How to Scale RAG and Build More Accurate LLMs
Retrieval augmented generation (RAG) needs the right data architecture to scale efficiently. Learn how data streaming helps data and application teams innovate.
Join the DZone community and get the full member experience.
Join For FreeRetrieval augmented generation (RAG) has emerged as a leading pattern to combat hallucinations and other inaccuracies that affect large language model content generation. However, RAG needs the right data architecture around it to scale effectively and efficiently. A data streaming approach grounds the optimal architecture for supplying LLMs with large volumes of continuously enriched, trustworthy data to generate accurate results. This approach also allows data and application teams to work and scale independently to accelerate innovation.
Foundational LLMs like GPT and Llama are trained on vast amounts of data and can often generate reasonable responses about a broad range of topics, but do generate erroneous content. As Forrester noted recently, public LLMs “regularly produce results that are irrelevant or flat wrong,” because their training data is weighted toward publicly available internet data. In addition, these foundational LLMs are completely blind to the corporate data locked away in customer databases, ERP systems, corporate Wikis, and other internal data sources. This hidden data must be leveraged to improve accuracy and unlock real business value.
RAG allows data teams to contextualize prompts in real-time with domain-specific company data. Having this additional context makes it far more likely that the LLM will identify the right pattern in the data and provide a correct, relevant response. This is critical for popular enterprise use cases like semantic search, content generation, or copilots, where outputs must be based on accurate, up-to-date information to be trustworthy.
Why Not Just Train an LLM on Company-Specific Data?
Current best practices for generative AI often necessitate creating foundation models by training billion-node transformers on massive amounts of data, making this approach prohibitively expensive for most organizations. For example, OpenAI has said it spent more than $100 million to train GPT-4. Research and industry are beginning to provide promising results for small language models and less expensive training methods, but those aren’t generalizable and commoditized yet. Fine-tuning an existing model is another, less resource-intensive approach and may also become a good option in the future, but this technique still requires significant expertise to get right. One of the benefits of LLMs is that they democratize access to AI, but having to hire a team of PhDs to fine-tune a model largely negates that benefit.
RAG is the best option today, but it must be implemented in a way that provides accurate and up-to-date information and in a governed manner that can be scaled across applications and teams. To see why an event-driven architecture is the best fit for this, it’s helpful to look at four patterns of GenAI application development.
1. Data Augmentation
An application must be able to pull relevant contextual information, which is typically achieved by using a vector database to look up semantically similar information typically encoded in semi-structured or unstructured text. This means gathering data from disparate operational stores and “chunking” it into manageable segments that retain its meaning. These chunks of information are then embedded into the vector database where they can be coupled with prompts.
An event-driven architecture is beneficial here because it’s a proven method for integrating disparate sources of data from across an enterprise in real-time to provide reliable and trustworthy information. By contrast, a more traditional ETL (extract, transform, load) pipeline that uses cascading batch operations is a poor fit because the information will often be stale by the time it reaches the LLM. An event-driven architecture ensures that when changes are made to the operational data store, those changes are carried over to the vector store that will be used to contextualize prompts. Organizing this data as streaming data products also promotes reusability, so these data transformations can be treated as composable components that can support data augmentation for multiple LLM-enabled applications.
2. Inference
Inference involves engineering prompts with data prepared in the previous steps and handling responses from the LLM. When a prompt from a user comes in, the application gathers relevant context from the vector database or an equivalent service to generate the best possible prompt.
Applications like ChatGPT often take a few seconds to respond, which is an eternity in distributed systems. Using an event-driven approach means this communication can take place asynchronously between services and teams. With an event-driven architecture, services can be decomposed along functional specializations, which allows application development teams and data teams to work separately to achieve their objectives of performance and accuracy.
Further, by having decomposed, specialized services rather than monoliths, these applications can be deployed and scaled independently. This helps decrease time to market since the new inference steps are consumer groups, and the organization can template infrastructure for instantiating these quickly.
3. Workflows
Reasoning agents and inference steps are often linked into sequences where the next LLM call is based on the previous response. This is useful in automating complex tasks where a single LLM call will not be sufficient to complete a process. Another reason for decomposing agents into chains of calls is because the popular LLMs today tend to return better results when we ask multiple, simpler questions, although this is changing.
As the example workflow below illustrates, with a data streaming platform, the web development team can work independently from the backend system engineers, allowing each team to scale according to its needs. The data streaming platform enables this decoupling of technologies, teams, and systems.
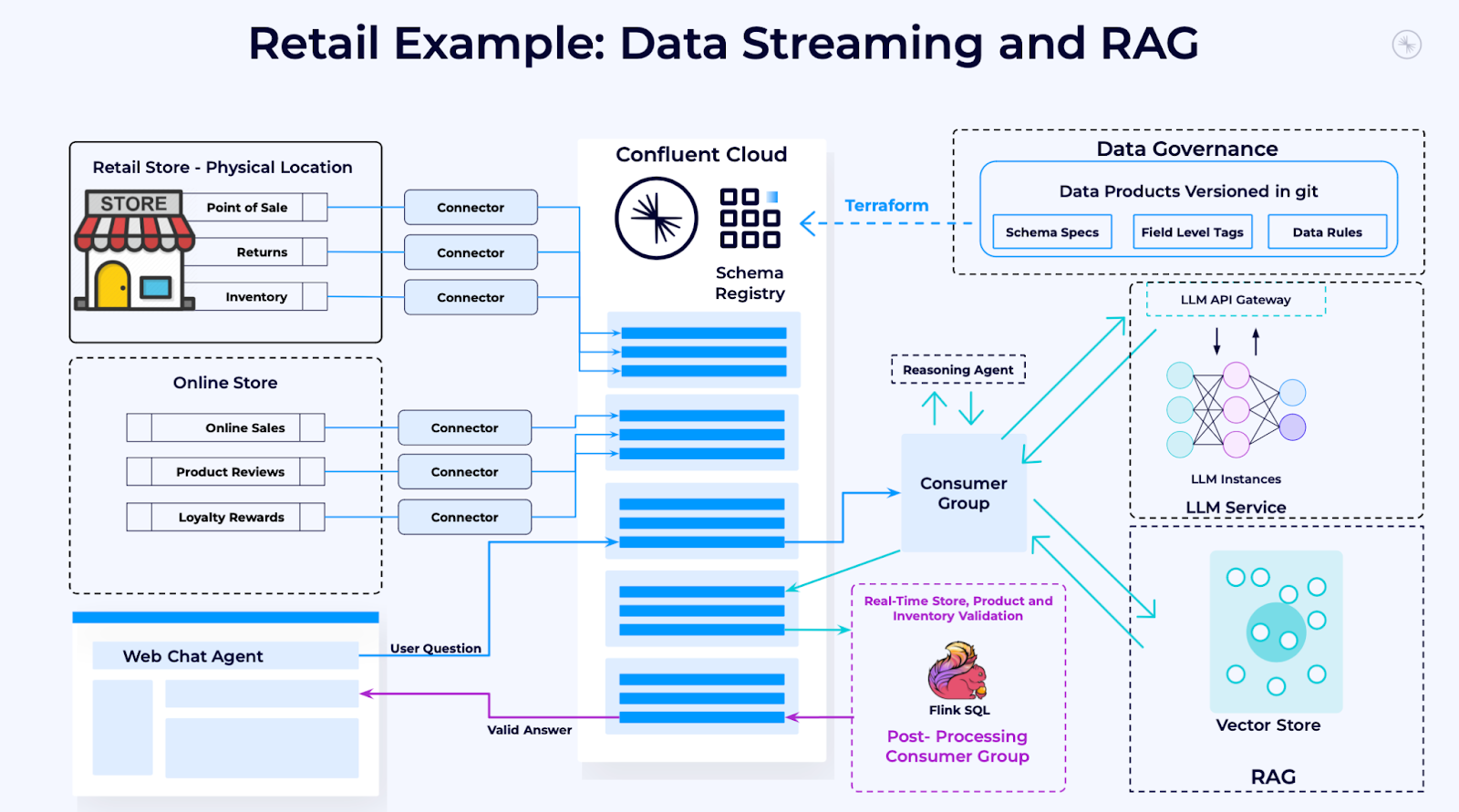
4. Post-Processing
Despite our best efforts, LLMs can still generate erroneous results, so we need a way to validate outputs and enforce business rules to prevent those errors from causing harm.
Typically, LLM workflows and dependencies change much more quickly than the business rules that determine whether outputs are acceptable. In the example above, we again see good use of decoupling with a data streaming platform: The compliance team validating LLM outputs can operate independently to define the rules without needing to coordinate with the team building the LLM applications.
Conclusion
RAG is a powerful model for improving the accuracy of LLMs and making generative AI applications viable for enterprise use cases. But RAG is not a silver bullet. It needs to be surrounded by an architecture and data delivery mechanisms that allow teams to build multiple generative AI applications without reinventing the wheel, and in a manner that meets enterprise standards for data governance and quality.
A data streaming model is the simplest and most efficient way to meet these needs, allowing teams to unlock the full power of LLMs to drive new value for their business. As technology becomes the business and AI enhances this technology, those firms that compete effectively will incorporate AI to augment and streamline more and more processes.
By having a common operating model for RAG applications, the enterprise can bring the first use case to market quickly while also accelerating delivery and reducing costs for everyone that follows.
Published at DZone with permission of Andrew Sellers. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments