The Data (Pipeline) Movement: A Guide to Real-Time Data Streaming and Future Proofing Through AI Automation and Vector Databases
Dive into the essential strategies for leveraging real-time data streaming, AI automation, and vector databases to drive actionable insights.
Join the DZone community and get the full member experience.
Join For FreeEditor's Note: The following is an article written for and published in DZone's 2024 Trend Report, Data Engineering: Enriching Data Pipelines, Expanding AI, and Expediting Analytics.
This article explores the essential strategies for leveraging real-time data streaming to drive actionable insights while future proofing systems through AI automation and vector databases. It delves into the evolving architectures and tools that empower businesses to stay agile and competitive in a data-driven world.
Real-Time Data Streaming: The Evolution and Key Considerations
Real-time data streaming has evolved from traditional batch processing, where data was processed in intervals that introduced delays, to continuously handle data as it is generated, enabling instant responses to critical events. By integrating AI, automation, and vector databases, businesses can further enhance their capabilities, using real-time insights to predict outcomes, optimize operations, and efficiently manage large-scale, complex datasets.
Necessity of Real-Time Streaming
There is a need to act on data as soon as it is generated, particularly in scenarios like fraud detection, log analytics, or customer behavior tracking. Real-time streaming enables organizations to capture, process, and analyze data instantaneously, allowing them to react swiftly to dynamic events, optimize decision making, and enhance customer experiences in real time.
Sources of Real-Time Data
Real-time data originates from various systems and devices that continuously generate data, often in vast quantities and in formats that can be challenging to process. Sources of real-time data often include:
- IoT devices and sensors
- Server logs
- App activity
- Online advertising
- Database change events
- Website clickstreams
- Social media platforms
- Transactional databases
Effectively managing and analyzing these data streams requires a robust infrastructure capable of handling unstructured and semi-structured data; this allows businesses to extract valuable insights and make real-time decisions.
Critical Challenges in Modern Data Pipelines
Modern data pipelines face several challenges, including maintaining data quality, ensuring accurate transformations, and minimizing pipeline downtime:
- Poor data quality can lead to flawed insights.
- Data transformations are complex and require precise scripting.
- Frequent downtime disrupts operations, making fault-tolerant systems essential.
Additionally, data governance is crucial to ensure data consistency and reliability across processes. Scalability is another key issue as pipelines must handle fluctuating data volumes, and proper monitoring and alerting are vital for avoiding unexpected failures and ensuring smooth operation.
Advanced Real-Time Data Streaming Architectures and Applications Scenarios
This section demonstrates the capabilities of modern data systems to process and analyze data in motion, providing organizations with the tools to respond to dynamic events in milliseconds.
Steps to Build a Real-Time Data Pipeline
To create an effective real-time data pipeline, it's essential to follow a series of structured steps that ensure smooth data flow, processing, and scalability. Table 1, shared below, outlines the key steps involved in building a robust real-time data pipeline:
Table 1. Steps to build a real-time data pipeline
| step | activities performed |
|---|---|
| 1. Data ingestion | Set up a system to capture data streams from various sources in real time |
| 2. Data processing | Cleanse, validate, and transform the data to ensure it is ready for analysis |
| 3. Stream processing | Configure consumers to pull, process, and analyze data continuously |
| 4. Storage | Store the processed data in a suitable format for downstream use |
| 5. Monitoring and scaling | Implement tools to monitor pipeline performance and ensure it can scale with increasing data demands |
Leading Open-Source Streaming Tools
To build robust real-time data pipelines, several leading open-source tools are available for data ingestion, storage, processing, and analytics, each playing a critical role in efficiently managing and processing large-scale data streams.
Open-source tools for data ingestion:
- Apache NiFi, with its latest 2.0.0-M3 version, offers enhanced scalability and real-time processing capabilities.
- Apache Airflow is used for orchestrating complex workflows.
- Apache StreamSets provides continuous data flow monitoring and processing.
- Airbyte simplifies data extraction and loading, making it a strong choice for managing diverse data ingestion needs.
Open-source tools for data storage:
- Apache Kafka is widely used for building real-time pipelines and streaming applications due to its high scalability, fault tolerance, and speed.
- Apache Pulsar, a distributed messaging system, offers strong scalability and durability, making it ideal for handling large-scale messaging.
- NATS.io is a high-performance messaging system, commonly used in IoT and cloud-native applications, that is designed for microservices architectures and offers lightweight, fast communication for real-time data needs.
- Apache HBase, a distributed database built on top of HDFS, provides strong consistency and high throughput, making it ideal for storing large amounts of real-time data in a NoSQL environment.
Open-source tools for data processing:
- Apache Spark stands out with its in-memory cluster computing, providing fast processing for both batch and streaming applications.
- Apache Flink is designed for high-performance distributed stream processing and supports batch jobs.
- Apache Storm is known for its ability to process more than a million records per second, making it extremely fast and scalable.
- Apache Apex offers unified stream and batch processing.
- Apache Beam provides a flexible model that works with multiple execution engines like Spark and Flink.
- Apache Samza, developed by LinkedIn, integrates well with Kafka and handles stream processing with a focus on scalability and fault tolerance.
- Heron, developed by Twitter, is a real-time analytics platform that is highly compatible with Storm but offers better performance and resource isolation, making it suitable for high-speed stream processing at scale.
Open-source tools for data analytics:
- Apache Kafka allows high-throughput, low-latency processing of real-time data streams.
- Apache Flink offers powerful stream processing, ideal for applications requiring distributed, stateful computations.
- Apache Spark Streaming integrated with the broader Spark ecosystem handles real-time and batch data within the same platform.
- Apache Druid and Pinot serve as real-time analytical databases, offering OLAP capabilities that allow querying of large datasets in real time, making them particularly useful for dashboards and business intelligence applications.
Implementation Use Cases
Real-world implementations of real-time data pipelines showcase the diverse ways in which these architectures power critical applications across various industries, enhancing performance, decision making, and operational efficiency.
Financial Market Data Streaming for High-Frequency Trading Systems
In high-frequency trading systems, where milliseconds can make the difference between profit and loss, Apache Kafka or Apache Pulsar are used for high-throughput data ingestion. Apache Flink or Apache Storm handle low-latency processing to ensure trading decisions are made instantly. These pipelines must support extreme scalability and fault tolerance as any system downtime or processing delay can lead to missed trading opportunities or financial loss.
IoT and Real-Time Sensor Data Processing
Real-time data pipelines ingest data from IoT sensors, which capture information such as temperature, pressure, or motion, and then process the data with minimal latency. Apache Kafka is used to handle the ingestion of sensor data, while Apache Flink or Apache Spark Streaming enable real-time analytics and event detection. Figure 1 shared below shows the steps of stream processing for IoT from data sources to dashboarding:
Figure 1. Stream processing for IoT
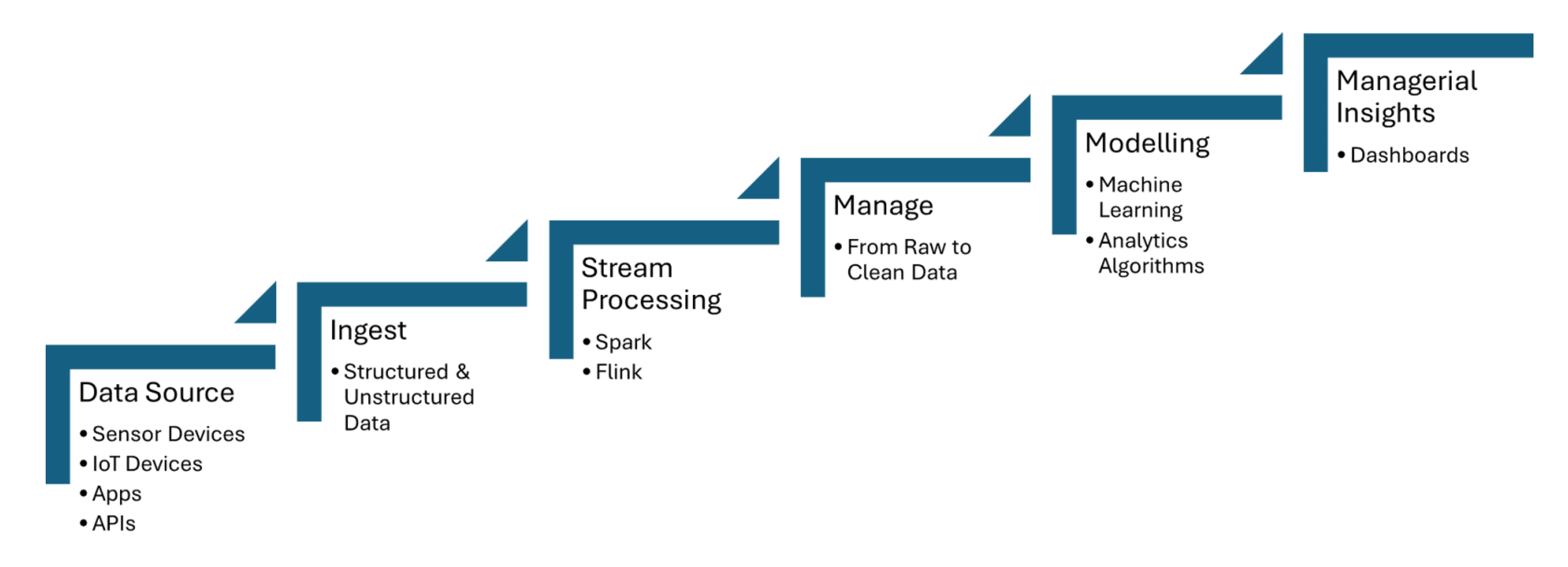
Fraud Detection From Transaction Data Streaming
Transaction data is ingested in real time using tools like Apache Kafka, which handles high volumes of streaming data from multiple sources, such as bank transactions or payment gateways. Stream processing frameworks like Apache Flink or Apache Spark Streaming are used to apply machine learning models or rule-based systems that detect anomalies in transaction patterns, such as unusual spending behavior or geographic discrepancies.
How AI Automation Is Driving Intelligent Pipelines and Vector Databases
Intelligent workflows leverage real-time data processing and vector databases to enhance decision making, optimize operations, and improve the efficiency of large-scale data environments.
Data Pipeline Automation
Data pipeline automation enables the efficient handling of large-scale data ingestion, transformation, and analysis tasks without manual intervention. Apache Airflow ensures that tasks are triggered in an automated way at the right time and in the correct sequence. Apache NiFi facilitates automated data flow management, enabling real-time data ingestion, transformation, and routing. Apache Kafka ensures that data is processed continuously and efficiently.
Pipeline Orchestration Frameworks
Pipeline orchestration frameworks are essential for automating and managing data workflows in a structured and efficient manner. Apache Airflow offers features like dependency management and monitoring. Luigi focuses on building complex pipelines of batch jobs. Dagster and Prefect provide dynamic pipeline management and enhanced error handling.
Adaptive Pipelines
Adaptive pipelines are designed to dynamically adjust to changing data environments, such as fluctuations in data volume, structure, or sources. Apache Airflow or Prefect allow for real-time responsiveness by automating task dependencies and scheduling based on current pipeline conditions. These pipelines can leverage frameworks like Apache Kafka for scalable data streaming and Apache Spark for adaptive data processing, ensuring efficient resource usage.
Streaming Pipelines
A streaming pipeline for populating a vector database for real-time retrieval-augmented generation (RAG) can be built entirely using tools like Apache Kafka and Apache Flink. The processed streaming data is then converted into embeddings and stored in a vector database, enabling efficient semantic search. This real-time architecture ensures that large language models (LLMs) have access to up-to-date, contextually relevant information, improving the accuracy and reliability of RAG-based applications such as chatbots or recommendation engines.
Data Streaming as Data Fabric for Generative AI
Real-time data streaming enables real-time ingestion, processing, and retrieval of vast amounts of data that LLMs require for generating accurate and up-to-date responses. While Kafka helps in streaming, Flink processes these streams in real time, ensuring that data is enriched and contextually relevant before being fed into vector databases.
The Road Ahead: Future Proofing Data Pipelines
The integration of real-time data streaming, AI automation, and vector databases offers transformative potential for businesses. For AI automation, integrating real-time data streams with frameworks like TensorFlow or PyTorch enable real-time decision making and continuous model updates. For real-time contextual data retrieval, leveraging databases like Faiss or Milvus help in fast semantic searches, which are crucial for applications like RAG.
Conclusion
Key takeaways include the critical role of tools like Apache Kafka and Apache Flink for scalable, low-latency data streaming, along with TensorFlow or PyTorch for real-time AI automation, and FAISS or Milvus for fast semantic search in applications like RAG. Ensuring data quality, automating workflows with tools like Apache Airflow, and implementing robust monitoring and fault-tolerance mechanisms will help businesses stay agile in a data-driven world and optimize their decision-making capabilities.
Additional resources:
- AI Automation Essentials by Tuhin Chattopadhyay, DZone Refcard
- Apache Kafka Essentials by Sudip Sengupta, DZone Refcard
- Getting Started With Large Language Models by Tuhin Chattopadhyay, DZone Refcard
- Getting Started With Vector Databases by Miguel Garcia, DZone Refcard
This is an excerpt from DZone's 2024 Trend Report,
Data Engineering: Enriching Data Pipelines, Expanding AI, and Expediting Analytics.
Read the Free Report
Opinions expressed by DZone contributors are their own.
Comments