How We Trained a Neural Network to Generate Shadows in Photos: Part 1
A step-by-step guide on how to train a generative adversarial network (GAN) to generate shadows in images.
Join the DZone community and get the full member experience.
Join For FreeIn this series, Artem Nazarenko, Computer Vision Engineer at Everypixel, shows you how you can implement the architecture of a neural network. The first part will be about the working principles of GAN and methods of collecting datasets for training.
GAN development is not as difficult as it seems at first glance. In the scientific world, there are many articles and publications on generative adversarial networks. I chose ARShadowGAN as a reference article. It is a publication about a GAN that generates realistic shadows for a new object inserted into the image. Since I will deviate from the original architecture, I will call my solution ARShadowGAN-like.

Here is what you will need:
- Browser
- Experience in Python
- Google account to work in the Google Colaboratory environment
Description of the Generative Adversarial Network
The generative adversarial network consists of two networks:
- A generator that synthesizes an image from the input noise (our generator will create a shadow by taking a shadow-free image and a mask of the inserted object);
- A discriminator that distinguishes the real image from the fake one received from the generator.

ARShadowGAN-like scheme
The generator and the discriminator work together. The generator becomes more skilled at synthesizing shadows and fooling the discriminator. The discriminator learns to give a qualitative answer to the question of whether the image is real.
The main task is to train the generator to create a high-quality shadow. The discriminator is required only for better training, and it will not participate in further stages (testing, inference, production, etc.).
The ARShadowGAN-like generator consists of two main blocks: attention and shadow generation (SG).
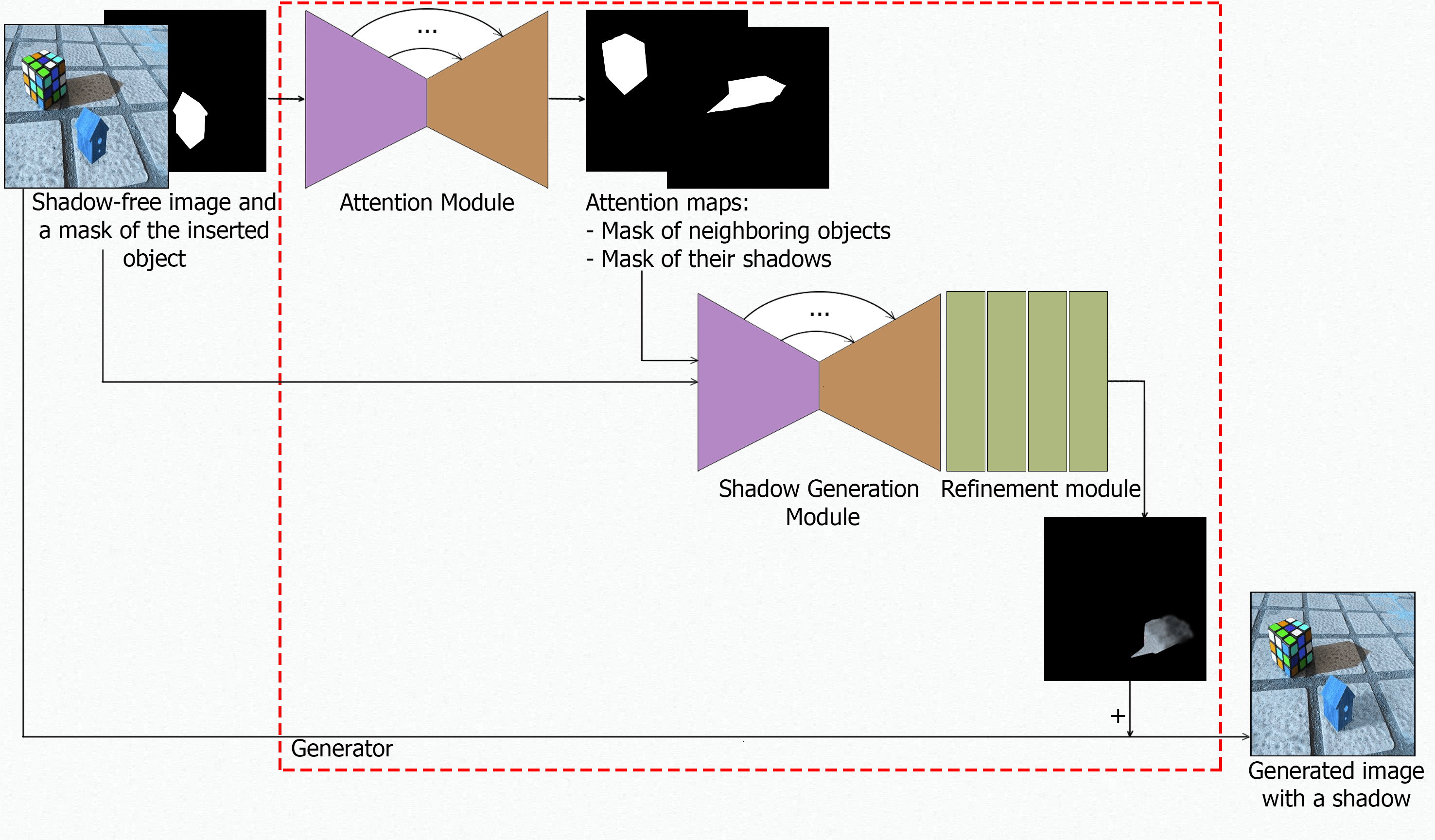
One of the tricks for improving the quality of the outcome is using the attention mechanism. Attention maps are, in other words, segmentation masks consisting of zeros (black) and ones (white, area of interest).
Attention block generates so-called attention maps — maps of those areas of the image that the network needs to focus on. In this case the mask of neighboring objects (occluders) and the mask of their shadows will act as such maps. Therefore, we seem to instruct the network on how to generate a shadow. It navigates using shadows from the neighboring objects as a hint. The approach is similar to how a person would act in real life when making a shadow manually, in Photoshop.
Module architecture: U-Net with four input channels (RGB shadow-free image and mask of the inserted object) and two output channels (mask of occluders and corresponding shadows).
Shadow generation is the most important block in the entire network architecture. Its purpose is to create a 3-channel shadow mask. Similar to the attention block, it has a U-Net architecture with an additional shadow refinement block at the output. At the input, the block receives all currently known information including the original shadow-free image (three channels), the mask of the inserted object (one channel) and the output of the attention block is the mask of neighboring objects (one channel) and the mask of their shadows (one channel). Thus, a 6-channel tensor comes to the input of the module. The output is a 3-channel tensor – a colored shadow mask for the inserted object.
The shadow generation output is concatenated (added) pixel by pixel with the original image resulting in an image with a shadow. Concatenation also resembles a layer-by-layer shadow overlay in Photoshop — the shadow seems to be inserted over the original image.
Discriminator. We took the SRGAN discriminator as a discriminator. It’s small but powerful architecture, as well as ease of implementation. Thus, the complete ARShadowGAN-like scheme will look something like this (yes, it’s small, but individual pieces in close-up have been shown above ☺):
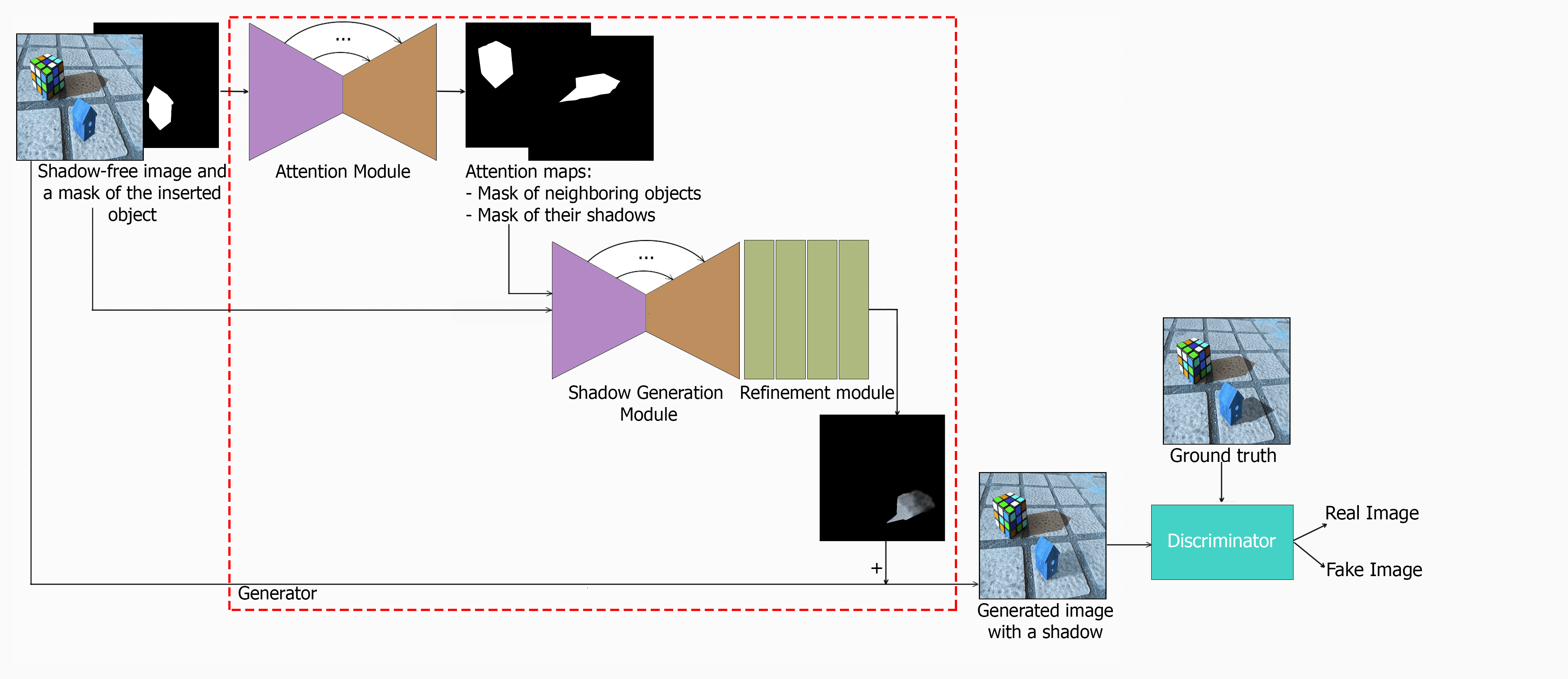
Complete ARShadowGAN-like training scheme
Collecting Dataset
Training generative adversarial networks is typically paired and unpaired.
As for paired data, everything is quite understandable: a supervised learning approach is used, that is, there is a ground truth with which the generator output can be compared. To train the network, pairs of images are chosen: the original image — the modified original image. The neural network learns to generate a modified version of the original image.
Unpaired learning is an unsupervised network learning approach. This approach is often used when it is either impossible or hard to obtain paired data. For example, unpaired learning is often used in the Style Transfer task — transferring a style from one image to another. Here, the ground truth is generally unknown, that is why it is unsupervised learning.

Coming back to our task of generating shadows, the ARShadowGAN authors use paired data to train their network. The pair is a shadow-free image and the corresponding image with a shadow.
How to collect such a dataset? There are many ways. I will explain some of them.
- You can try to collect a dataset manually — by shooting. You need to fix the scene, camera parameters, etc., and then nullify the shadows in the original scene (for example, by adjusting the light) and get images without shadows and with shadows. This approach is very time and cost consuming.
- As an alternative approach, I consider collecting a dataset from other images with shadows. The logic is as follows: we take an image with a shadow and delete the shadow. Hence, another, no less easy task follows — Image Inpainting that is a restoration of the cutout pieces in the image, or again manual work in Photoshop. Besides, the network can easily be overfitting on such a dataset, since artefacts can be detected that are not visible to the human eye but are noticeable at a deeper semantic level.
- Another way is to collect a synthetic dataset using 3D. The ARShadowGAN authors opted for it and collected ShadowAR-dataset. They selected several 3D models from the well-known ShapeNet library, and then these models were fixed in the correct position relative to the scene. Then they launched rendering of these objects on the transparent background with the light source on and off — with and without shadows. After that, renders of the selected objects were simply inserted into 2D images of scenes without additional processing. So they got pairs: the original shadow-free image (noshadow) and the ground truth image with a shadow (shadow). You can read more about collecting ShadowAR-dataset in the original article.
So, we have pairs of images: noshadow and shadow. Where do masks come from?
We have three masks: the mask of the inserted object, the mask of neighboring objects (occluders), and the mask of their shadows. The mask of the inserted object is easily obtained after rendering the object against a transparent background. The transparent background is filled with the black color, all other areas related to our object are filled with white. The masks of neighboring objects and their shadows were obtained by the ARShadowGAN authors by using crowdsourcing.

An example of a Shadow-AR dataset
In Part 2, we prepare for GAN training, look at loss functions and metrics, see the dataset, and more!
Published at DZone with permission of Artyom Nazarenko. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments