Why Do We Need to Keep Our Builds Green?
You need a CI/CD pipeline, and you need to keep it green. Have you ever thought what that means exactly? Why are we so focused on having green builds? Let's find out!
Join the DZone community and get the full member experience.
Join For FreeThe Trivial Answer
Most engineers know that we must have green builds because a red build indicates some kind of issue. Either a test did not pass, or some kind of tool found a vulnerability, or we managed to push our code when it couldn’t even compile. Either way, it is bad. You might have noticed that this article is far from over, so there must be more to this. You are right!
What Does Green Mean Exactly?
We have already discussed that red means something wrong, but can we say that green is the opposite? Does it guarantee that everything is working great, meets the requirements, and is ready to deploy? As usual, it depends.
When your build turns green, we can say, that:
- The code compiled (assuming you are using a language with a compiler).
- The existing (and executed) tests passed.
- The analyzers found no critical issues that needed to be fixed right away.
- We were able to push our binaries to an artifact storage or image registry.
- Depending on our setup, we might be ready to deploy our code at the moment.
Why am I still not saying anything definite about the state of the software even when the tests passed? It is because I am simply not sure whether a couple of important things are addressed by our theoretical CI system in this thought-experiment. Let me list a couple of the factors I am worried about. Please find these in the following sections!
Test Quality
I won’t go deep into details as testing and good quality tests are bigger topics, deserving way more focus than what I could squeeze in here. Still, when talking about test quality, I think we should at least mention the following thoughts as bullet points:
- Do we have sufficient test coverage?
- Are our test cases making strict assertions that can discover the issues we want to discover?
- Are we testing the things we should? Meaning: Are we focusing on the most important requirement first instead of testing the easy parts?
- Are our tests reliable and in general following the F.I.R.S.T. principles?
- Are we running our tests with each build of the code they are testing?
- Are we aware of the test pyramid and following the related recommendations?
Augmenting these generic ideas, I would like to mention a few additional thoughts in a bit more detail.
What Kinds of Dependencies Are We Using in Our Tests?
In the lower layers of the test pyramid, we should prefer using test doubles instead of the real dependencies to help us focus on the test case and be able to generate exceptional scenarios we need to cover in our code.
Do We Know What We Should Focus on For Each Layer of The Test Pyramid?
The test pyramid is not only about the number of tests we should have on each layer, but it gives us an idea about their intent as well. For example, the unit tests should test only a small unit (i.e., a single class) to prod and poke our code and see how it behaves in a wide variety of situations assuming that everything else is working well. As we go higher, the focus moves onto how our classes behave when they are integrated into a component, still relying on test doubles to eliminate any dependency (and any unknowns) related to the third-party components used by our code. Then in the integration tests, we should focus on the integration of our components with their true dependencies to avoid any issues caused by the imperfections of the test doubles we have been using in our lower-layer tests. In the end, the system tests can use an end-to-end mindset to observe how the whole system behaves from the end user’s point of view.
Are Our Code Dependencies Following Similar Practices?
Hopefully, the dependency selection process considers the maturity and reliability of the dependencies as well as their functionality. This is very important because we must be able to trust our dependencies that they are doing what they say they do. Thorough testing of the dependency can help us build this trust, while the lack of tests can do the opposite. My personal opinion on this is that I cannot expect my users to test my code when they pick my components as dependencies, because not only they cannot possibly do it well; but I won’t know either when their tests fail because my code contains a bug — a bug that I was supposed to find and fix when I released my component. For the same reason, when I am using a dependency, I think my expectation that I should not test that dependency is reasonable.
Having Repeatable Builds
It can be a great feeling when our build turns green after a hard day’s work. It can give us pride, a feeling of accomplishment, or even closure depending on the context. Yet it can be an empty promise, a lie that does very little good (other than generating a bunch of happy chemicals for our brain) if we cannot repeat it when we need to. Fortunately, there is a way to avoid these issues if we consider the following factors.
Using Reliable Tags
It is almost a no-brainer that we need to tag our builds to be able to get back to the exact version we have used to build our software. This is a great start for at least our code, but we should keep in mind that nowadays it is almost impossible to imagine a project where we are starting from an empty directory and doing everything on our own without using any dependencies. When using dependencies, we can make a choice between convenience and doing the right thing. On one hand, the convenient option lets us use the latest dependencies without doing anything: we just need to use the wildcard or special version constant supported by our build tool to let it resolve the latest stable version during the build process. On the other hand, we can pin down our dependencies; maybe we can even vendor them if we want to avoid some nasty surprises and have a decent security posture. If we decide to do the right thing, we will be able to repeat the build process using the exact same dependencies as before, giving us a better chance of producing the exact same artifact if needed. In the other case, we would be hard-pressed to do the same a month or two after the original build. In my opinion, this is seriously undermining the usability of our tags and makes me trust the process less.
Using The Same Configuration
It is only half of the battle to be able to produce the same artifact in the end when we are rebuilding the code. We must be able to repeat the same steps during the build and use the same application configuration for the deployments in order to have the same code and use the same configuration and input to run our tests.
It Shouldn't Start With The Main Branch
Although we are doing this work in order to have repeatable builds on the main branch the process should not start there. If we want to be sure that the thing we are about to merge won't break the main build, we should at least try building it using the same tools and tests before we click merge. Luckily the Git branch protection rules are very good at this. To avoid broken builds, we should make sure that:
- The PRs cannot be merged without both the necessary approvals and a successful build validating everything the main build will validate as well.*
- The branch is up to date, meaning that it contains all changes from the main branch as well.
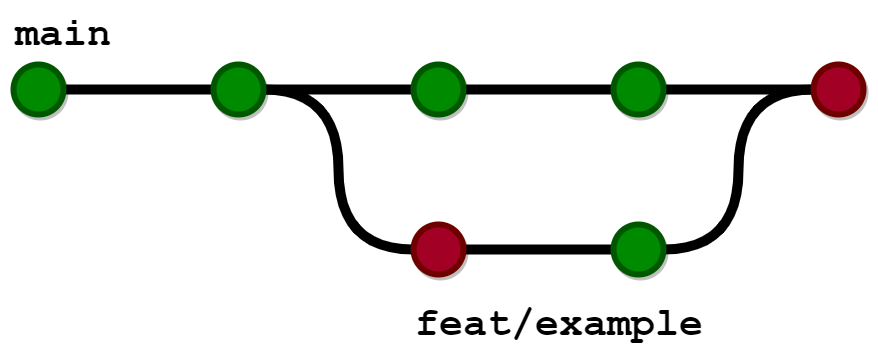
Good code can still cause failures if the main branch contains incompatible changes.
*Note: Of course, this is not trivial to achieve, because how can we test, for example, that the artifact will be successfully published to the registry containing the final, ready-to-deploy artifacts? Or how could we verify, that we will be able to push the Git tag when we release using the other workflow? Still, we should do our best to minimize the number of differences just like we do when we are testing our code.
Using this approach, we can discover the slight incompatibilities of otherwise well-working changes before we merge them into the main.
Why Do We Need Green Build Then?
To be honest, green builds are not what we need. They are only the closest we have to the thing we need: a reliable indicator of working software. We need this indicator because we must be able to go there and develop the next feature or fix a production bug when it is discovered. Without being 100% sure that the main branch contains working software, we cannot do either of those because first, we need to see whether it is still working and fix the build if it is broken.
In many cases, the broken builds are not due to our own changes, but external factors. For example, without pinning down all dependencies, we cannot guarantee the same input for the build, so the green builds cannot be considered reliable indicators either. This is not only true for code dependencies, but any dependency we are using for our tests as well. Of course, we cannot avoid every potential cause for failure. For example, we can’t do anything against security issues that are noticed after our initial build. Quite naturally, these can still cause build failures. My point is that we should do our best in the area where we have control over things, like the tests where we can rely on test doubles for the lower layers of the test pyramid.
What Can You Do When Facing These Issues?
Work on improving build repeatability. You can:
- Consider pinning down all your dependencies to use the same components in your tests. This can be achieved by:
- Using fixed versions instead of ranges in Maven or Gradle
- Make sure the dependencies of your dependencies will remain pinned, too, by checking whether their build files contain any ranges.
- Using SHA 256 manifest digests for Docker images instead of the tag names
- Make sure that you are performing the same test cases as before by:
- Following general testing best practices like the F.I.R.S.T. principles
- Starting from the same initial state in case of every other dependency (cleaning up database content, user accounts, etc.)
- Performing the same steps (with similar or equivalent data)
- Make sure you always tag:
- Your releases
- Your application configuration
- The steps of the build pipeline you have used for the build
- Apply strict branch protection rules.
What Should We Not Try to Fix?
We should keep in mind that this exercise is not about zealously working until we can just push a build button repeatedly and expect that the exact same workflow does the exact same thing every time like clockwork. This could be an asymptotic goal, but in my opinion, it shouldn’t. The goal is not to do the same thing and produce the exact same output, because we don’t need that. We have already built the project, published all versioned binary artifacts, and saved all test results the first time around. Rebuilding and overwriting these can be harmful because it can become a way to rewrite history and we can never trust our versioning or artifacts ever again.
When a build step produces an artifact that is saved somewhere (may it be a binary, a test report, some code scan findings, etc.) that artifact should be handled as a read-only archive and should never change once saved. Therefore, if someone kicks off a build from a previously successfully built tag, it is allowed (or even expected) to fail when the artifact uploads are attempted.
In Conclusion
I hope this article helped you realize that focusing on the letter of the law is less important than the spirit of the law. It does not matter if you had a green build if you are not able to demonstrate, that your tagged software remained ready for deployment. At the end of the day, if you have a P1 issue in production nobody will care about the fact that your software was ready to deploy in the past if you cannot show that it is still ready to deploy now, and we can start working on the next increment without additional unexpected problems.
What do you think about this? Let me know in the comments!
Opinions expressed by DZone contributors are their own.
Comments