Building an Event-Driven Architecture Using Kafka
Building an event-driven architecture using Kafka enables real-time data streaming, seamless integration, and scalability for applications and systems.
Join the DZone community and get the full member experience.
Join For FreeEvent-driven architecture (EDA) is a software design pattern that focuses on the generation, detection, and consumption of events to enable efficient and scalable systems. In EDA, events are the central means of communication between components, allowing them to interact and respond to changes in real time. This architecture promotes loose coupling, extensibility, and responsiveness, making it well-suited for modern, distributed, and highly scalable applications. EDA has emerged as a powerful solution to enable agility and seamless integration in modern systems.
In an event-driven architecture, events represent significant occurrences or changes within a system. Various sources, such as user actions, system processes, or external services, can generate these events. Components, known as event producers, publish events to a central event bus or broker, which acts as a mediator for event distribution. Other components, called event consumers, subscribe to specific events of interest and react accordingly.
One of the key advantages of event-driven architecture is its ability to enable agility and flexibility. Components in an event-driven system can evolve independently, allowing for easier maintenance, updates, and scalability. New functionalities can be added by introducing new event types or subscribing to existing events without affecting the overall system. This flexibility and extensibility make event-driven architecture particularly suitable for dynamic and evolving business requirements.
EDA also facilitates seamless integration between different systems or services. By using events as a communication mechanism, EDA enables interoperability regardless of the underlying technologies or programming languages. Events provide a standardized and loosely coupled way for systems to exchange information, enabling organizations to integrate disparate systems more easily. This integration approach promotes modularity and reusability, as components can be connected or disconnected without disrupting the entire system.
Key Components of an Event-Driven Architecture: Enabling Event Flow and Processing
An event-driven architecture (EDA) consists of several key components that enable the flow and processing of events within a system. These components work together to facilitate event generation, distribution, consumption, and processing. Here are the key components of an event-driven architecture:
Event Producers
Event producers are responsible for generating and publishing events. They can be various entities within the system, such as user interfaces, applications, microservices, or external systems. Event producers capture significant occurrences or changes and emit events to the event bus or broker. These events can be triggered by user actions, system events, sensor data, or any other relevant source.
Event Bus/Broker
The event bus or broker acts as a central communication channel for events. It receives events published by the event producers and distributes them to interested event consumers. The event bus/broker can be a message queue, a publish-subscribe system, or a specialized event streaming platform. It ensures reliable event delivery, decoupling event producers from consumers and enabling asynchronous event processing.
Event Consumers
Event consumers subscribe to specific events or event types of interest. They receive events from the event bus/broker and process them accordingly. Event consumers can be various components within the system, such as microservices, workflows, or data processors. They react to events by executing business logic, updating data, triggering further actions, or communicating with other systems.
Event Handlers
Event handlers are responsible for processing events received by event consumers. They contain the business logic and rules to execute specific actions based on the event content. Event handlers can perform data validation, state changes, database updates, trigger notifications, or invoke additional services. They encapsulate the behavior associated with a particular event and ensure proper event processing within the system.
Event Store
The event store is a persistent data storage component that records all published events in the system. It provides a historical record of events and their associated data. The event store enables event replay, auditing, and event sourcing patterns, allowing the system to rebuild its state based on past events. It supports scalability, fault tolerance, and data consistency in an event-driven architecture.
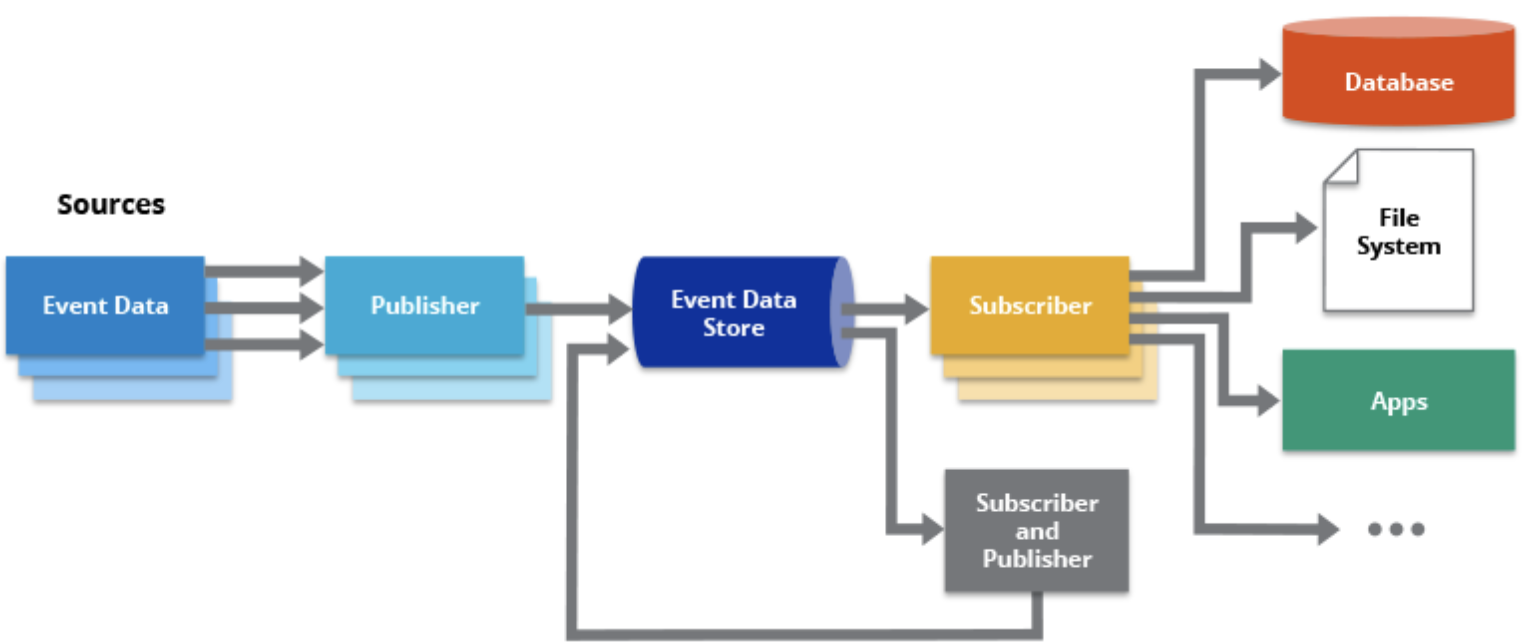
By leveraging these key components, an event-driven architecture enables the smooth flow, distribution, and processing of events within a system. The event producers, event bus/broker, event consumers, event handlers, and event store work together to create a loosely coupled, scalable, and responsive system that can handle real-time event-driven interactions, adapt to changing requirements, and integrate with external systems or services.
Patterns of Event-Driven Architecture: Structuring Systems for Scalability and Autonomy
Event-driven architecture (EDA) offers several patterns that help structure systems for scalability and autonomy. These patterns enhance the ability to handle many events, decouple components, and enable independent development and deployment. Here are some key patterns of event-driven architecture:
Event Sourcing
Event sourcing is a pattern where the state of an application is derived from a sequence of events. Instead of storing the current state, all changes to the application's state are captured as a series of events in an event store. The application can rebuild its state by replaying these events. Event sourcing enables scalability and audibility as it provides a complete history of events, allows for fine-grained querying, and enables easy replication and scaling of event processors.
Command-Query Responsibility Segregation (CQRS)
CQRS is a pattern that separates the read and writes operations into separate models. The write model called the command model, handles commands that change the state of the system and produce events. The read model, called the query model, handles queries and updates its own optimized view of the data. CQRS allows independent scaling of read and write operations, enhances performance by optimizing the read model for specific query needs, and provides flexibility to evolve each model independently.
Pub/Sub (Publish/Subscribe)
The pub/sub pattern enables loose coupling and scalability by decoupling event producers from event consumers. In this pattern, event producers publish events to a central event bus or broker without knowing which specific consumers will receive them. Event consumers subscribe to specific types of events they are interested in, and the event bus/broker distributes the events to the relevant subscribers. This pattern enables flexibility, extensibility, and the ability to add or remove consumers without impacting event producers or other consumers.
Event-driven Messaging
Event-driven messaging involves the exchange of messages between components based on events. It enables asynchronous communication and loose coupling between components. In this pattern, event producers publish events to message queues, topics, or event hubs, and event consumers consume these events from the messaging infrastructure. This pattern allows components to work independently, improves system scalability, and enables reliable and asynchronous event processing.
By employing these patterns, systems can be structured to handle scalability and autonomy effectively. Event sourcing, CQRS, pub/sub, and event-driven messaging patterns promote loose coupling, enables independent scaling of components, provide fault tolerance, enhance performance, and support the seamless integration of systems and services in an event-driven architecture. These patterns contribute to building resilient, scalable, and adaptable systems that can handle large volumes of events while maintaining high levels of autonomy for individual components.
Kafka: Powering Real-Time Data Streams and Event-Driven Applications
Kafka is a distributed streaming platform that is widely used for building real-time data streams and event-driven applications. It is designed to handle high volumes of data and provide low-latency, scalable, and fault-tolerant stream processing. Kafka enables the seamless and reliable flow of data between systems, making it a powerful tool for building event-driven architectures.
At its core, Kafka uses a publish-subscribe model where data is organized into topics. Producers write data to topics, and consumers subscribe to those topics to receive the data in real time. This decoupled nature of Kafka allows for the asynchronous and distributed processing of events, enabling applications to handle large volumes of data and scale horizontally as needed.
Kafka's distributed architecture provides fault tolerance and high availability. It replicates data across multiple brokers, ensuring that the data is durable and accessible even in the event of failure. Kafka also supports data partitioning, allowing for parallel processing and load balancing across multiple consumers. This makes it possible to achieve high throughput and low latency when processing real-time data streams.
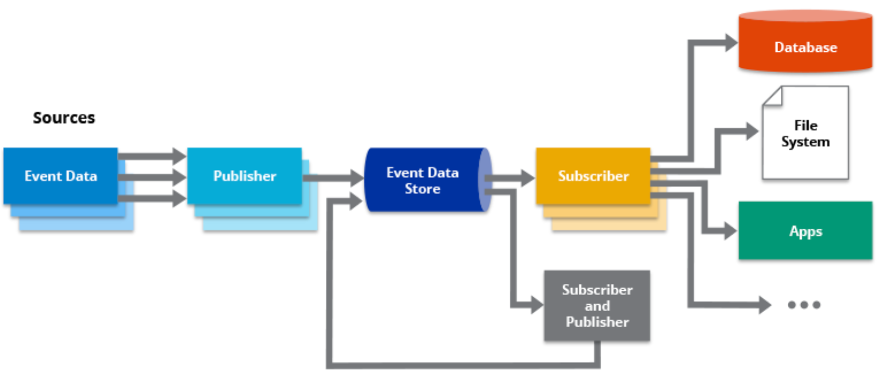
Furthermore, Kafka integrates well with other components of the event-driven architecture ecosystem. It can act as a central event bus, enabling seamless integration and communication between different services and systems. Kafka Connect provides connectors for integrating with various data sources and sinks, simplifying the integration process. Kafka Streams, a stream processing library built on top of Kafka, allows for real-time processing and transformation of data streams, enabling complex event-driven applications to be built with ease.
Building a Kafka Event-Driven Architecture: Step-by-Step Guide
Kafka has emerged as a powerful streaming platform that enables the development of robust and scalable event-driven architectures. With its distributed, fault-tolerant, and high-throughput capabilities, Kafka is well-suited for building real-time data streaming and event-driven applications. Following are steps to build a Kafka event-driven architecture, from design to implementation.
Step 1: Define System Requirements
Start by clearly defining the goals and requirements of event-driven architecture. Identify the types of events that need to capture, the desired scalability and fault tolerance, and any specific business needs or constraints.
Step 2: Design Event Producers
Identify the sources that generate events and design event producers that can publish these events on Kafka topics. Whether it's applications, services, or systems, ensure that the events are properly structured and contain relevant metadata. Consider using Kafka producer libraries or frameworks to simplify the implementation.
Sample Python code to create producers:
from kafka import KafkaProducer
# Kafka broker configuration
bootstrap_servers = 'localhost:9092'
# Create Kafka producer
producer = KafkaProducer(bootstrap_servers=bootstrap_servers)
# Define the topic to produce messages to
topic = 'test_topic'
# Produce a message
message = 'Hello, Kafka Broker!'
producer.send(topic, value=message.encode('utf-8'))
# Wait for the message to be delivered to Kafka
producer.flush()
# Close the producer
producer.close()
Step 3: Create Kafka Topics
Define the topics in Kafka that will serve as the channels for event communication. Carefully plan the topic structure, partitioning strategy, replication factor, and retention policy based on the anticipated load and data requirements. Ensure that topics align with the granularity of events and support future scalability.
Step 4: Design Event Consumers
Determine the components or services that will consume and process events from Kafka. Design event consumers that subscribe to the relevant topics and perform real-time processing. Consider the number of consumers required and design consumer applications accordingly.
Sample Python code to create consumers:
from kafka import KafkaConsumer
# Kafka broker configuration
bootstrap_servers = 'localhost:9092'
# Create Kafka consumer
consumer = KafkaConsumer(bootstrap_servers=bootstrap_servers)
# Define the topic to consume messages from
topic = 'test_topic'
# Subscribe to the topic
consumer.subscribe(topics=[topic])
# Start consuming messages
for message in consumer:
# Process the consumed message
print(f"Received message: {message.value.decode('utf-8')}")
# Close the consumer
consumer.close()
Step 5: Implement Event Processing Logic
Write the event processing logic within consumer applications. This can involve data transformation, enrichment, aggregation, or any other business-specific operations. Leverage Kafka's consumer group functionality to distribute the processing load across multiple instances and ensure scalability.
Step 6: Ensure Fault Tolerance
Implement fault tolerance mechanisms to handle failures and ensure data durability. Configure a suitable replication factor for Kafka brokers to provide data redundancy. Implement error handling and retry mechanisms in consumer applications to handle exceptional scenarios.
Step 7: Monitor and Optimize Performance
Set up monitoring and observability tools to track the health and performance of Kafka cluster and event-driven applications. Monitor critical metrics such as throughput, latency, and consumer lag to identify bottlenecks and optimize the system. Consider leveraging Kafka's built-in monitoring features or integrating with third-party monitoring solutions.
Step 8: Integrate with Downstream Systems
Determine how an event-driven architecture will integrate with downstream systems or services. Design connectors or adapters to enable seamless data flow from Kafka to other systems. Explore Kafka Connect, a powerful tool for integrating with external data sources or sinks.
Step 9: Test and Iterate
Thoroughly test event-driven architecture to ensure its reliability, scalability, and performance. Conduct load testing to validate the system's behavior under different workloads. Iterate and refine the design based on test results and real-world feedback.
Step 10: Scale and Evolve
As the system grows, monitor its performance and scale it accordingly. Add more Kafka brokers, adjust partitioning strategies, or optimize your consumer applications to handle increased data volumes.
Use Cases of Kafka Event-Driven Architecture
Kafka's event-driven architecture has found applications in various domains due to its ability to handle high throughput, fault tolerance, and real-time data streaming. Here are some common use cases where Kafka excels:
- Real-time Data Processing and Analytics: Kafka's ability to handle high-volume, real-time data streams makes it an ideal choice for processing and analyzing large-scale data. Organizations can ingest data from multiple sources into Kafka topics and then process and analyze it in real-time using streaming frameworks like Apache Flink, Apache Spark, or Kafka Streams. This use case is valuable in scenarios such as real-time fraud detection, monitoring IoT devices, clickstream analysis, and personalized recommendations.
- Event-driven Microservices Architecture: Kafka acts as a communication backbone in microservices architectures, where different services communicate through events. Each microservice can act as an event producer or consumer, allowing for loosely coupled and scalable architectures. Kafka ensures reliable and asynchronous event delivery, enabling services to operate independently and handle events at their own pace. This use case is beneficial for building scalable and decoupled systems, enabling agility and autonomy in microservices-based applications.
- Log Aggregation and Stream Processing: Kafka's durability and fault-tolerant nature make it an excellent choice for log aggregation and stream processing. By publishing log events to Kafka topics, organizations can centralize logs from various systems and perform real-time analysis or store them for future auditing, debugging, or compliance purposes. Kafka's integration with tools like Elasticsearch and Apache Hadoop ecosystem enables efficient log indexing, searching, and analysis.
- Messaging and Data Integration: Kafka's publish-subscribe model and distributed nature make it a reliable messaging system for integrating different applications and systems. It can serve as a data bus for transmitting messages between systems, enabling decoupled and asynchronous communication. Kafka's connectors allow seamless integration with other data systems such as relational databases, Hadoop, and cloud storage, enabling data pipelines and ETL processes.
- Internet of Things (IoT): Kafka's ability to handle massive volumes of streaming data in a fault-tolerant and scalable manner is well-suited for IoT applications. It can ingest and process data from IoT devices in real time, enabling real-time monitoring, anomaly detection, and alerting. Kafka's low-latency characteristics make it an excellent choice for IoT use cases where quick response times and real-time insights are critical.
These are just a few examples of the wide range of use cases where Kafka's event-driven architecture can be applied. Its flexibility, scalability, and fault tolerance make it a versatile platform for handling streaming data and building real-time, event-driven applications.
Conclusion
Kafka's event-driven architecture has revolutionized the way organizations handle data streaming and build real-time applications. With its ability to handle high-throughput, fault-tolerant data streams, Kafka enables scalable and decoupled systems that empower agility, autonomy, and scalability. Whether it's real-time data processing, microservices communication, log aggregation, messaging integration, or IoT applications, Kafka's reliability, scalability, and seamless integration capabilities make it a powerful tool for building event-driven architectures that drive real-time insights and enable organizations to harness value of their data.
Opinions expressed by DZone contributors are their own.
Comments