Implement RAG With PGVector, LangChain4j, and Ollama
Apply vector search and RAG experiments to enhance query results and optimize data storage for text embeddings, specifically with Bruce Springsteen's album data.
Join the DZone community and get the full member experience.
Join For FreeIn this blog, you will learn how to implement retrieval-augmented generation (RAG) using PGVector, LangChain4j, and Ollama. This implementation allows you to ask questions about your documents using natural language. Enjoy!
Introduction
In a previous blog, RAG was implemented using Weaviate, LangChain4j, and LocalAI. Now, one year later, it is interesting to find out how this has evolved. E.g.:
- Can you use PGVector, an extension of PostgreSQL, as a vector database?
- Is it possible to use LangChain4j for embedding and storing the data in a vector database? Last year, it was not easy to do so, or at least it was limited in functionality. Therefore, the Weaviate Java client library was used.
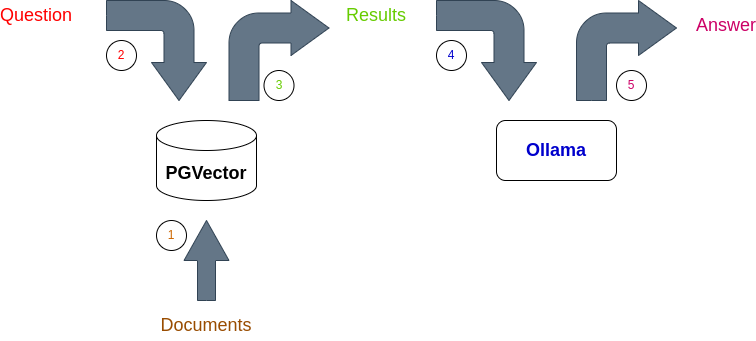
Using RAG, you can ask questions about your documents. But before you dive into the details, let’s explain the basics of RAG:
- Documents are embedded (transformed to numbers in a vector) and stored in PGVector;
- The question is embedded, and a semantic search is performed using PGVector;
- PGVector returns the semantic search results;
- The result is added to a prompt and fed to Ollama, which runs an LLM;
- The LLM returns the answer to the question.
The source documents are some Wikipedia documents containing data on songs and albums of Bruce Springsteen. The documents are converted to markdown for easy processing. The interesting part of these documents is that they contain facts and are mainly in a table format.
The sources used in this blog can be found on GitHub.
Prerequisites
The prerequisites for this blog are:
- Basic knowledge of embedding and vector stores;
- Basic Java knowledge, Java 21 is used;
- Basic knowledge of Docker;
- Basic knowledge of LangChain4j (see RAG and the langchain4j-examples for more information);
- Basic knowledge of Large Language Models;
- If you want to learn more about RAG, read this blog.
Install Ollama
Ollama is used as an inference engine. Installation instructions can be found on the Ollama website.
Download the llama3.2:3b model which is used as LLM.
$ ollama pull llama3.2:3bVector Search
One of the conclusions from previous blogs was that it really matters how you embed documents. Since you are dealing with tables, it is important to transform the data in order that a similarity search will return the correct results. You cannot do simple chunk splitting because important information (which cell contains which data) is lost. With simple chunk splitting, the text might be split somewhere in the middle of a row, and a similarity search will not return the correct results, especially when you want information about the split row. Therefore, the markdown tables are converted to JSON objects for each row. A markdown document looks as follows:
| Title | US | AUS | CAN | GER | IRE | NLD | NZ | NOR | SWE | UK |
|----------------------------------|----|-----|-----|-----|-----|-----|----|-----|-----|----|
| Greatest Hits | 1 | 1 | 1 | 1 | 1 | 2 | 1 | 1 | 1 | 1 |
| Tracks | 27 | 97 | — | 63 | — | 36 | — | 4 | 11 | 50 |
| 18 Tracks | 64 | 98 | 58 | 8 | 20 | 69 | — | 2 | 1 | 23 |
| The Essential Bruce Springsteen | 14 | 41 | — | — | 5 | 22 | — | 4 | 2 | 15 |
| Greatest Hits | 43 | 17 | 21 | 25 | 2 | 4 | 3 | 3 | 1 | 3 |
| The Promise | 16 | 22 | 27 | 1 | 4 | 4 | 30 | 1 | 1 | 7 |
| Collection: 1973–2012 | — | 6 | — | 23 | 2 | 78 | 19 | 1 | 6 | — |
| Chapter and Verse | 5 | 2 | 21 | 4 | 2 | 5 | 4 | 3 | 2 | 2 |The first row contains the table headers. These are used as keys in the JSON object. Each row containing data is converted to a JSON object. The first row becomes:
{
"Title" : "Greatest Hits",
"US" : "1",
"AUS" : "1",
"CAN" : "1",
"GER" : "1",
"IRE" : "1",
"NLD" : "2",
"NZ" : "1",
"NOR" : "1",
"SWE" : "1",
"UK" : "1"
}The data in the documents is converted to JSON objects and is stored in a PostgreSQL container with the PGVector extension. Testcontainers are used to start the PostgreSQL docker container. As embedding model AllMinimumL6V2EmbeddingModel is used and an EmbeddingStore instance is created. After all processing is done, the container is stopped.
public static void main(String[] args) throws JsonProcessingException {
DockerImageName dockerImageName = DockerImageName.parse("pgvector/pgvector:pg16");
try (PostgreSQLContainer<?> postgreSQLContainer = new PostgreSQLContainer<>(dockerImageName)) {
postgreSQLContainer.start();
EmbeddingModel embeddingModel = new AllMiniLmL6V2EmbeddingModel();
EmbeddingStore<TextSegment> embeddingStore = PgVectorEmbeddingStore.builder()
.host(postgreSQLContainer.getHost())
.port(postgreSQLContainer.getFirstMappedPort())
.database(postgreSQLContainer.getDatabaseName())
.user(postgreSQLContainer.getUsername())
.password(postgreSQLContainer.getPassword())
.table("test")
.dimension(embeddingModel.dimension())
.build();
...
postgreSQLContainer.stop();
}
}In order to embed a JSON object, a TextSegment is created, which is embedded using the embeddingModel. Finally, the segment and its vectorized representation are stored in the embeddingStore. See the VectorSearch class for the full source code.
TextSegment segment = TextSegment.from(jsonString);
Embedding embedding = embeddingModel.embed(segment).content();
embeddingStore.add(embedding, segment);Now, you can ask questions and use a similarity search. First, the question is vectorized and by means of an EmbeddingSearchRequest, a search is performed in the embeddingStore. Only one result is taken into account in this example. Finally, the question, the score, and the segment are printed.
Embedding queryEmbedding = embeddingModel.embed(question).content();
EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(1)
.build();
List<EmbeddingMatch<TextSegment>> relevant = embeddingStore.search(embeddingSearchRequest).matches();
EmbeddingMatch<TextSegment> embeddingMatch = relevant.getFirst();
System.out.println("Question: " + question);
System.out.println(embeddingMatch.score());
System.out.println(embeddingMatch.embedded().text());
System.out.println();The following questions are asked, and the correct answers are mentioned below.
- on which album was “adam raised a cain” originally released?
The answer is “Darkness on the Edge of Town”. - what is the highest chart position of “Greetings from Asbury Park, N.J.” in the US?
This answer is #60. - what is the highest chart position of the album “tracks” in canada?
The album did not have a chart position in Canada. - in which year was “Highway Patrolman” released?
The answer is 1982. - who produced “all or nothin’ at all”?
The answer is Jon Landau, Chuck Plotkin, Bruce Springsteen, and Roy Bittan.
Let’s evaluate the response. As you can see, all segments returned contain the answer to the question, except for question 3. This is rather a tricky one because an album, 18 Tracks, exists and also an album Tracks.
Question: on which album was "adam raised a cain" originally released?
0.7841782996548281
{"Song":"\"Adam Raised a Cain\"","writers":"Bruce Springsteen","OriginalRelease":"Darkness on the Edge of Town","Producers":"Jon Landau Bruce Springsteen Steven Van Zandt (assistant)","year":"1978"}
Question: what is the highest chart position of "Greetings from Asbury Park, N.J." in the US?
0.8388364714037442
{"Title":"Greetings from Asbury Park,N.J.","US":"60","AUS":"71","CAN":"—","GER":"—","IRE":"—","NLD":"—","NZ":"—","NOR":"—","SWE":"35","UK":"41"}
Question: what is the highest chart position of the album "tracks" in canada?
0.736735459979889
{"Title":"18 Tracks","US":"64","AUS":"98","CAN":"58","GER":"8","IRE":"20","NLD":"69","NZ":"—","NOR":"2","SWE":"1","UK":"23"}
Question: in which year was "Highway Patrolman" released?
0.7439413226912829
{"Song":"\"Highway Patrolman\"","writers":"Bruce Springsteen","OriginalRelease":"Nebraska","Producers":"Bruce Springsteen","year":"1982"}
Question: who produced "all or nothin' at all?"
0.7836363742568315
{"Song":"\"All or Nothin' at All\"","writers":"Bruce Springsteen","OriginalRelease":"Human Touch","Producers":"Jon Landau Chuck Plotkin Bruce Springsteen Roy Bittan","year":"1992"}Vector Search Multiple Results
One thing you can do, is to increase the number of results the database may return. Let’s see what happens if it is increased to 5 and whether the correct segment is present in these results. See the VectorSearchMultipleResults class for the full source code.
Embedding queryEmbedding = embeddingModel.embed(question).content();
EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(5)
.build();
List<EmbeddingMatch<TextSegment>> relevant = embeddingStore.search(embeddingSearchRequest).matches();
System.out.println("Question: " + question);
for (EmbeddingMatch<TextSegment> match : relevant) {
System.out.println(match.score());
System.out.println(match.embedded().text());
}
System.out.println();The result does contain the correct segment but is only scored as third. It might be that the similarity search values a value for the chart position higher than no value. But still, even then Greatest Hits scores higher, which appears to be odd.
Question: what is the highest chart position of the album "tracks" in canada?
0.736735459979889
{"Title":"18 Tracks","US":"64","AUS":"98","CAN":"58","GER":"8","IRE":"20","NLD":"69","NZ":"—","NOR":"2","SWE":"1","UK":"23"}
0.7238233623083565
{"Title":"Greatest Hits","US":"43","AUS":"17","CAN":"21","GER":"25","IRE":"2","NLD":"4","NZ":"3","NOR":"3","SWE":"1","UK":"3"}
0.7166994159547221
{"Title":"Tracks","US":"27","AUS":"97","CAN":"—","GER":"63","IRE":"—","NLD":"36","NZ":"—","NOR":"4","SWE":"11","UK":"50"}
0.7103144980601677
{"Title":"Greatest Hits","US":"1","AUS":"1","CAN":"1","GER":"1","IRE":"1","NLD":"2","NZ":"1","NOR":"1","SWE":"1","UK":"1"}
0.7077486861345079
{"Song":"\"Somewhere North of Nashville\"","writers":"Bruce Springsteen","OriginalRelease":"Western Stars","Producers":"Ron Aniello Bruce Springsteen","year":"2019"}RAG
Now that you know the results of the vector search, you can feed the results to an LLM. In the first experiment, the vector search returning one result is used.
Ollama is used as an inference engine with llama3.2 as a model. The temperature is set to 0.0 because the LLM needs to be factual and must not be too creative. Also, a prompt is constructed instructing the LLM to use the data provided to create the answer. See the Rag class for the full source code.
Embedding queryEmbedding = embeddingModel.embed(question).content();
EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(1)
.build();
List<EmbeddingMatch<TextSegment>> relevant = embeddingStore.search(embeddingSearchRequest).matches();
EmbeddingMatch<TextSegment> embeddingMatch = relevant.getFirst();
ChatLanguageModel model = OllamaChatModel.builder()
.baseUrl("http://localhost:11434/")
.modelName("llama3.2:3b")
.temperature(0.0)
.build();
String answer = model.generate(createPrompt(question, embeddingMatch.embedded().text()));
System.out.println("Question: " + question);
System.out.println(answer);
System.out.println();The prompt is created as follows:
private static String createPrompt(String question, String inputData) {
return "Answer the following question: " + question + "\n" +
"Use the following data to answer the question: " + inputData;
}The result is not surprising; all questions were answered correctly, except for question 3.
Question: on which album was "adam raised a cain" originally released?
"Adam Raised a Cain" was originally released on the album "Darkness on the Edge of Town".
Question: what is the highest chart position of "Greetings from Asbury Park, N.J." in the US?
The highest chart position of "Greetings from Asbury Park, N.J." in the US is 60.
Question: what is the highest chart position of the album "tracks" in canada?
The highest chart position of the album "Tracks" in Canada is 58.
Question: in which year was "Highway Patrolman" released?
The song "Highway Patrolman" was originally released in 1982, as part of Bruce Springsteen's album "Nebraska".
Question: who produced "all or nothin' at all?"
The producers of "All or Nothin' at All" are Jon Landau, Chuck Plotkin, Bruce Springsteen, and Roy Bittan.RAG Multiple Results
What happens when you feed the five most similar results returned by the vector database to the LLM? See the RagMultipleResults class for the full source code.
Embedding queryEmbedding = embeddingModel.embed(question).content();
EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.maxResults(5)
.build();
List<EmbeddingMatch<TextSegment>> relevant = embeddingStore.search(embeddingSearchRequest).matches();
StringBuilder inputData = new StringBuilder();
for (EmbeddingMatch<TextSegment> match : relevant) {
inputData.append(match.embedded().text()).append("\n");
}
ChatLanguageModel model = OllamaChatModel.builder()
.baseUrl("http://localhost:11434/")
.modelName("llama3.2:3b")
.temperature(0.0)
.build();
String answer = model.generate(createPrompt(question, inputData.toString()));
System.out.println("Question: " + question);
System.out.println(answer);
System.out.println();The results are all correct.
Question: on which album was "adam raised a cain" originally released?
"Adam Raised a Cain" was originally released on the album "Darkness on the Edge of Town".
Question: what is the highest chart position of "Greetings from Asbury Park, N.J." in the US?
The highest chart position of "Greetings from Asbury Park, N.J." in the US is 60.
Question: what is the highest chart position of the album "tracks" in canada?
The highest chart position of the album "Tracks" in Canada is not explicitly stated in the provided data. However, we can see that the album's Canadian chart position is marked as "--", which means it did not chart at all.
Question: in which year was "Highway Patrolman" released?
Based on the provided data, "Highway Patrolman" was released in 1982.
Question: who produced "all or nothin' at all?"
The producers of "All or Nothin' at All" are Jon Landau, Chuck Plotkin, Bruce Springsteen, and Roy Bittan.Metadata
One way to improve results is to add metadata to the segment. You can, for example, add the document metadata to each segment. This can help to improve the results. See the VectorSearchWithMetadataFiltering class for the full source code.
Change the following line when embedding the data:
TextSegment segment = TextSegment.from(jsonString);Into:
TextSegment segment = TextSegment.from(jsonString, document.metadata());The advantage of this approach is that you are now able to apply metadata filtering during the vector search in order to finetune the search results.
EmbeddingSearchRequest embeddingSearchRequest = EmbeddingSearchRequest.builder()
.queryEmbedding(queryEmbedding)
.filter(metadataKey("file_name").isEqualTo("bruce_springsteen_discography_compilation_albums.md"))
.maxResults(5)
.build();When you run this for question 3, you will notice now that only segments from the compilation album markdown are used.
Question: what is the highest chart position of the album "tracks" in canada?
0.736735459979889
{"Title":"18 Tracks","US":"64","AUS":"98","CAN":"58","GER":"8","IRE":"20","NLD":"69","NZ":"—","NOR":"2","SWE":"1","UK":"23"}
Metadata { metadata = {absolute_directory_path=/home/<project dir>/mypgvectorplanet/target/classes/markdown-files, file_name=bruce_springsteen_discography_compilation_albums.md} }
0.7238233623083565
{"Title":"Greatest Hits","US":"43","AUS":"17","CAN":"21","GER":"25","IRE":"2","NLD":"4","NZ":"3","NOR":"3","SWE":"1","UK":"3"}
Metadata { metadata = {absolute_directory_path=/home/<project dir>/mypgvectorplanet/target/classes/markdown-files, file_name=bruce_springsteen_discography_compilation_albums.md} }
0.7166994159547221
{"Title":"Tracks","US":"27","AUS":"97","CAN":"—","GER":"63","IRE":"—","NLD":"36","NZ":"—","NOR":"4","SWE":"11","UK":"50"}
Metadata { metadata = {absolute_directory_path=/home/<project dir>/mypgvectorplanet/target/classes/markdown-files, file_name=bruce_springsteen_discography_compilation_albums.md} }
0.7103144980601677
{"Title":"Greatest Hits","US":"1","AUS":"1","CAN":"1","GER":"1","IRE":"1","NLD":"2","NZ":"1","NOR":"1","SWE":"1","UK":"1"}
Metadata { metadata = {absolute_directory_path=/home/<project dir>/mypgvectorplanet/target/classes/markdown-files, file_name=bruce_springsteen_discography_compilation_albums.md} }
0.6745894371484418
{"Title":"The Essential Bruce Springsteen","US":"14","AUS":"41","CAN":"—","GER":"—","IRE":"5","NLD":"22","NZ":"—","NOR":"4","SWE":"2","UK":"15"}
Metadata { metadata = {absolute_directory_path=/home/<project dir>/mypgvectorplanet/target/classes/markdown-files, file_name=bruce_springsteen_discography_compilation_albums.md} }Data Storage
How is the data actually stored in the PostgreSQL database? Run one of the examples and set a breakpoint after embedding the data.
List the docker containers. Note that the name of the container changes on each run.
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
935b4a5179cd pgvector/pgvector:pg16 "docker-entrypoint.s…" 23 seconds ago Up 22 seconds 0.0.0.0:32779->5432/tcp, [::]:32779->5432/tcp sad_volhardOpen a shell in the container.
$ docker exec -it -u postgres sad_volhard shConnect to the database.
$ psql -U test -d test
psql (16.4 (Debian 16.4-1.pgdg120+2))
Type "help" for help.
test=#Show the definition of the table. It contains an embedding UUID, the embedding itself, the text that is embedded, and metadata.
test=# \d test
Table "public.test"
Column | Type | Collation | Nullable | Default
--------------+-------------+-----------+----------+---------
embedding_id | uuid | | not null |
embedding | vector(384) | | |
text | text | | |
metadata | json | | |
Indexes:
"test_pkey" PRIMARY KEY, btree (embedding_id)Show the first record.
test=# select * from test limit 1;
embedding_id: 2a521c07-bd3b-4782-b8b2-baed8c6f4dce
embedding: [0.031580668,0.025465991,-0.016009035,-0.03641769,-0.03277967,0.07708967,0.0049167797,-0.017779656,0.032219637,0.016496945,-0.015907818,-0.032288495,0.011790586,0.019472498,0.047984418,0.021774884,-0.07559271,0.0048014047,0.034546472,-0.0754522,0.054632142,0.08044497,0.043900292,-0.030095503,0.039856017,0.0064944737,-0.0838084,0.11659679,0.0416057,-0.02382398,0.015198789,0.01789327,0.04178193,0.028759629,0.013529448,-0.068671174,-0.02634477,-0.016564855,0.03075312,0.06846695,0.03440958,-0.000779049,-0.009776263,-0.069745004,-0.026479807,-0.030579884,-0.09824913,0.020243285,-0.03176824,0.15366423,-0.009050815,-0.065079086,-0.012377856,0.005015173,0.028711183,-0.0033459738,-0.07547169,0.016946577,0.014433928,-0.051508006,-0.04088206,-0.100927375,-0.03750696,-0.042864844,0.02601579,-0.057313368,-0.0429479,0.085582055,-0.07071776,0.034811858,0.0059119104,-0.019201059,-0.000239234,0.020917239,-0.07460449,0.011232539,-0.017610366,-0.059181493,0.00046711977,0.020851146,-0.031658202,-0.07222668,-0.020658273,-0.03450465,0.037320722,-0.0057420176,0.039115768,-0.018133044,-0.06748689,-0.040757537,-0.12135425,-0.06566838,0.08057903,0.049271736,-0.040129874,0.03771298,0.047368526,-0.027895676,-0.056494657,0.063976325,0.054615676,0.0362761,0.02549008,-0.00862227,-0.04929304,-0.0442364,0.014661456,0.06382159,0.0018913681,-0.055254184,-0.043929096,0.07987971,-0.047979902,-0.055738557,-0.0710592,-0.10678075,0.046401016,0.034831375,0.054119688,-0.010822127,0.03299195,-0.0012803,-0.05551498,-0.015811473,-0.0766642,-0.022122094,0.04961166,6.362277e-34,0.0734883,0.010004916,-0.00015849665,-0.07844014,0.069890395,-0.07603606,-0.07320543,0.055500202,-0.08056406,-0.05180666,0.029946493,0.012670085,0.055201706,-0.02752944,0.016061392,-0.024182165,0.09436901,0.0046051466,-0.030688351,-0.032018702,-0.045588344,0.034579847,0.059219267,-0.025174154,-0.08302744,-0.040386423,0.0109107345,-0.06324193,-0.040996548,-0.014875631,0.02477869,-0.041948818,-0.05807179,0.010182427,0.010441146,1.7379101e-05,-0.034673497,0.051027965,-0.020023406,-0.07213866,-0.025476877,-0.012682968,-0.09789578,-0.02525169,0.021936696,0.0690436,-0.03709981,0.033103526,0.04289114,0.05511609,-0.034437336,0.017110528,-0.13792631,0.016633974,0.057983007,-0.02227446,0.0015781859,0.044756018,0.039085492,-0.09198131,0.0043225107,0.0073941755,0.10624841,-0.024850441,0.030708384,0.047979143,0.0503047,-0.073406175,-0.022290595,0.039676473,-0.0048347786,0.023215653,0.04289053,0.009007128,-0.008839939,-0.0036836902,0.0627312,-0.005359143,0.0574101,-0.012791466,-0.068877086,-0.01685796,-0.051932294,0.030438237,0.022535512,0.05672693,0.00075185846,-0.09162834,-0.015800955,-0.03693263,-0.06330868,0.0072504366,-0.024390949,-0.13304476,-0.043171473,-3.0373948e-34,0.062630005,-0.0059167943,0.023932042,0.024031257,-2.8605447e-05,-0.028122798,0.027845828,0.13297395,0.06100742,0.024719125,0.04546722,-0.044677198,-0.009789706,-0.05431539,0.03625417,-0.009217321,0.022071104,0.024681453,0.06462466,-0.0042757415,-0.016348455,0.024637435,-0.021333074,0.11343283,0.016080225,-0.023082549,0.04845112,-0.014750015,-0.063786834,-0.04490657,0.047926534,0.011185312,-0.068396,0.035970278,-0.09511442,-0.007400455,0.054118715,0.027551556,-0.02155952,0.11431438,-0.031101938,0.022958204,-0.040047627,0.07653802,-0.0025571354,-0.081675,-0.040774357,0.10233648,-0.031685073,0.008287349,0.05600707,0.006656253,-0.090433605,-0.027457016,-0.00010519994,-0.032621328,0.06276871,-0.1333518,-0.045015067,-0.010948209,-0.013326796,0.049927533,-0.04802837,0.028979836,0.06426821,-0.025765203,-0.029973798,0.01665238,-0.048212696,0.005720242,-0.047327776,-0.012063464,0.05575918,-0.06967655,-0.039623305,0.0010224425,0.013601769,0.040315967,0.021472903,-0.07262945,-0.028405936,0.08512926,-0.03804227,0.0990085,0.026543887,0.0982276,0.030582793,-0.004492244,0.01448816,0.032104336,0.03698508,0.019581292,0.06318792,0.044744905,0.021427112,-5.722532e-08,-0.1404406,-0.010890114,-0.086738154,0.070032395,0.032182276,0.13537027,0.037350785,-0.015098591,0.06595552,-0.008542003,0.06819102,-0.019816462,-0.094941884,-0.01044144,-0.015667865,0.0159543,-0.01269281,0.13172272,-0.014363801,0.015799483,0.049897622,0.08149077,0.08710677,-0.04054212,0.028655179,0.050915714,-0.060408358,-0.0065973154,-0.023789834,-0.004980779,0.030729841,0.013183783,0.040029906,-0.047540393,0.011607898,-0.055668585,0.06787933,0.029463125,-0.063044846,0.015595582,0.034777697,0.06203875,-0.09255133,0.060915634,-0.035187747,-0.06298803,0.009227322,0.047384907,0.04571878,-0.03436542,0.0269654,-0.08935912,0.029580131,-0.018385677,-0.039207824,0.05525895,0.03421194,0.012937598,-0.006291442,0.006253845,0.18092574,-0.060508866,0.023679037,0.026190475]
text: {"Title":"Greatest Hits","US":"1","AUS":"1","CAN":"1","GER":"1","IRE":"1","NLD":"2","NZ":"1","NOR":"1","SWE":"1","UK":"1"}
metadata: { }Conclusion
In this blog, you learned how you can implement RAG using PGVector, LangChain4j, and Ollama. It is quite easy to set up RAG this way. The way data is prepared and stored in a vector database has a great influence on the results. Therefore, you should take the time to think about how you embed your documents and verify that a semantic search returns the correct data.
Published at DZone with permission of Gunter Rotsaert, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments