Data Platform: Building an Enterprise CDC Solution
Learn how to design and build a change data capture solution.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
This article is a follow-up to the Data Platform series where we describe how to design and build a new Data Platform:
As we said in previous articles, the data is the most important resource of a Data Platform. We have to design and plan how to ingest the data into the new Data Platform.
In this article, we are going to talk about a Change Data Capture (CDC) solution. How to design a standard replication solution, based on open-source tools like Debezium and why CDC can help us to migrate to the new Data Platform.
What Is Change Data Capture (CDC)
Change Data Capture is a software process that captures changes (DDL & DML) made in a source database to synchronize another data repository such as database, in-memory-cache, data warehouse, or data lake. CDC is used in other interesting and complimentary use cases that will not be discussed in this article, such as:
- CQRS Pattern: One of the implementations involves having separate write (commands) and read (queries) databases and data models. The writing layer supports inserts, updates, and deletes operations and the reading layer supports query data operation. CDC allows us to replicate command operations from the write database to the read database.
- Analytics Microservices: To provide changes event stream to track when and what changes occur and analyze behaviors pattern.
CDC solution is composed of three main components:
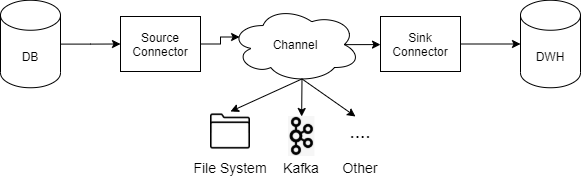
- Source Connector: It captures the changes from a database and produces events with the details of these changes.
- Channel: It is the data repository where the source connector persists these events with the changes.
- Sink Connector: Read the events from the channel and process applying the specific logic to consolidate the data to the target system or other purposes such as analytics alerting processes.
There are several methods to implement a CDC such as Log-based, Trigger-based, or SQL Script-based. In this article, we focus on Log-based because it is the more efficient method. We describe what are the advantages of this method later.

The events published by the source connector contain all the information required to synchronize the remote data repository. It is composed of the following:
- Metadata: Provides information such as table name, operation type (insert, delete, ..), transaction identifier, the timestamp when the change was made or captured by the source connector.
- Before Value: The data values before the change.
- After Value: The data values after the change.
{
"table":"stock"
"operation": "update",
"ts_ms" : "1627817475",
"transaction_id": 2,
"before" : {
"id" : "0001",
"item" : "T-Shirt",
"quantity" : "10"
},
"after" : {
"id" : "0001",
"item" : "T-Shirt",
"quantity" : "5"
}
}Not all connectors have the same behavior. There are some connectors such as the official MongoDB connector that do not provide "Before Value".

In the case of the data replication, these events are consumed by the sink connector and consolidated in the target database. The events must be consumed in the order that they were generated to ensure the resilience of the process.
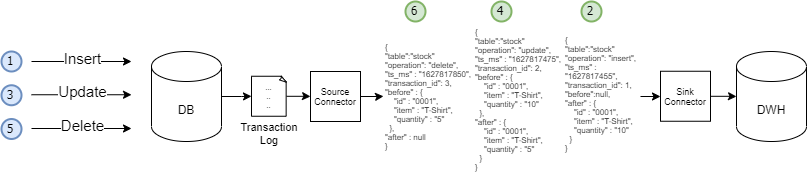
In case the events are not consumed in order, we can not ensure the replication process resilience. The following is an example of some of the scenarios that can happen:

In scenarios other than replication, based on an event-driven pattern and where we want to react to a specific event, it is not important to consume the events in order.
Log-Based CDC Advantages
Log-based CDC provides several advantages over other CDC methods or ETL replication processes.
- Performance: All changes are retrieved from the transaction log file by reading this file. This operation has less impact on the database performance than other approaches like ETLs. ETL approach consumes a lot of computing resources because is based on SQL queries and requires continuous optimization (indexes, partitions, etc.).
- Decouple Data Extraction: It provides decoupled data extraction compute layer, isolated from the rest of the workloads. This solution allows us to scale vertical and horizontal just on the CDC solution. Triggers CDC approach uses the database compute layer so the replication process can impact the performance of the database.
- Near Real-Time: Low computing impact allows us to provide near real-time change events without risks for the source databases. Detect changes in an ordered file is easier and faster than a query polling process on the tables.
- Capture all the changes: The transaction logs provide all the data changes, including the delete operations, in the exact order. ETL process misses intermediary data changes that happen between ETL executions. Identify delete operations with other approaches (ETLs, CDC Trigger Based, CDC SQL) requires creating tables to register this operation, and specific logic to guarantee the data resilience.
- Not Impact on the Data Model and Applications: This does not require changes on the data model or source applications. ETLs and other CDC solutions require creating triggers, tables, or add a timestamp audit column to the tables.
There are several important details to take into account:
- No-logging Transactions Operations: No all the operations are registered on the transaction log. There are operations at the catalog level commonly used in Data Warehouses such as partition movement between target tables and temporal tables. This type of operation depends on each database version and how the teams work.
- Commercial Tools: Each database vendor provides a CDC-specific tool, usually this is with an additional license. In a complex multi-vendor environment, having different CDC tools to replicate the data increases the operational cost.
- Open-Source Tools: They are a good option as will be explained below. Usually need more time to be updated with the new features that are released by the database vendor. Sometimes, the support for troubleshooting or bug resolution is more complex.
- AntiPattern: There are scenarios where a specific source database has to be replicated to many target databases. Sometimes the teams configure several CDC replications, all of them reading from the same transaction log. This is a dangerous antipattern. Low-impact does not mean no-impact, CDC increases the I/O operations therefore to have many CDC reading from the same file can increase a lot the I/O operations and generate an I/O performance problem. Using a hub and spoke patterns is a better approach.
Hub-and-Spoke CDC Pattern (Data Hub)
Hub-and-spoke architecture is one of the most common architectural patterns for data integration. This architecture allows us to capture the changes from the database once and deliver them many times. This pattern is very similar to the publish-subscribe pattern used by Apache Kafka and other streaming platforms. It provides several benefits such as:
- Reusability: The change events are read once from the source database and consumed many times by sink-connectors.
- Reduces the Number of Integrations: There is only one integration with the source database.
- Standard Interface: It provides the same interface for all consumers. In this case, sink-connectors replicate the data in the target databases sharing the same interface.

Depending on the features of the channel, it will allow us to provide some Data Hub functionalities. Data retention is a fundamental feature for a Data Hub. If we can not store all the historical data or even the last state of each document or row, we will have to complement the solution with other tools and processes.
Common Scenarios for CDC
There are four common scenarios where CDC is a good solution:
- OLAP Database Migrations: In the cases that we are migrating all or a piece of the workload from the current Data Warehouse to the new OLAP solution. CDC allows us to replicate the same data to both systems and make the migration easier. Nowadays, many companies are migrating workloads from OnPremise Data Warehouses to Data Cloud solutions.
- Replicate Information from OLTP Database to OLAP Database: To replicate data from our operational database to the Data Warehouse or the Data Lake.
- Database as a service: To provide a replica of our databases for analytics sandbox or preproduction sandbox.
- Migration from Monolithic to Microservices: To apply the strangler-fig-pattern to incrementally migrate our monolithic application to microservices. Replicating some datasets that are required for the coexistence of the two applications in the first stages.

Enterprise CDC Solution Proposal
We have described how a CDC process behaves, as well as the components that make it up. Based on this, we propose the following solution architecture:
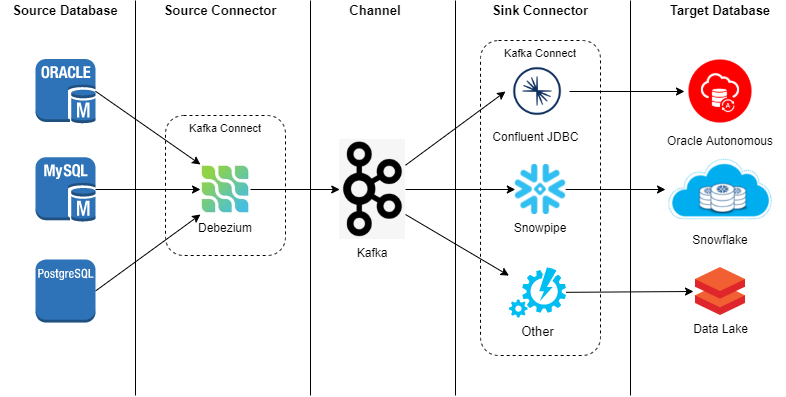
- Debezium as the Source Connector: This piece will be in charge of reading the changes from our source database engine and sending them to the channel. It will deploy as a connector in our Kafka Connect Cluster.
- Kafka as the Channel: It provides intermediate storage along with an extensive API for event production/consumption and large ecosystem connectors that can be deployed on Kafka Connect or in another platform.
- Kafka Sink JDBC (by Confluent) with Event flattering SMT (by Debezium) as the Sink Connector: This connector allows us to perform replication on the target database, with a few configurations parameters. It is a good choice as a generic solution for a global purpose. In other cases such as Snowflake or other cloud services, JDBC connector has poor cost-effectiveness and worst performance than other strategies offered by the vendor itself. It is important to evaluate the cost-benefit of switching to a connector offered by the vendor itself instead of using the generic JDBC.
- Kafka Connect as Connector Platform: It provides a framework to deploy connectors as a plugin based on a simple configuration and fully integrated with our Kafka. It is a very good choice because allows us standardized sink/source connector management such as Debezium replication operations and JDBC sink connector.
Debezium
It is an open-source solution that provides very interesting features to capture changes in our databases. Debezium provides some advantages to our architecture such as:
Event standardization is one of the important advantages of using a product like Debezium compared to specific database vendor solutions. Usually, each vendor solution has a different event specification because these solutions were mainly designed to replicate databases from the same vendor. In scenarios where the replication processes from or to multiple database products, having several event specifications increases the complexity of our solution in terms of operation, maintainability, and coding. Debezium provides a common, clear, and simple event specification that facilitates integrations with other third-party products such as Kafka Connect sink connectors.
Let's look at an event example (trimmed for readability):
{
"after": {
"field_id": 1,
"field_1": "Value 1"
},
"before": null,
"op": "c",
"source": {
"connector": "mysql",
"db": "inventory",
"name": "mysqldb",
"snapshot": "false",
"table": "product",
"ts_ms": 1627489969029,
"version": "1.6.1.Final",
(... other source vendor fields ...)
},
"transaction": null,
"ts_ms": 1627489969200
}- after: A document with the table columns and his values. Can be null, for example in delete operations.
- before: A document with the table columns and his values. Can be null, for example in create (insert) operations.
- op: The operation run in the database such as update, insert or delete.
- source: Metadata of the event. This document has common information, but it has several fields depending on our source database (Oracle, SqlServer, MySQL, or PostgreSQL).
- source.ts_ms: Indicates the time that the change was made in the database.
- ts_ms: Epoch timestamp when Debezium process this event and it is different from the source.ts_ms. By comparing these values, we can determine the lag between the source database update and Debezium.
Debezium is fully integrated with the Kafka ecosystem. The source connector uses the Kafka API to publish the changes events but also can be deployed as a Kafka Connector. We can deploy it in our Kafka Connet cluster using a REST API that simplifies the deployment and the management of the new CDC source connectors.
{
"name": "debezium-postgres-inventory-connector",
"config": {
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"tasks.max": "1",
"database.hostname": "postgres",
"database.port": "5432",
"database.user": "postgres",
"database.password": "postgres",
"database.dbname": "postgres",
"database.server.name": "postgresdb",
"schema.include": "inventory",
"table.include.list": "inventory.product"
}
}In this example, we deploy a new Debezium source connector in a PostgreSQL database and enable the capture of the changes from the product table on the inventory schema. The connector reads the changes and pushes the events into the Kafka topic "postgres.inventory.product".
There are commons connection properties although each Debezium database connector has specifics configurations attributes and options. As a common option, we can perform on first configuration a snapshot of the database into Kafka or disable it. These common configuration properties join to the Kafka Connector API provide us a standard management source connectors layer that simplifies the operation of our solution.
Things to take into account
There are several Debezium connectors, not all of them provide the same features:
- MongoDB.
- MySQL.
- PostgreSQL.
- Oracle.
- Etc.
It is important to review each one before making a decision, because in some cases it could be better the vendor connector, for example:
- Debezium MongoDB Source Connector: Currently, it is not able to send the current state of the document, only the operation in an idempotent format.
- Debezium SQL Server Source Connector: It is not a log-based connector but trigger-based and it requires installing a trigger procedure and creates a stage table.
Kafka
Kafka is a good choice to provide the channel capabilities because gives us several important features such as:
- Scalable Event Streaming Platform: It is highly configurable to provide high availability, low latency, high performance, several deliveries, and durability guarantees.
- Pub/Sub Pattern: It facilitates the mechanism to publish once and consume many, offering a good backpressure system where each consumer works at the rate they can or we want to provide.
- Large Ecosystem: Nowadays is used by thousands of companies. There are many open-source and commercial tools for data pipelines, streaming analytics, and data integration.
- Infinite Storage and Retention: Provide a centralized platform with limitless storage and retention. Some features recently provided by Confluent allow us to have a better cost-effectiveness storage tier uncoupling storage and compute resources.
The Debezium CDC events are published in a Kafka topic. A Kafka event is composed of three parts:
- Key: It is used to determine the partition where a message will be appended. Events with the same event key are written to the same partition. Kafka guarantees that the partition's events will be read by any consumer in the exactly same order as they were written.
- Value: It contains the event itself.
- Headers: It is metadata associated with the Kafka record and provides extra information on the key/value pair.
As a key, Debezium includes the key fields of the table. This allows us to process the changes events in the same order as they occurred in the database.

Topic Strategy
There are two strategies for the publication of our events:
- One topic per table.
- One topic per database or the pair of database and schema.
The best strategy depends on the characteristics of our environment, both solutions have advantages and disadvantages. The main problem of the "one-topic-per-table" strategy is the number of topics and partitions required. Kafka has a partition limit per cluster so this strategy is not recommended when we have many databases with hundreds or thousands of tables.
Performance
There are two levels of parallelism in this solution:
- Based on the number of target databases.
- The throughput of a specific target database.
Kafka provides a pub/sub pattern and this allows us to deploy several sink connectors to process the events and replicate the information from a topic to several target databases in parallel. To increase the throughput of each sink connector, we need to combine two components:
- The number of topic partitions.
- The number of consumers in a Kafka consumer group. Each sink connector is associated with a specific and unique consumer group. A consumer unity is like a thread or task in the case of Kafka connector.
The members of a resource group divide the partitions so that a partition is only consumed by a consumer of the group, and that consumer will read the events for a key in order. Based on this, we can use a Kafka Connect to process the events that affect each key to replicate the state in another target database, like a Data Warehouse with a simple configuration, for example:
{
"name": "jdbc-sink",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector",
"tasks.max": "1",
"topics": "postgres.inventory.product",
"connection.url": "jdbc:dwhdriver://connection",
"transforms": "unwrap",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.unwrap.drop.tombstones": "false",
"auto.create": "true",
"insert.mode": "upsert",
"delete.enabled": "true",
"pk.fields": "id",
"pk.mode": "record_key"
}
}One connector can read more than one topic and can be scalable in tasks that work as a consumer group. Working with the properties defined in this config, we can perform a replica of the source, or maybe only append the events as a historic evolution to perform some analytical process.
Data Retention
The Kafka data retention is managed at the topic level and there are different strategies:
- Time retention: Kafka broker removes periodically the old events when time is exceeded.
- Size retention: Kafka broker removes periodically the old events when the size of the topic is exceeded.
- Unlimited.
As a new and interesting feature, Confluent provides tiered storage: we can send warm data to cost-effective object storage, and scale brokers only when need more compute resources. This enables infinite storage capacities, which may be desirable in some use cases where data history must be kept for a long time.
Retention by the time or size is not the only capacity of Kafka to define a cleanup policy. We can define a compact policy, where the Kafka broker periodically removes the events, keeps only the last event for each key, and removes the key when the last event has null as s value.
The compacting policy is a very interesting feature for CDC solutions. It allows us to keep the last event of a row or document. This means that we have the last consolidated value but we lost the history of changes.

The compact cleanup policy is an expensive operation for the broker, but it allows us to clean old events keeping the last state of the database, with the advantage that if we need a new consumer after one year, do not need to process a year of events.
Conclusions
In complex environments with large volumes of data and a wide variety of technologies, providing data to the new data platform is a big challenge. But the real challenge is to provide this data while ensuring the quality that the organization needs to make valuable decisions.
Accuracy, consistency, uniqueness, or timeliness are some of the metrics to measure our Data Quality. In our opinion, the CDC instead of other solutions allows us to standardize data ingestion and ensure data quality in a relatively simple way.
As we said in other articles, standardization, and automation are the keys to improve the quality of any process.
Opinions expressed by DZone contributors are their own.
Comments