Git Branching Strategies for Maintainable Test Automation
Git version control can be used, not just for project version control, but for maintaining automation frameworks.
Join the DZone community and get the full member experience.
Join For FreeAny successful project relies on three core components. People and process, along with appropriate tooling to support these two in tandem. When these three combine together in a team, it has a ground-breaking effect – productivity and quality reach new found heights.
One of the pieces of information we often get asked for at Curiosity Software is to advise on how to set up, organize, and architecture best-of-breed automation frameworks to support a client’s test automation strategy and vision for the organization. We take enormous pride in being able to provide support across all three segments (people, process, and tooling) in this space, facilitating test automation success across organizations.
Today, I want to discuss using Git effectively for test automation. A simple Google search on the subject yields few results, whereas the same search for developer-oriented strategies reveals thousands of articles. This, by and large, highlights how fresh the test automation industry is.
A lot of the principles we are going to discuss are inherited from the software developer community. These tried-and-tested insights are applied to support the creation of scalable and maintainable test automation.
How Git Is Used in Development
Firstly, let’s consider a typical git strategy for a product being developed. Usually, the development pipeline is decomposed into a few artifacts. At its rawest level, there’s a production release which is shipped to the end-users, a release candidate upon which we do final regression testing, and a development build which contains the latest features from development. This can be split into several more categories for different environments, such as supporting canary releases, integration, and more. Such categorization is standard for large-scale software development.
For each category, we build branches inside of our git repository. Branches are a way for us to branch away and independently move forward with development within an isolated code base. When we are ready, we can merge branches backward and forward with other branches stemming from the same mainline instance. Within development, a separate branch is used for each environment.
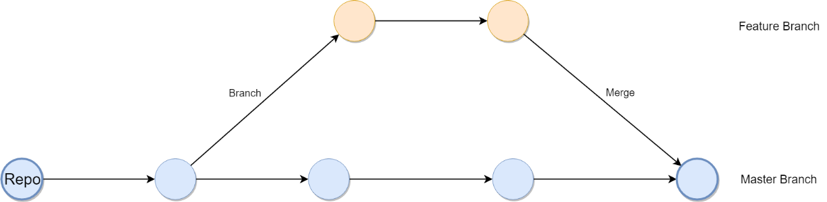
Curiosity’s own strategy for Git branching in our development environment follows this model. Firstly, developers branch from the core (master) development branch when they begin development on a new feature. To this end, developers can work in parallel, working with isolated code that relates to their user-stories and tasks. Once a feature reaches the definition of complete, a pull request is made from which a merge can be approved to integrate their code together with the work of any other developers who have also committed work in the time since the initial branch was made. Once all the features for a release or sprint have been constructed, a release candidate can be created, performing user-acceptance testing and regression across the testing pyramid (unit, functional, performance, API, and security).
With the introduction of continuous integration, it is also commonplace to continuously test each code check-in by spinning up sandbox environments and executing test automation against the code. If the tests pass at each merge, then it is integrated into the branch to be released. The final stage is to move the release candidate branch to the production branch. The candidate is thereby released, usually with appropriate tags corresponding to the release version numbers.
Of course, there is a nice visual representation of this:
Almost every development team using Git as their source control applies some variation of this approach. The particular strategy will depend on the number of environments and the layers of testing that their application passes through. Merging is a crucial concept since it is usually facilitated by a pull request which enables other developers to perform a code review. Developers can inspect the work about to be merged, approving or rejecting the merge request. This is a powerful aide in the realm of creating a quality and maintainable code base.
Git Strategies for Test Automation Framework
In an ideal world, our automation framework would reside in the same repository and would therefore be up to date with the product artifacts produced. However, this is rarely ever feasible, since usually a separate team creates the automation, and so it resides in a separate source code repository. This means that the test library must be synchronized with the product deliverable.
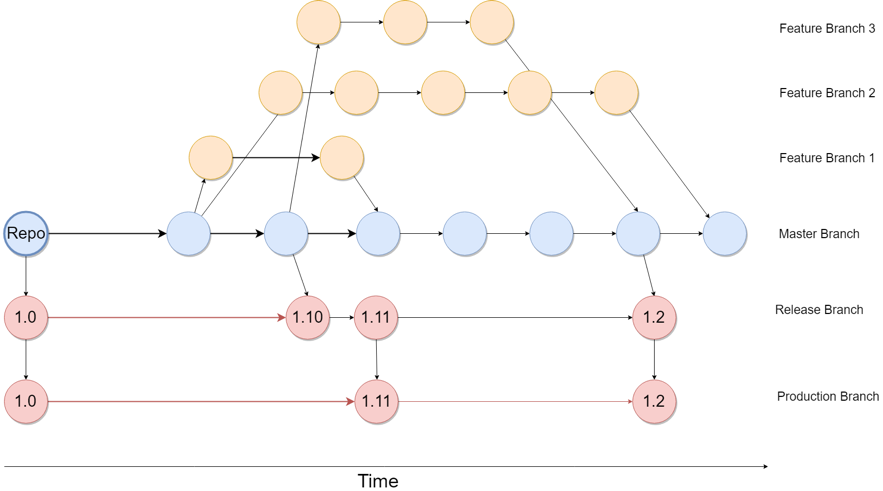
An initial strategy for a test automation framework stored in Git usually revolves around the use of one mainline. This is fine when one SDET (Software Developer Engineer in Test) is working within the project; however, scaling the framework effectively requires a much more concise branching strategy. We, therefore, decompose the branches into the categories used in development: production, release candidate, and development. There are along with branches for each feature, this time for our test assets, creating feature branches but each automation test produced.
Within this context, we use a similar branching strategy for our automation framework and our Git development environment. Firstly, SDETs branch from the core (master) branch when they start creating automation (page objects and tests) for a new feature. Creating tags to the development feature branch is also useful at this point.
Once the automation assets have been created with sufficient test coverage, a pull request is made from which a merge can be approved to integrate their code together with the work of any other automation engineers who have committed their work in-between. The use of branching in this context means we do not mix non-production ready automation with the core automation used in our continuous integration pipeline. Once the automation has been created for a release, it can be merged with the automation release branch.
The use of branching allows us to perform code reviews to the same effect, but on our automation code produced. This ensures that new code conforms to a high standard, with maintainable object identifiers and good architecture. This is a core facet for creating an effective automation framework that scales over time. It also allows us to differentiate between production ready automation, and work-in-progress automation. Furthermore, we can embed links within each branch to have full traceability between the product source code and the test automation code. Better yet, if the test branches follow the same conventions this means we can trace between the source code and automated tests.
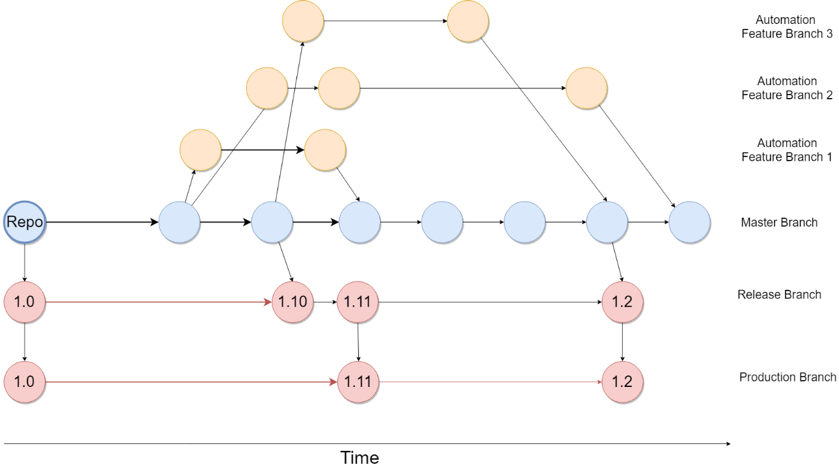
This enables us to create an automation framework that applies branching effectively to test automation assets. Notice how this is virtually identical to the methodologies used within development, but is instead applied to our test automation framework.
Scaling Automation Across the Entire Enterprise
So far, we have discussed the utility of a single automation framework. While test automation can be achieved successfully in silos across an enterprise, the most successful automation is led from the top-down, with buy-in across the whole organization. When this is the case, it does not make sense for each individual team to create their own framework and associated utilities; there needs to be a clear and coherent strategy which makes adoption seamless, and maximizes the strategic return on investment. Why reinvent the wheel?
For most organizations, the likelihood is a multitude of frameworks may already exist from keen developers who have gone off and built their own frameworks and tools. In this case, a review process should take place to identify the quality of the framework, and if it is suitable to be used across the organization. It’s often the case where an unofficial corporate framework has already gained some traction in becoming the de facto approach.
The automation framework itself should be largely considered as a separate product line, containing integrations with existing product tools, utilities for calling back-end systems or protocols, and other useful artifacts specific for automating within an organization. Such a framework is then consumed by a team on their own product lines and embedded with associated test assets (page objects and test scenarios, along with a few other custom utilities for the product). This is a good practice to follow even when automation is applied within individual teams, as it keeps the framework separate and decomposed from the actual test logic code.
If a Center of Excellence (CoE) exists when scaling automation across the enterprise, then the raw automation framework should be owned by a functional team within that unit. This team is responsible for providing the nessacery utilities, reporting functionality, integrations, and other non-functional components in the framework. Each team adopting test automation on their project can utilise this framework. Using Git it is possible to clone the central repository, and branch from it to adopt the framework. Each team embeds their own page objects and test scenarios for the product line that they are testing. This provides a coherent way for automation to be consumed across the organisation. Better yet, if the central team make changes to the framework and add new functionality (for instance when the organisation is switching their system for test case management), this can be applied at the top-most level and filtered down via merging to each individual team consuming the framework.
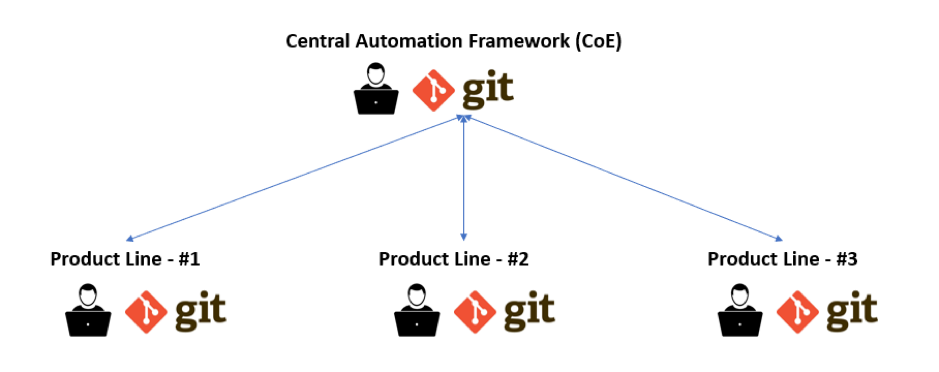
The reality is that we see many organizations where there are a multitude of different frameworks, each with their own tech stack and implemented by different teams. This is duplicated effort and goes against the grain of 21st century software development.
Build Effective Test Automation Within Your Organization
Our platform, The VIP Test Modeller is built to integrate natively with Git-based automation repositories across GitHub, GitLab, and BitBucket platforms. You can leverage these same strategies seamlessly while creating coverage focused automation tests at ease. Watch a demo of The VIP Test Modeller generating automation code for Git repositories, and visit to start your free trial.
Opinions expressed by DZone contributors are their own.
Comments