add the number of use cases.
This is one way to roughly gauge how much data you need to fully cover your use case and can be a starting point to think about what data you want to exclude or where you don’t want to consider the distribution of a particular attribute.
Creating the Dataset
Now we’re ready to start collecting data! But we have a few options, and we’ll have to decide on a path forward. Essentially, there are two ways we can go about collecting data: using existing data or creating new data.
Using Existing Data
-
Gather first-party data from relevant communities or internal sources.
- Surveys, internal data sources, and crowdsourcing can be used to gather 1st party data.
- Pros: This is likely the closest you can get to "ground truth" data and thus the highest quality data that you might be able to collect.
- Cons: Unless you already have access to a dataset, constructing new datasets in this way can be slow and time-consuming. If there is personally identifiable information in your dataset, you’ll also need to build in assurances to ensure your data providers’ privacy is not compromised.
-
Collect third-party data from public datasets, data providers, or web scraping.
- Existing datasets can be found online, purchased from data brokers, or scraped directly from the web and can be a powerful way to leverage data that has already been collected.
- Pros: This method can be a great way to collect a large volume and diversity of real-world, human-submitted data.
- Cons: It can be difficult to ensure individual privacy when using 3rd party datasets. Additionally, some data collection methods like web scraping can violate some sites’ terms of service.
Creating New Data
Human Generated
You can obviously write your own prompt/response demonstrations to train the model. To scale, you can even partner with data companies (e.g. Surge, Scale) to create human-generated data at scale.
- Pros: Human judgment can be useful to make sure generated data makes sense and can be useful.
- Cons: Having humans write data can be costly and time-intensive. Add in various levels of quality control, and Human Data becomes a complex operation.
Synthetically Generated
You can also simply ask an LLM to generate the data for you.
- Pros: This is a cheap method that can scale to large numbers of datasets very quickly.
- Cons: Models are not able to outperform themselves, so often synthetic data just causes the model to regress to the mean. While this can be addressed by testing different models for the data generation step, it can also introduce hallucinations and errors in your dataset that would be easy for a human to spot, but hard for the LLM to catch.
Hybrid
A powerful technique is to combine human and synthetic data generation by having humans and models successively rewrite each others’ inputs.
- Pros: Takes the best of human and LLM generation. Can possibly outperform the model.
- Cons: While this is a good compromise, it still involves a fair amount of complexity and effort to get right.
Choosing the Right Method for Your Project
Selecting the best data creation method depends on various factors:
- Project scope and timeline
- Available resources (budget, manpower, existing data)
- Required data quality and specificity
- Privacy and legal considerations
For our meal planning bot, we're opting for synthetic data generation. This choice allows us to:
- Quickly generate a large, diverse dataset
- Maintain control over the data distribution and edge cases
- Avoid potential privacy issues associated with real user data
However, keep in mind that in a production environment, a hybrid approach combining synthetic data with carefully vetted real-world examples often yields the best results.
In our case, though, we'll create synthetic data. While a hybrid approach will have worked well here, for the purposes of this tutorial, we want to keep the process simple and inexpensive so you come away with the knowledge and confidence to build a model.
Generating Synthetic Data
Synthetic data generation has become increasingly important in the field of AI, as it allows developers to create large, diverse datasets tailored to their specific use cases. By generating synthetic examples, we can expand our training data, cover a wider range of scenarios, and ultimately improve the performance of our AI models. The NIH, for example, partnered with the industry to create synthetic COVID-19 datasets that were useful in scenario planning and other purposes.
In the context of our AI meal planner, synthetic data generation enables us to create personalized meal plans based on various user attributes and preferences. By constructing a set of rules and templates, we can generate realistic examples that mimic the kind of data our model would encounter in real-world use.
One popular approach to synthetic data generation is called "Rules Based Generation." This method involves creating a structured prompt that outlines the context, input parameters, output format, and examples for the desired data. Let's break down the process of constructing such a prompt:
- Context: Begin by providing a clear description of the task and the role the model should assume. In our case, we want the model to act as an expert dietician creating personalized meal plans.
- Input parameters: Specify the user attributes and preferences that the model should consider when generating meal plans. This can include age, height, weight, activity level, dietary restrictions, and personal goals.
- Output format: Define a consistent structure for the generated meal plans, including the breakdown of macronutrients (carbs, protein, fat), food types, and quantities for each meal and snack.
- Examples: Provide a few representative examples of meal plans that adhere to the specified format and constraints. These examples serve as a template for the model to follow when generating new data points.
Here's an example of a prompt that incorporates these elements:
You are an expert dietician. You prepare detailed meal plans for individuals customized based on their age, weight, activity level and a number of other attributes to optimize their health.
Below, I've provided you with the attributes of a specific user, please generate a meal plan for Breakfast, Lunch, Dinner, and 2 snacks. For each meal, use the following format:
Carbs (what type and how much)
Chicken/Fish/Meat (what type and how much)
Whey Protein (how much)
Veggies (what type and how much)
Oil/Fat (how much)
Include a calculation of total calories per meal, and for the whole day and include that in your response. Do not include any additional information.
{User Attributes}By providing this structured prompt to a language model, we can generate multiple meal plan examples by varying the user attributes. This allows us to create a diverse dataset that covers a wide range of user-profiles and preferences.
However, it's crucial to validate the generated data to ensure its accuracy and appropriateness. Involving domain experts, such as dieticians or nutritionists, can help identify any inconsistencies, biases, or unrealistic examples. They can provide valuable feedback to refine the prompt and improve the quality of the generated meal plans.
Let’s test this prompt on our model. Using the following user attributes:
- Age: 25
- Height: 160cm
- Weight: 55kg
- Activity Level: N/A
- Dietary Restrictions: N/A
- Personal Preferences/Goals: They want to maintain their weight and keep a body fat percentage of 22%.
We get the following response:
Breakfast (400 calories)
Carbs: 50g (1 cup oatmeal)
Chicken/Fish/Meat: None
Whey Protein: 30g
Veggies: 1 cup mixed berries
Oil/Fat: 10g (2 tsp almond butter)
Lunch (450 calories)
Carbs: 60g (1 cup cooked quinoa)
Chicken/Fish/Meat: 120g grilled chicken breast
Whey Protein: None
Veggies: 2 cups mixed greens salad with cucumber, tomatoes
Oil/Fat: 15g (1 tbsp olive oil dressing)
Dinner (550 calories)
Carbs: 70g (1 medium baked sweet potato)
Chicken/Fish/Meat: 150g baked salmon
Whey Protein: None
Veggies: 2 cups steamed broccoli
Oil/Fat: 20g (1 tbsp olive oil + 1/4 avocado)
Snack 1 (150 calories)
Carbs: 20g (1 medium apple)
Chicken/Fish/Meat: None
Whey Protein: None
Veggies: None
Oil/Fat: 10g (2 tbsp peanut butter)
Snack 2 (200 calories)
Carbs: 25g (1 cup nonfat Greek yogurt)
Chicken/Fish/Meat: None
Whey Protein: None
Veggies: None
Oil/Fat: 5g (a small handful of almonds)
Total Daily Calories: 1750This looks great! The formatting has been followed, and the response looks reasonable. Spot-checking some of the meals, the calorie counts seem to check out. At this stage, it will be important to double-check that these values are accurate, and perhaps even check with a domain expert (a dietician or nutritionist in our case) to validate these results.
Now, you may be wondering, why do we need to generate the data, when the model is already quite good at handling this use case? Indeed! This model seems capable of handling this use case. However, let’s make it more complex by adding a personal preference of “Don’t want boring foods”:
Breakfast (350 calories)
Carbs: 1 cup oatmeal (50g)
Chicken/Fish/Meat: 1/2 cup scrambled eggs (2 eggs)
Whey Protein: 1 scoop (25g)
Veggies: 1/2 cup spinach (20g)
Oil/Fat: 1 tsp olive oil (5g)
Lunch (400 calories)
Carbs: 1 cup quinoa (40g)
Chicken/Fish/Meat: 4 oz grilled chicken breast (115g)
Whey Protein: N/A
Veggies: 1 cup mixed greens (30g), 1/2 cup cherry tomatoes (50g), 1/4 cup cucumber (25g)
Oil/Fat: 1 tbsp olive oil (15g)
Snack 1 (150 calories)
Carbs: 1/2 cup fruit salad (100g)
Chicken/Fish/Meat: N/A
Whey Protein: N/A
Veggies: N/A
Oil/Fat: N/A
Snack 2 (200 calories)
Carbs: 1/4 cup trail mix (50g)
Chicken/Fish/Meat: N/A
Whey Protein: N/A
Veggies: N/A
Oil/Fat: N/A
Dinner (500 calories)
Carbs: 1 cup brown rice (50g)
Chicken/Fish/Meat: 4 oz grilled turkey breast (115g)
Whey Protein: N/A
Veggies: 1 cup broccoli (100g), 1/2 cup bell peppers (50g)
Oil/Fat: 1 tbsp olive oil (15g)
Total Daily Calories: 1600 caloriesHmm.. this response isn’t as great as the first one. We will have eggs for breakfast, chicken breast for lunch, and so on. We can use this example and other "challenging" scenarios to construct our dataset. For this example, let’s spice it up:
Breakfast (350 calories)
Carbs: 1 cup cassava (50g)
Chicken/Fish/Meat: 1/2 cup (80g) Scrambled Eggs with 1/2 cup chopped spinach
Whey Protein: 1 scoop (25g)
Veggies: 1/2 cup spinach (20g)
Oil/Fat: 1 tsp olive oil (5g)
Lunch (400 calories)
Carbs: 1 cup quinoa (40g)
Chicken/Fish/Meat: 4 oz (115g) Ground Turkey (can be seasoned and formed into patties)
Whey Protein: N/A
Veggies: 1 cup mixed greens (30g), 1/2 cup cherry tomatoes (50g), 1/4 cup cucumber (25g)
Oil/Fat: 1 tbsp olive oil (15g)
Snack 1 (150 calories)
Carbs: 1/2 cup fruit salad (100g)
Chicken/Fish/Meat: N/A
Whey Protein: N/A
Veggies: N/A
Oil/Fat: N/A
Snack 2 (200 calories)
Carbs: 1/2 cup Mango cubes (75g)
Chicken/Fish/Meat: N/A
Whey Protein: N/A
Veggies: N/A
Oil/Fat: N/A
Dinner (500 calories)
Carbs: 1 cup brown rice (50g)
Chicken/Fish/Meat: 4 oz (115g) Tofu (can be pan-fried or baked)
Whey Protein: N/A
Veggies: 1 cup broccoli (100g), 1/2 cup bell peppers (50g)
Oil/Fat: 1 tbsp olive oil (15g)
Total Daily Calories: 1600 caloriesGreat - that’s better, a little more interesting!
As you construct your dataset, you may find your model similarly capable. But as you keep testing different scenarios, you’ll undoubtedly find edge cases where the model struggles, and where you can help it perform better.
Now that we have a bunch of examples, we can start to prepare data. Before we do that, however, we need to construct a prompt for each user scenario. Above, we simply injected some user attributes into our prompt, but to make it more realistic we’ll need to construct these as sentences like:
I'm 25, female, about 160cm and 120 pounds. I want to stay the same at around 22% BF.
That’s it! Now we have our dataset. Let’s move to Google Sheets to start to get it ready for training.
Preparing Data for Training

Exact data preparation steps can depend on a number of factors, but it is generally useful to put the data in a form that can be easily reviewed and manipulated by a broad audience. Spreadsheet software like Google Sheets is a natural choice for this as most people are familiar with it, and it lends itself well to reviewing individual "records" or "examples" of training data.
Setting up the data is quite simple. First, we need two columns: "Prompt" and "Response." Each row should include the respective values in those columns based on the dataset we constructed previously. Now that we have it there, it’s a good time to clean the data.
Data Cleaning
Before we get our data ready for training, we need to make sure it's clean of inaccuracies, inconsistencies, errors, and other issues that could get in the way of our end goal.
There are a few key things to watch out for:
Missing Values
Is your dataset complete, or are there examples with missing fields? You'll need to decide whether you want to toss out those examples completely, or if you want to try to fill them in (also called imputation).
Formatting Issues
Is text capitalized appropriately? Are values in the right units? Are there any structural issues like mismatched brackets? All of these need to be resolved to ensure consistency.
Outliers, Irrelevant, and Inaccurate Data
Is there any data that is so far outside the norm that it could mislead the model? This data should be removed. Also, watch out for any data that is irrelevant to your use case and remove that as well. Collaborating with a domain expert can be a useful strategy to filter out datasets that don’t belong.
By carefully cleaning and preprocessing your data, you're setting yourself up for success in training a high-performing model. It may not be the most glamorous part of the process, but it's absolutely essential. Time investment at this stage is critical for production-grade models and will make later steps much easier.
Additional Best Practices for Data Cleaning
- Automate where possible: Use automated tools and scripts to handle repetitive tasks like format standardization and missing value imputation.
- Iterate and validate: Data cleaning is not a one-time task. Continuously iterate and validate your cleaning methods to ensure ongoing data quality.
- Document everything: Maintain detailed documentation of all data cleaning steps, including decisions made and methods used. This will help in debugging and refining your process.
- Leverage domain knowledge: Collaborate with domain experts to ensure your data cleaning process is aligned with real-world requirements and nuances.
Wrapping Up

Creating a high-quality dataset is essential for training an effective meal-planning LLM. By understanding the types of data, defining clear requirements, employing appropriate collection strategies, cleaning and preprocessing your data, augmenting your dataset, and iteratively refining it, you can build a model that generates personalized, diverse, and relevant meal plans.
Remember, data preparation is an ongoing process. As you deploy your model and gather user feedback, continue to enhance your dataset and retrain your model to unlock new levels of performance. With a well-crafted dataset, you're well on your way to creating an AI meal planner that will delight and assist users in their culinary adventures!
Looking Ahead: The Future of LLMs in Personalized Services
As LLM technology continues to evolve, we can expect to see increasingly sophisticated and personalized AI services. Future iterations of our meal planning bot might:
- Integrate with smart home devices to consider available ingredients
- Adapt recommendations based on real-time health data from wearables
- Collaborate with other AI systems to provide holistic wellness plans
By mastering the fundamentals we've covered in this series, you'll be well-positioned to leverage these exciting developments in your own projects and applications.
Opinions expressed by DZone contributors are their own.
Comments