Extracting Table Structures
Extracting table structures from SQL Server databases, converting them to JSON format, keeping them in Azure Studio, and then loading them into BigQuery.
Join the DZone community and get the full member experience.
Join For FreeThis document outlines the process of extracting table structures from SQL Server databases, converting them to JSON format, keeping them in Azure Studio, and then loading them into BigQuery using Cloud Data Fusion. The data types of the SQL Server data are converted to their corresponding BigQuery data types to ensure compatibility and accurate data analysis.
The process involves creating a JSON file with the converted data types and adding additional metadata columns. This file is then used in the Terraform code to define the infrastructure resources. Azure DevOps is integrated into the project to automate the infrastructure provisioning and data pipeline deployment.
Below are the prerequisites before any technical development starts for the implementation of Terraform for the GCP BigQuery Project.
Technical
- Familiarity with SQL Server databases
- Familiarity with GCP Cloud Data Fusion
- Familiarity with BigQuery
- Familiarity with Terraform
- Familiarity with Azure DevOps
- Infrastructure
Access to a SQL Server Instance
- A GCP project with Cloud Data Fusion and BigQuery enabled
- An Azure DevOps account
Tools
- SQL Server Management Studio
- GCP Cloud Data Fusion console
- BigQuery web UI
- Terraform CLI
- Azure DevOps Pipelines
SQL Server Data Types to JSON to Terraform and AzureDev Ops
- SQL Server Databases: The four source databases, ABC_CO, ABC_GI, ABC_Pay, and ABC_TS, reside on SQL Server instances.
- GCP Cloud Data Fusion: Cloud Data Fusion acts as the data integration platform, responsible for extracting data from SQL Server, transforming it as needed, and loading it into BigQuery.
- BigQuery: BigQuery serves as the data warehouse, providing a scalable and cost-effective solution for storing and analyzing the ingested data.
SQL Script Data Type Conversion
Before loading data into BigQuery, it's crucial to convert the SQL Server data types to their corresponding BigQuery data types. This ensures compatibility and facilitates accurate data storage and analysis.
Sample Code Converting the SQL Script to JSON for the SQL Server Database That You Choose
select lower(COLUMN_NAME) AS name,
case
when DATA_TYPE = 'BIGINT' THEN 'int64'
when DATA_TYPE = 'BINARY' THEN 'bytes'
when DATA_TYPE = 'BIT' THEN 'bool'
when DATA_TYPE = 'CHAR' THEN 'string'
when DATA_TYPE = 'DATE' THEN 'date'
when DATA_TYPE = 'DATETIME' THEN 'timestamp'
when DATA_TYPE = 'DATETIME2' THEN 'timestamp'
when DATA_TYPE = 'DATETIMEOFFSET' THEN 'numeric'
when DATA_TYPE = 'DECIMAL' THEN 'numeric'
when DATA_TYPE = 'FLOAT' THEN 'float64'
when DATA_TYPE = 'IMAGE' THEN 'bytes'
when DATA_TYPE = 'INT' THEN 'int64'
when DATA_TYPE = 'MONEY' THEN 'numeric'
when DATA_TYPE = 'NCHAR' THEN 'string'
when DATA_TYPE = 'NTEXT' THEN 'string'
when DATA_TYPE = 'NUMERIC' THEN 'numeric'
when DATA_TYPE = 'NVARCHAR' THEN 'string'
when DATA_TYPE = 'NVARCHAR(MAX)' THEN 'string'
when DATA_TYPE = 'REAL' THEN 'float64'
when DATA_TYPE = 'SMALLDATETIME' THEN 'timestamp'
when DATA_TYPE = 'SMALLINT' THEN 'int64'
when DATA_TYPE = 'SMALLMONEY' THEN 'numeric'
when DATA_TYPE = 'TEXT' THEN 'string'
when DATA_TYPE = 'TIME' THEN 'time'
when DATA_TYPE = 'TINYINT' THEN 'int64'
when DATA_TYPE = 'UDT' THEN 'bytes'
when DATA_TYPE = 'UNIQUEIDENTIFIER' THEN 'string'
when DATA_TYPE = 'VARBINARY' THEN 'bytes'
when DATA_TYPE = 'VARBINARY(MAX)' THEN 'bytes'
when DATA_TYPE = 'VARCHAR' THEN 'string'
when DATA_TYPE = 'VARCHAR(MAX)' THEN 'string'
when DATA_TYPE = 'XML' THEN 'string'
when DATA_TYPE = 'SQLVARIANT' THEN 'string'
when DATA_TYPE = 'GEOMETRY' THEN 'bytes'
when DATA_TYPE = 'GEOGRAPHY' THEN 'bytes'
END as type,
case
when IS_NULLABLE = 'NO' THEN 'REQUIRED'
when IS_NULLABLE = 'YES' THEN 'NULLABLE'
END AS mode
from INFORMATION_SCHEMA.COLUMNS
WHERE TABLE_NAME = 'CustomerXref'
for JSON PATH
JSON Script Results
We used the JSON formatter to format in the right way, which is used in the Terraform.
We need to create a new file.json and copy/paste the formatted script. We have additional columns as metadata columns that need to be added in the script, as shown in the screenshot below.
We need to push it into the feature branch and work on it, but for my testing purposes, I pushed the main branch.
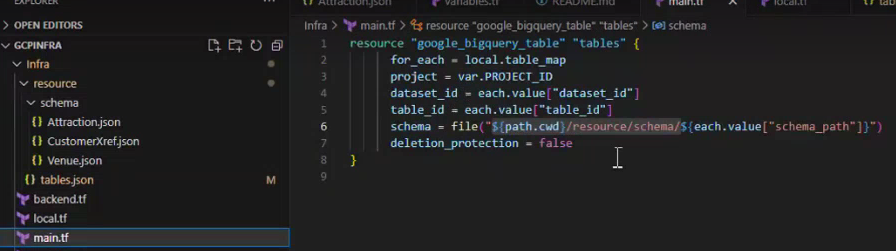
Tables.json, we need to define all the schema paths, and in tables.json, it is used in main.tf (terraform)
main.tf
Terraform and Azure DevOps Integration
Dev Task has been enabled.
To automate the infrastructure provisioning and data pipeline deployment, Terraform and Azure DevOps are integrated into the project. Terraform scripts define the infrastructure resources, while Azure DevOps orchestrates the Terraform execution and data pipeline deployment.
Finally, we need to run/release the pipeline from Azure DevOps. It will auto-trigger to create the Table in BigQuery.
We can check the status of the Agent Job.
The table will be created in the BigQuery.
Opinions expressed by DZone contributors are their own.
Comments