Data Streaming for AI in the Financial Services Industry (Part 2)
Learn the data streaming strategies to lay a solid foundation for AI, moving from chaos and going into order for data strategies.
Join the DZone community and get the full member experience.
Join For FreeThe batch pipeline, in my opinion, is not going away. The system still needs it for business intelligence applications and data visualization. These reports often involve processing significant historical data. While iterative processing could be considered, it’s likely that with advancements in processing power and machine learning algorithms, there will always be a need to rebuild the data model from scratch.
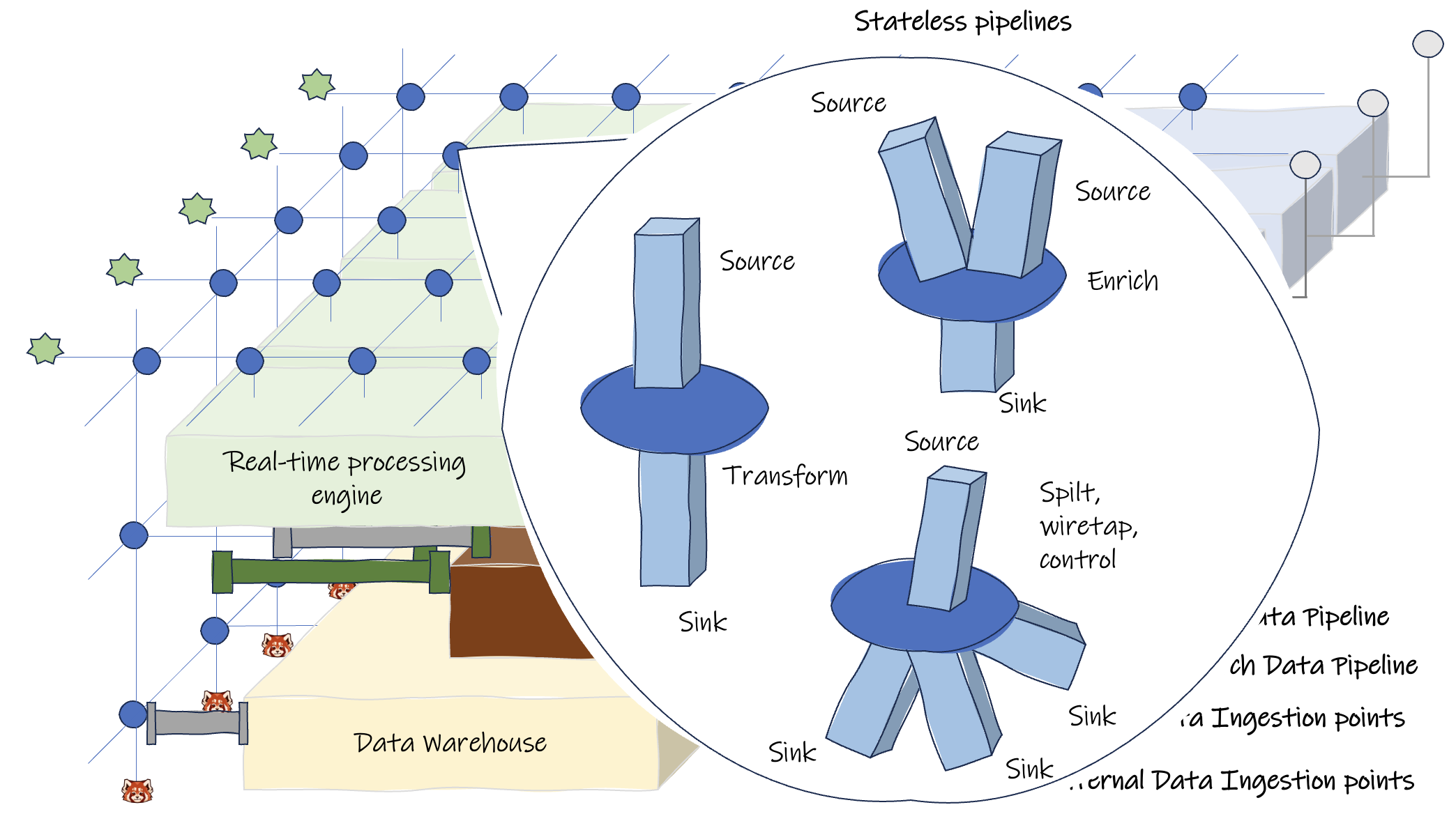
This approach will ensure the agility of the data layer and help solve the challenges we covered in our previous post.
Difficulty Accessing Data
- Data engineers can retrieve data in real-time by accessing the streaming network and the operational database.
- Having a more stateless pipeline that caters to special data shape demands and can process data as it comes requires a less complex pipeline.
- Masking sensitive data before distributing it.
Noisy and Dirty Data
- Validating data for its shape and context on the fly avoids future problems.
- Checks for duplication and mismatches can be distributed to be processed before saving it to the data warehouse. This prevents unclean data.
Performance
- A high throughput, reliable streaming platform capable of quickly retrieving historical events avoids pipeline congestion and process bottlenecks.
- Scaling with stateless pipelines and distributing jobs in stateful pipelines can horizontally scale out.
Troubleshooting
- With data modeled and available from different streams, it’s easier to detect problems by monitoring and sampling them with alerts.
- Simpler to isolate problematic data relating to pipelines consuming from the same streaming endpoint.
- Pre-cleaned data before it enters the data warehouse.
Summary
When it comes to generating datasets for training machine learning models, streaming data is better suited for continuous training and testing. However, it can be challenging to prepare datasets for ML model training from different types of data stores that were introduced throughout the years. Implementing a proven data strategy can streamline your troublesome data pipelines for real-time data ingestion, efficient processing, and seamless integration of disparate systems.
Next, I’ll walk you through a use case where we implement these data strategies to leverage generative AI for an insurance claim. We’ll also use Redpanda as our streaming data platform—a simpler, more performant, and cost-effective Kafka alternative. This use case will be nicely packaged in a free, downloadable report (coming soon!), so make sure you subscribe to our newsletter to be the first to know.
In the meantime, if you have questions about this topic or need support getting started with Redpanda for your own AI use case, you can chat with me in the Redpanda Community on Slack.
Published at DZone with permission of Christina Lin, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments