Database in Fintech: How To Support 10,000 Dashboards Without Causing a Mess
This article introduces the lifecycle of financial metrics in a database, from how they're produced to how they're efficiently presented in data reports.
Join the DZone community and get the full member experience.
Join For FreeIn a data-intensive industry like finance, data comes from numerous entries and goes to numerous exits. Such status quo can easily, and almost inevitably, lead to chaos in data analysis and management. For example, analysts from different business lines define their own financial metrics in data reports. When you pool these countless reports together in your data architecture, you will find that many metrics overlap or even contradict each other in definition. The consequence is, developing a simple data report will require lots of clarification back and forth, making the process more complicated and time-consuming than it should be.
As your business grows, your data management will arrive at a point when "standardization" is needed. In terms of data engineering, that means you need a data platform where you can produce and manage all metrics. That's your architectural prerequisite to provide efficient financial services.
This article introduces the lifecycle of financial metrics in a database (in this case, Apache Doris), from how they're produced to how they're efficiently presented in data reports. You will get an inside view of what's behind those fancy financial dashboards.
Define New Metrics and Add Them to Your Database
Fundamentally, metrics are fields in a table. To provide a more concrete idea of them, I will explain with an example in the banking industry.
Banks measure the assets of customers by AUM (Assets Under Management). In this scenario, AUM is an atomic metric, which is often a field in the source data table. On the basis of AUM, analysts derive a series of derivative metrics, such as "year-on-year AUM growth", "month-on-month AUM growth", and "AUM per customer".
Once you define the new metrics, you add them to your data reports, which involves a few simple configurations in Apache Doris:
Developers update the metadata accordingly, register the base table where the metrics are derived, configure the data granularity and update frequency of intermediate tables, and input the metric name and definition. Some engineers will also monitor the metrics to identify abnormalities and remove redundant metrics based on a metric evaluation system.
When the metrics are soundly put in place, you can ingest new data into your database to get your data reports. For example, if you ingest CSV files, we recommend the Stream Load method of Apache Doris and a file size of 1~10G per batch. Eventually, these metrics will be visualized in data charts.
Calculate Your Metrics
As is mentioned, some metrics are produced by combining multiple fields in the source table. In data engineering, that is a multi-table join query. Based on the optimization experience of an Apache Doris user, we recommend flat tables instead of Star/Snowflake Schema. The user reduced the query response time on tables of 100 million rows from 5s to 63ms after such a change.
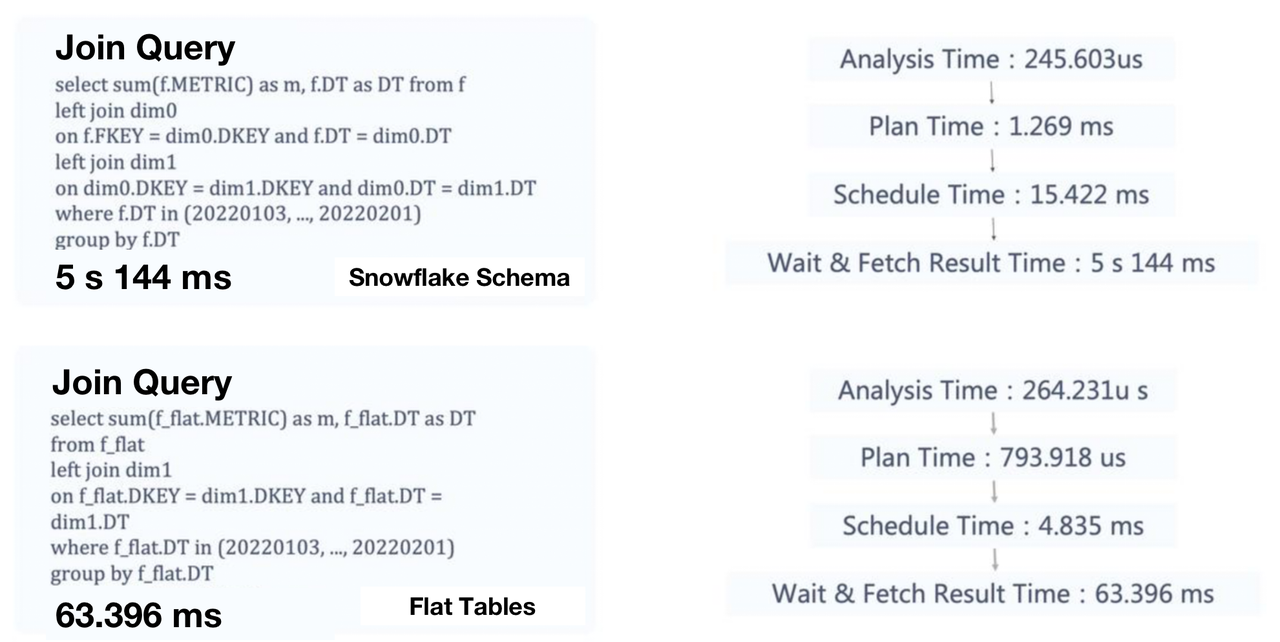
The flat table solution also eliminates jitter.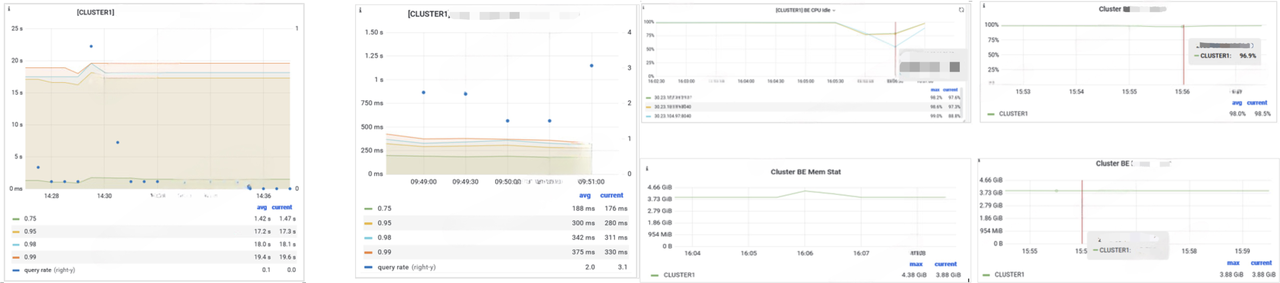
Enable SQL Caching To Reduce Resource Consumption
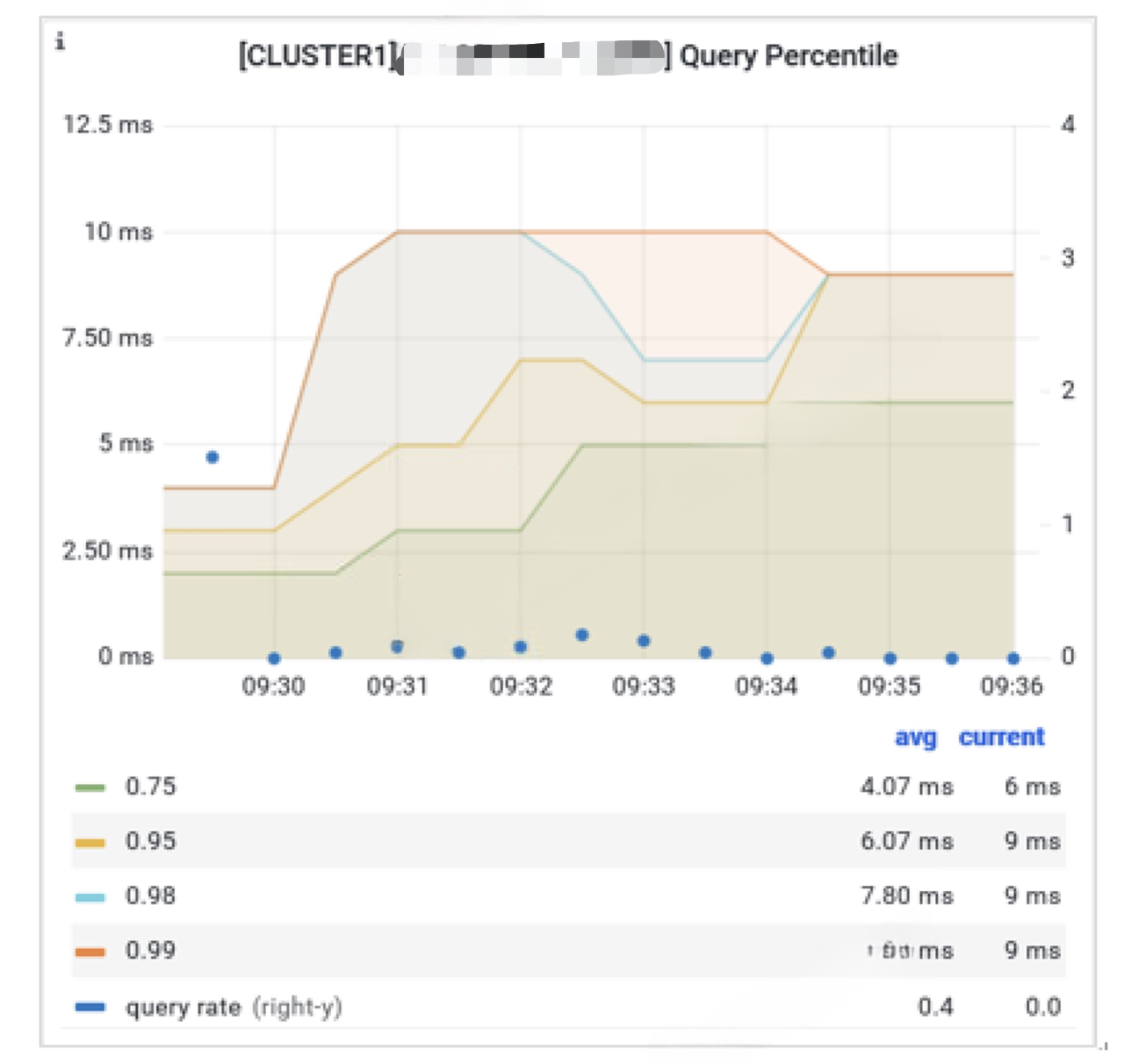
Analysts often check data reports of the same metrics on a regular basis. These reports are produced by the same SQL, so one way to further improve query speed is SQL caching. Here is how it turns out in a use case with SQL caching enabled.
- All queries are responded within 10ms;
- When computing 30 metrics simultaneously (over 120 SQL commands), results can be returned within 600ms;
- A TPS (Transactions Per Second) of 300 is reached, with CPU, memory, disk, and I/O usage under 80%;
- Under the recommended cluster size, over 10,000 metrics can be cached, which means you can save a lot of computation resources.
Conclusion
The complexity of data analysis in the financial industry lies in the data itself other than the engineering side. Thus, the underlying data architecture should focus on facilitating the unified and efficient management of data. Apache Doris provides the flexibility of simple metric registration and the ability of fast and resource-efficient metric computation. In this case, the user is able to handle 10,000 active financial metrics in 10,000 dashboards with 30% less ETL efforts.
Published at DZone with permission of Shirley H.. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments