Data Mapping Best Practices | A Brief Guide to Types, Approaches, and Tools
In this post, I'll share data mapping best practices in regards to data migration and data integration – the types of data mapping, approaches, and common tools.
Join the DZone community and get the full member experience.
Join For FreeMapping data between software applications is a time-consuming process that requires in-depth preparation and strategy, good knowledge of data sources and targets, and depending on your approach, hands-on development.
In any application integration, data migration, and in general, any data management initiative, data mapping is one of the most critical steps. One could even argue that the integrations project success depends largely on correct mapping of source to target data.
So, let’s review what the data mapping best practices are: the types, the common approaches as well as some useful data mapping tools.
First Things First: What Does Data Mapping Mean?
In essence, data mapping is the process of connecting data fields from a source system (business application or database) to a target system.
Many applications share the same pattern of naming common fields on the frontend but under the hood, these same fields can have quite different labels. Consider the field “Customers”: in the source code of your company’s CRM, it might still have the label “customers”, but then your ERP system calls it “clients”, your finance tool calls it “customer” and the tool your organization uses for customer messaging will map it “users” altogether. This is one of the probably most common data mapping examples for this label conundrum.
To add to the complexity, what if a two-field data output from one system is expected as a one-field data input in another or vice versa? This is what commonly happens with First Name / Last Name; a certain customer “Allan” “McGregor” from your eCommerce system will need to become “Allan McGregor” in your ERP. Or my favorite example: the potential customer email address submitted through your company’s website will need to become “first-name: Steven”, "last-name: Davis” and “company: Rangers” in your customer relationships management tool. Now, it’s not about just mapping the related data fields; we’re talking about data transformation ON TOP of it.
Now imagine we have dozens of business application modules and processes (business partners, leads, sales orders, payment slips, invoices, products, customer data, etc.) with numerous various data fields that must all flow seamlessly from one system to the next. It’s easy to comprehend why data integrations projects can take months to complete with the costs sometimes spiraling out of control.
What Are the Types of Data Mapping?
Especially when it comes to complex projects, there are two types of data mapping to be considered:
- Logical data mapping is a more high-level, conceptual phase of the project.
- Physical data mapping is an implementation-oriented, rather hands-on phase.
Logical data mapping can be regarded as the first step in data modeling. It can be part of the conceptual model, where we identify real-life objects and match these with the organization-related concepts, for example, grouping product information, product order history, and product availability into a single concept “Product”.
In more complex data management projects, the logical phase can be separated from the conceptual model. In this case, it will follow the latter, and our task will be to define logical entities within the organization, assign attributes to each of them and establish relationships between these entities, thus building a holistic logical data model of the entire business that represents all of its entities.
For the sake of keeping things simple, we’ll stick to a very basic scenario where we need to map data only between one source and one target system. The illustration below shows a very simplified version of a logical data model for such a scenario. The rules defined at this stage apply more to logical concepts than to the actual implementation, but they serve as a foundation for a more thorough physical data mapping.
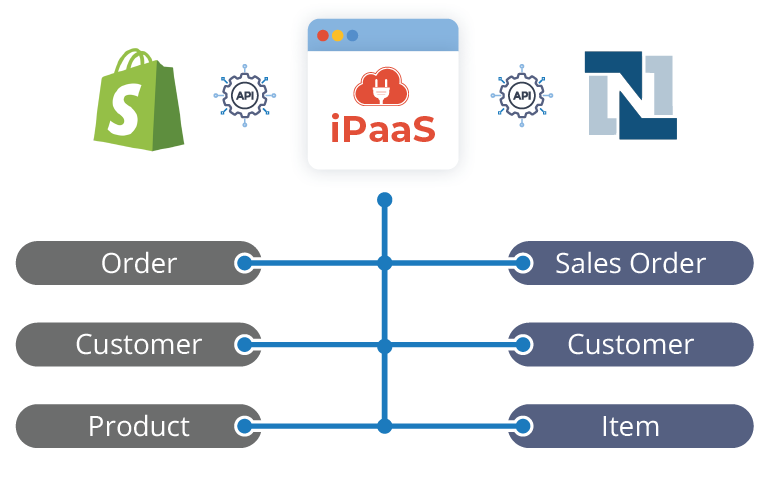
Following the completion of the logical data model, we can start with the physical data model that is based on the actual nomenclature of data objects in the source and the target systems. Particularly in larger teams, this information should be as specific and detailed as possible to avoid unnecessary errors and project delays. This is how our logical data mapping example from above will look like when moved to this next phase:
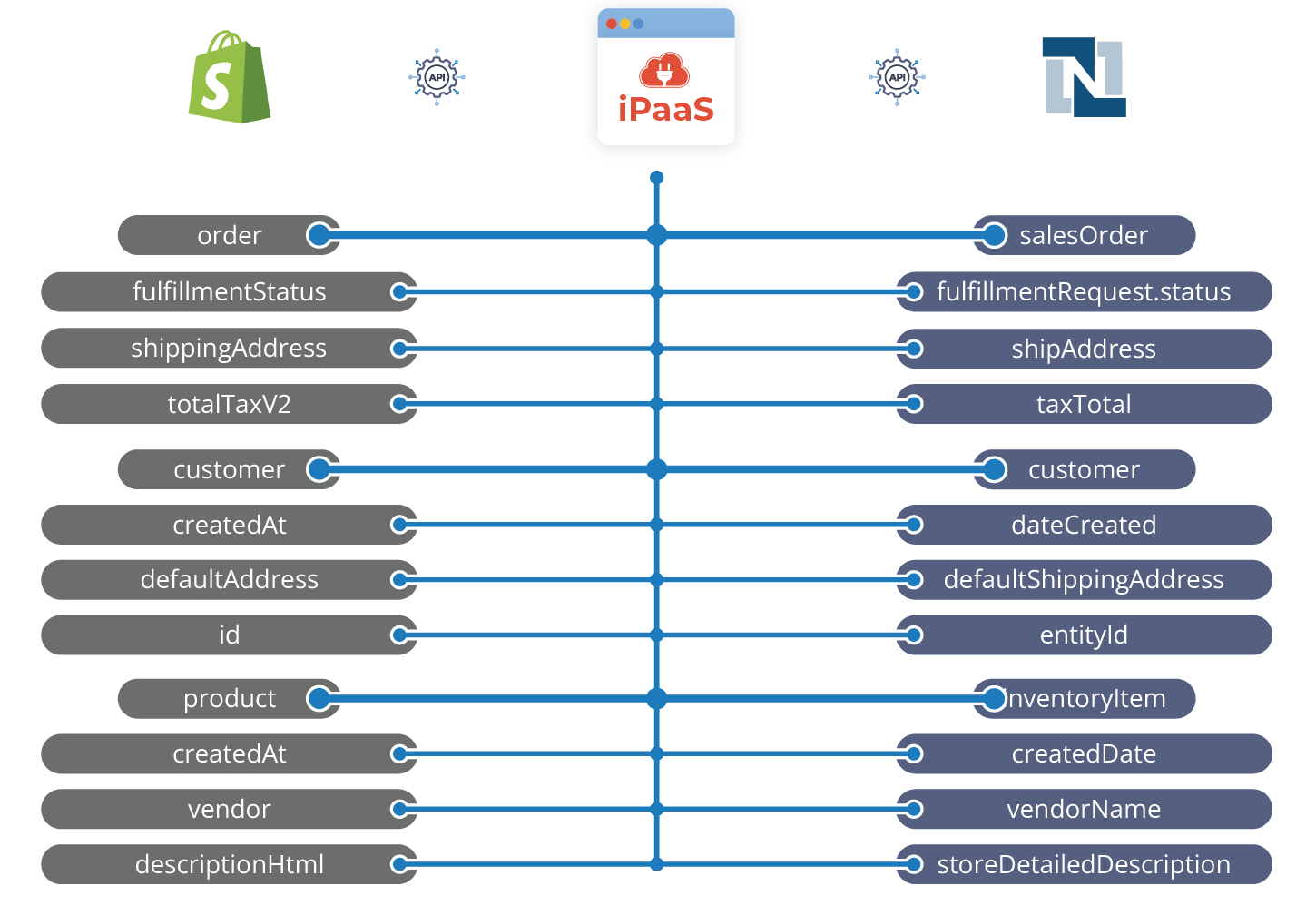
There are several interesting resources on this topic. One of them we can recommend, even though it is not 1-to-1 translatable to the mapping between business applications, is the book “Data Mapping for Data Warehouse Design”. Generally, implementing the data mapping project following these phases should be considered as data mapping best practices. The better this process is planned out and documented, the easier and faster it will be to carry out.
Three Common Approaches to Data Mapping
As you might have already deduced from the section above, data mapping requires at least some technical understanding. How much exactly depends on your data mapping approach. In general, there are three approaches to choose from:
- Manual
- Semi-automated
- Fully automated
Each of these has its pros and cons.
Manual Data Mapping
This is undoubtedly a discipline for itself because it requires not only a more than a good understanding of the transformation rules and programming languages, but also enough manpower and time resources to create maps, document each step as well as perform subsequent updates and changes as the number of software systems to connect grows.
Pros
With this approach, you can be one hundred percent sure that the implementation is completely tailored to your business needs and requirements. Also, you’re not dependent on any third-party tools.
Cons
It’s time-consuming, extremely code-heavy, and prone to errors. Should your expert data mapper be no longer part of your team at some point, their successor might have a hard time understanding how the mapping has been done.
Semi-Automated Mapping
Sometimes also called schema mapping, this is an approach where you would use a software tool that helps link together similar data schemas without requiring extensive developer involvement. For this purpose, the tool will compare the schemas of the source and target systems and generate a relationships map, which is then reviewed by a developer who makes any necessary changes. Similar to the manual approach, there can be an output code that is generated by the tool in the relevant coding language.
Pros
This approach still gives the developers a lot of flexibility but is at the same timeless time-consuming compared to the manual approach.
Cons
It equally requires quite a high level of coding skills plus switching between manual and automated operations is still resource-intensive.
Fully-Automated Mapping
This is probably the most mainstream approach, meaning that there is an entire class of products and tools that promote an automated low/no-code approach to data integration and thus, data mapping. Such tools feature a drag-and-drop or click-and-select graphical interfaces that are easy to understand and to use not only for seasoned coders and IT architects but also for junior developers and even line-of-business users, making the process of data mapping much more accessible to everyone. Some modern tools even feature NLP (natural language processing) capabilities to match data fields entirely automatically.
Pros
Saves developers a lot of time and is accessible to a much wider range of IT staff since it requires less in-depth technical knowledge; easy to scale and comes with a number of useful capabilities for data integration projects (scheduling, various deployment options, pre-built templates, etc.).
Cons
It is a third-party tool that an organization will become dependent on, onboarding usually requires at least some level of training, and the costs can grow very quickly depending on the pricing model of a respective vendor.
What Tools Are Used for Data Mapping?
The answer to this question depends on your approach.
Semi-Automated Approach
If you decided to go for the semi-automated, or schema mapping approach, these are a few data mapping tools that draw our attention by being featured in several community discussions and research papers:
Clio
A research prototype tool was developed at IBM’s Almaden Research Center. It allows for mapping between a relational and an XML schema and supports the languages XQuery, XSLT 1.0, SQL, and SQL/XML.
MapForce2005
It is part of Altova’s XML suite of tools; just like Clio, MapForce2005 was designed specifically for schema mapping and generating transformation queries.
Stylus Studio 6
A Progress Software’s XML development environment that focuses on XQuery / XSLT visualization and transformation.
Oracle Warehouse Builder 10g Release 1
A data warehouse development tool based on Oracle’s 10g database system. The ETL (Extract, Transform, Load) process, which has a schema mapping step, is part of it. This tool is representative of many ETL solutions that are currently available on the market.
Fully-Automated Approach
The data mapping tools that fall into this category never come isolated. By that, I mean that data mapping is only one capability out of a comprehensive set of tools delivered within one product. This makes sense: If you want to automate the data mapping process, why would you want to keep every other element of the data management tasks manual?
Considering this, when you go for the low/no-code approach to data mapping and, hence, data management, there are two questions you should ask yourself before any tool evaluation, namely – who will be the target user and what are your future plans with respect to automation of data exchange in general?
The answers to these questions will largely influence your search strategy. You might go for a 100% no-code solution such as Zapier for your line-of-business users or for the very basic automation scenarios. For complex automation tasks and your fellow IT team members, you might prefer a low-code iPaaS solution, which still provides high levels of automation but leaves enough room for flexibility and freedom.
What To Look For in Data Mapping Tools
Before we wrap up this topic, let’s briefly go through the main capabilities and features that good data mapping tools should provide:
- An intuitive no-code or low-code mapping interface Remember: It’s not about one being better than the other; it’s about your personal requirements and target users.
- Support for various structured data formats (CSV, XML, JSON, etc) as well as, ideally, unstructured and semi-structured ones.
- Syntax and error check during the validation.
- Support for conditional (e.g. content-based) and rule-based mapping.
- Built-in data transformation capabilities during mapping.
- The ability to run tests and debug with sample data.
Conclusion
Mapping data between software applications is a time-consuming process that requires in-depth preparation and strategy, good knowledge of data sources and targets, and, depending on your approach, hands-on development. And let’s be honest: Even with the so-called “fully-automated” approach, data mapping is not really “fully” automated.
A developer might still be required to, for example, validate and correct the mapping results. But these are still the tools that help reduce manual involvement to the minimum, thus freeing up valuable resources for other mission-critical tasks.
Published at DZone with permission of Olga Annenko, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments