Evolution of Data Partitioning: Traditional vs. Modern Data Lakes
In this blog, we will be comparing data partitioning schemes in older data lakes to modern data lakes like Apache Iceberg.
Join the DZone community and get the full member experience.
Join For FreeIn the era of exploding user engagement with customer-centric applications such as streaming services, online shopping, social media, and microblogging, enterprises are grappling with an ever-expanding volume of data. This deluge of data presents a challenge: how to efficiently store, process, and analyze it to provide customers with an enhanced experience. To navigate this data landscape and ensure timely access to information for informed decision-making, Data Lakes have turned to a key technique known as Data Partitioning.
Data partitioning is the technique of dividing extensive datasets into more manageable and logically structured components. Not only does it elevate data organization, but it also yields a significant enhancement in query performance.
In this post, we will delve into the realm of data partitioning, comparing the traditional partitioning methods of legacy data lakes with the modern partitioning schema employed in contemporary data lakes.
Legacy Data Lakes
Data Lakes, such as those built on Hadoop HDFS (Hadoop Distributed File System), adopted partitioning strategies to address this challenge.
Directory-Based Partitioning
One of the foundational partitioning methods in Legacy Data Lakes involved directory-based partitioning. In this approach, data was organized within a file system by creating directories that corresponded to different attributes or criteria.
For example, consider an airline that deals with bookings of flights; for airlines to better partition data, they could choose partition fields such as region, year, month, and day.
//Example Partition layout in hive
region=US/year=2020/
month=11/
day=1/
day=2/
....
day=30/
month=12/
day=1/
day=2/
....
day=31/For each partition in a Data Lake, several pieces of metadata are typically stored in the Metastore. These metadata include:
- Partition Key: This is the attribute or criterion by which the data is partitioned, such as date, region, or category.
- Location: The physical storage location of the partition within the underlying file system or storage layer. This information allows for efficient retrieval of data.
- Schema Information: Details about the schema of the data contained within the partition. This includes the data types, column names, and any changes or updates to the schema over time.
- Statistics: Information related to the data’s statistics, such as the number of rows, size, and any other relevant metrics. This is valuable for query optimization.
Query Optimization and Performance
This partition metadata in the Metastore is critical for optimizing query performance in Data Lakes. When a query is executed, the Metastore provides information about where the data resides and how it is structured. This enables the query engine to skip irrelevant partitions, retrieve only the necessary data, and apply predicate pushdown, significantly improving query efficiency.
Disadvantages of Directory-Based Partitions
- Performance Overhead : Once a table has thousands of partitions, it will start becoming overhead to fetch table metadata or update table metadata.
- Complexity in Schema Evolution : Once a partition schema for a table has been defined, updating partition columns is a very cumbersome and costly effort.
- Data Skew: Uneven data distribution among partitions can lead to data skew. Some partitions may contain significantly more data than others, causing query performance imbalances.
Despite these disadvantages, partitions are a valuable tool for improving query performance and organizing data in data warehousing and analytics scenarios. Organizations must weigh the benefits against these drawbacks when designing their data processing workflows and consider whether they align with their specific use cases and requirements.
Modern Data Lakes
Modern Data Lakes represent a paradigm shift in the way organizations manage and utilize their data assets. These data repositories are designed to address the challenges posed by ever-expanding data volumes, evolving data structures, and the demand for real-time analytics.
Partitioning in Modern Data Lakes
We’ll explore how partitioning works in Modern Data Lakes, using Apache Iceberg as an example. Apache Iceberg is an open-source table format designed for big data that brings the benefits of ACID transactions, schema evolution, and efficient data storage to modern Data Lakes.
In modern data lakes, data is organized into logical partitions based on specific attributes or criteria, such as day, hour, year, or region. Each partition acts as a subset of the data, making it easier to manage, query, and optimize data retrieval. Partitioning enhances both data organization and query performance.
Instead of relying solely on directory-based partitioning or basic column-based partitioning, these systems provide support for complex, nested, and multi-level partitioning structures. This means that data can be partitioned using multiple attributes simultaneously, allowing for highly efficient data pruning during queries.
Partition Evolution
With prior data lakes, changes in partitioning needed physical file changes, which came with huge effort and a re-write of the entire table.
Partitioning works seamlessly with schema evolution and versioning without the need to rewrite the table and all of its data. As data schemas change over time, partitions are designed to adapt without causing data disruptions. This flexibility ensures that you can incorporate new data types or adapt to changing business needs without complex migration processes.
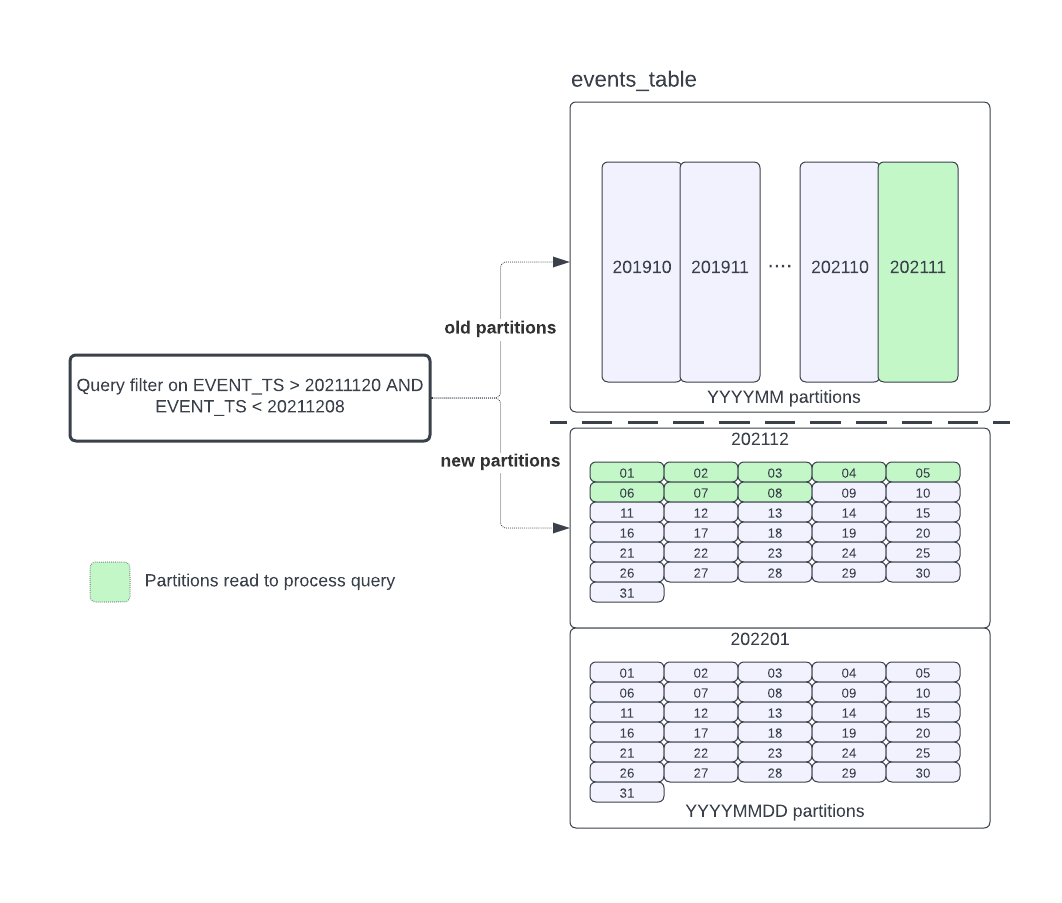
Let’s illustrate the practical benefits of Apache Iceberg with an example. Suppose we have a table initially partitioned by the ‘day’ attribute in a ‘YYYYMM’ format, like ‘201901’. Now, consider a scenario where our data access pattern changes and we need to transition to a more granular ‘YYYYMMDD’ partitioning scheme starting from ‘20211201’.
Imagine you have a query that spans from ‘20211120’ to ‘20221208’. In this case, we are dealing with a mix of partition schemes. Data before ‘20211201’ is partitioned by month, whereas data from ‘20211201’ onwards is partitioned by day. When the query plan is generated, it will intelligently navigate through these partitions.
For the period from ‘20211120’ to ‘20211201’, the query will scan month partitions, efficiently reading only the relevant data from each month. However, from ‘20211201’ to ‘20221208’, the query engine will switch to day partitions, allowing it to precisely access only the required eight days of data.
Hidden Partitions
Imagine we have a table of events, and we want to partition it by a transformed event_timestamp field. Specifically, we want to create partitions by year, month, and day, allowing for flexible querying based on different time granularities.
Consider we have to query something like below, with Icebergs partitions on year, month, and day query planner will intelligently only read at data from required partitions.
SELECT * FROM events
WHERE event_timestamp >= '2022-10-01' AND event_timestamp < '2022-12-31';If we have similar partition structure in legacy data lake like hive, we would have nested partition starting with year, month, and day. So, we will have to modify the query according to the partition scheme.
//Partition layout in hive
/.../year=2020/
month=11/
day=1/
day=2/
....
day=30/
month=12/
day=1/
day=2/
....
day=31/One problem with the above layout is if we have a query like the one below, it will lead to full scan as the query planner does not understand that partitions are derived from event_ts field. Now user has to have a deep understanding of the table partition layout to write optimized queries.
// leads to full scan
SELECT * FROM events
WHERE date_format(event_ts, 'yyyy-MM-dd') BETWEEN '2022-10-01' AND '2022-12-31';
// leads to partition pruning
SELECT * FROM events
WHERE year = '2022' and month in ('10', '11', '12')Snapshots
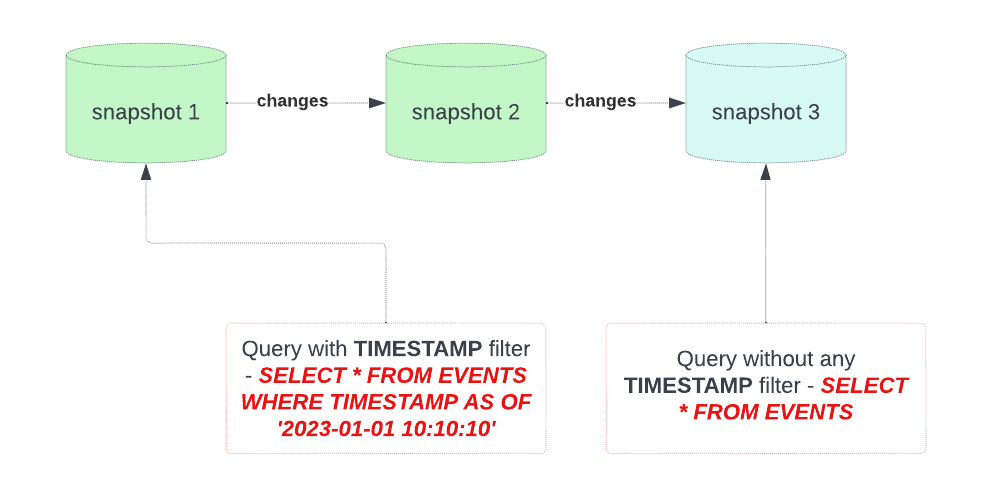
Snapshots are a fundamental concept used to capture and manage different versions or states of a table at specific points in time. Snapshots are a key feature that enables Time Travel, data auditing, schema evolution, and query consistency within modern Data Lakes like Iceberg tables.
Some important features of snapshots are below :
- Each snapshot represents a specific version of the data table. When you create a snapshot, it essentially freezes the state of the table at the moment the snapshot is taken. This makes it possible to maintain a historical record of changes to the table over time.
- One of the primary use cases for snapshots is Time Travel. You can query the data in an Iceberg table as it existed at the time a specific snapshot was taken. This allows for historical analysis, auditing, and debugging without affecting the current state of the table.
- Snapshots are immutable, meaning they cannot be modified once created. This immutability ensures the integrity and consistency of historical data. Any changes to the table are reflected in new snapshots.
- Rather than duplicating the entire table for each snapshot, only the changes or metadata needed to recreate the table’s state at the snapshot’s timestamp are stored. This minimizes storage overhead.
- When querying data, it's guaranteed to have consistent reads by using snapshots. This means that queries see a consistent view of the data as it existed at the time of the snapshot, even if changes to the table are ongoing.
Conclusion
Modern data lakes redefine partitioning, surpassing their older counterparts by introducing:
- Fine-grained partitioning
- Schema evolution
- Metadata-driven optimization.
- Snapshots.
This dynamic approach adapts to changing data needs without rewriting entire datasets. In contrast, older systems rely on static partitions, demanding precise structures for efficient querying.
Opinions expressed by DZone contributors are their own.
Comments