Optimizing Your Data Pipeline: Choosing the Right Approach for Efficient Data Handling and Transformation Through ETL and ELT
ETL and ELT are vital for data integration and accessibility. Learn how to select the right approach based on your infrastructure, data volume, data complexity, and more.
Join the DZone community and get the full member experience.
Join For FreeEditor's Note: The following is an article written for and published in DZone's 2024 Trend Report, Data Engineering: Enriching Data Pipelines, Expanding AI, and Expediting Analytics.
As businesses collect more data than ever before, the ability to manage, integrate, and access this data efficiently has become crucial. Two major approaches dominate this space: extract, transform, and load (ETL) and extract, load, and transform (ELT). Both serve the same core purpose of moving data from various sources into a central repository for analysis, but they do so in different ways. Understanding the distinctions, similarities, and appropriate use cases is key to perfecting your data integration and accessibility practice.
Understanding ETL and ELT
The core of efficient data management lies in understanding the tools at your disposal. The ETL and ELT processes are two prominent methods that streamline the data journey from its raw state to actionable insights. Although ETL and ELT have their distinctions, they also share common ground in their objectives and functionalities.
Data integration lies at the heart of both approaches, requiring teams to unify data from multiple sources for analysis. Automation is another crucial aspect, with modern tools enabling efficient, scheduled workflows, and minimizing manual oversight. Data quality management is central to ETL and ELT, ensuring clean, reliable data, though transformations occur at different stages.
These commonalities emphasize the importance of scalability and automation for developers, helping them build adaptable data pipelines. Recognizing these shared features allows flexibility in choosing between ETL and ELT, depending on project needs, to ensure robust, efficient data workflows.
Key Differences Between and Considerations for Choosing ETL or ELT
ETL is traditionally suited for on-premises systems and structured data, while ELT is optimized for cloud-based architectures and complex data. Choosing between ETL and ELT depends on storage, data complexity, and specific business needs, making the decision crucial for developers and engineers.
Table 1. Infrastructure considerations for ETL vs. ELT
| Aspect |
ETL |
ELT |
| Infrastructure location | On-premise systems | Cloud-based systems |
| Data storage environment | Traditional data warehouses | Modern cloud data warehouses |
| Cost model | Substantial upfront investment in hardware and software | Lower upfront cost with the pay-as-you-go model |
| Scalability | Fixed capacity: scale by adding more services | Elastic scaling: automatic resource allocation |
| Data type compatibility | Suited for structured, relational databases with defined schemas | Suited for unstructured or semi-structured data |
| Data volume | Small- to -medium-scale datasets | Large-scale dataset across distributed systems |
| Processing power | Limited by on-prem hardware | Virtually unlimited from cloud services |
| Data transformation process | Data transformation before loading | Data loaded first, transformations occur after in the cloud |
The order of operations is the fundamental distinction between ETL and ELT processes:
- In ETL, the data is extracted from the source, then transformed according to predefined rules and schemas, and finally loaded into the target storage location. This ensures that only structured and validated data enters the warehouse.
- In contrast, ELT focuses on data lakes for raw data storage, modern data warehouses that accommodate both raw and transformed data, NoSQL databases for unstructured data analysis, and analytics platforms for real-time insights.
Processing time is determined by the sequence of operations:
- With its up-front transformations, ETL might experience longer processing times before data is ready for analysis. Using an ETL process, a company can transform data to standardized formats, validate customer identities, and filter out incomplete transactions. It can take several hours to prepare the data before an analytics team can start their work. If a sudden change in customer behavior occurs (e.g., during a sale), the delay in processing might hinder the timely decision.
- By loading data first and transforming it later, ELT can offer faster initial loading times, although the overall processing time might depend on the complexity of transformations. For example, a company can load raw transaction and customer behavior data directly into a cloud-based data lake without upfront transformations. While the initial loading is fast, they need robust error handling to ensure that the subsequent transformations yield accurate and meaningful insights.
When it comes to data storage:
- ETL typically relies on staging areas or intermediate data stores to store the transformed data before it's loaded into the final destination. Using an ETL process, an organization can first stage data from various sources in an intermediate data warehouse, and then they can perform transformations.
- ELT, on the other hand, often loads raw data directly into a data lake or cloud data stores, capitalizing on their vast storage capabilities. Transformations then happen within this environment. For example, a company loads raw data directly into a cloud-based data lake, which allows researchers to begin analyzing the data immediately.
The data complexity and your flexibility needs also determine which process will work best for your use case:
- ETL is well suited for structured data that adheres to predefined schemas, making it ideal for traditional relational databases. Due to its predefined transformation rules, ETL might offer limited flexibility once the pipeline is set up.
- ELT shines when dealing with large volumes of unstructured or semi-structured data, which are common in modern data landscapes, and leverages the flexibility of cloud environments. By applying transformations after loading, ELT provides greater flexibility for iterative and exploratory data analysis, allowing for schema changes and evolving business requirements.
Data analysis requirements are important considerations when deciding between ETL and ELT:
- ETL is favored in scenarios requiring strict data governance and quality control, such as transactional processing where timely and accurate data is essential.
- ELT is more suited to exploratory data analysis and iterative processes as transformations can be applied after the data has been loaded, offering greater flexibility.
The timing of error handling differs in each case:
- In ETL, error handling is typically incorporated during the transformation phase, ensuring data quality before loading. For example, the data transformation phase checks for errors like invalid account numbers or missing transaction details. Any records with errors are either corrected or rejected before the clean data is loaded into the final database for analysis.
- In ELT, when an organization loads raw transaction data directly into a cloud data lake, error handling and validation occur during the transformation phase after the data is already stored. Therefore, ELT might require more robust error handling and data validation processes after the data is loaded into the target system.
When to Use ETL vs. ELT: Use Cases
Developers and engineers must choose between ETL and ELT based on their project needs.
Table 2. Use cases for ETL vs. ELT
| Extract, Transform, Load | Extract, Load, Transform |
| Legacy systems: Existing on-prem infrastructure set up for ETL; structured data, batch processing | Real-time processing: Need real-time or near-real-time processing |
| Smaller datasets: Low volume, low complexity; batch processing meets needs | Complex data types: Unstructured or semi-structured data; flexible, scalable processing after loading |
| Data governance: Strict regulatory compliance in industries (e.g., finance, healthcare); data quality is paramount and requires validation before loading | Big data and cloud environments: cloud-native infrastructure; big data platforms, distributed processing (e.g., Apache Hadoop or Spark) |
ETL Example: Financial Reporting System for a Bank
In a traditional financial institution, accurate, structured data is critical for regulatory reporting and compliance. Imagine a bank that processes daily transactions from multiple branches:
- Extract. Data from various sources — such as transactional databases, loan processing systems, and customer accounts — is pulled into the pipeline. These are often structured databases like SQL.
- Transform. The data is cleaned, validated, and transformed. For example, foreign transactions may need currency conversion, while all dates are standardized to the same format (e.g., DD/MM/YYYY). This step also removes duplicates and ensures that only verified, structured data moves forward.
- Load. After the transformation, the data is loaded into the bank's centralized data warehouse, a structured, on-premises system designed for financial reporting. This ensures that only clean, validated data is stored and ready for reporting.
Figure 1. ETL process for financial reporting in a bank
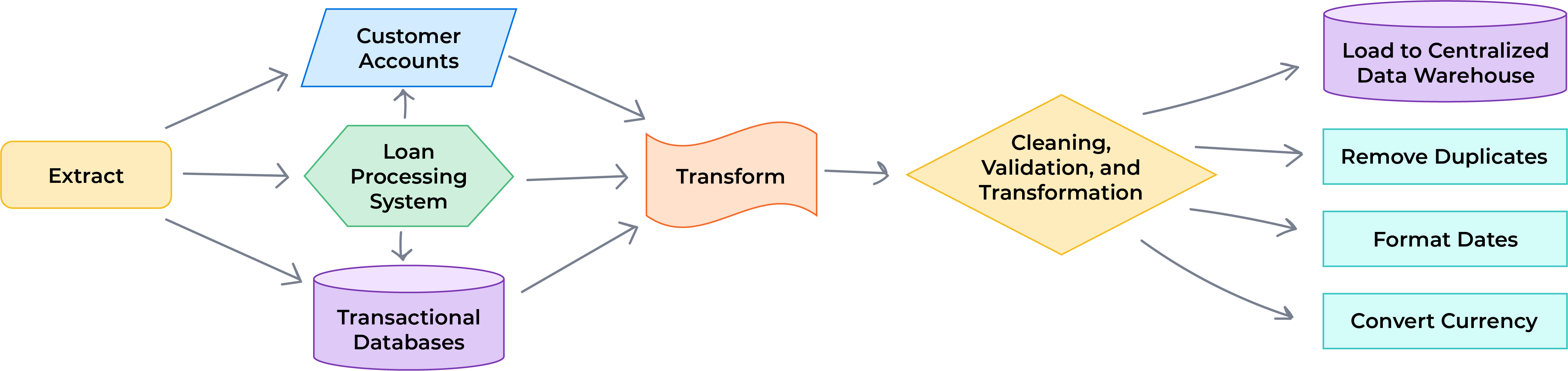
The bank's focus is on data governance and quality control, making ETL ideal for this scenario where accuracy is non-negotiable.
ELT Example: Real-Time Analysis for a Social Media Platform
A social media company dealing with massive amounts of unstructured data (e.g., user posts, comments, reactions) would leverage an ELT process, particularly within a cloud-based architecture. The company uses ELT to quickly load raw data into a data lake for flexible, real-time analysis and machine learning tasks.
- Extract. The platform extracts raw data from various sources, including weblogs, user activity, and interaction metrics (likes, shares, etc.). This data is often semi-structured (JSON, XML) or unstructured (text, images).
- Load. Instead of transforming the data before storage, the platform loads raw data into a cloud-based data lake. This allows the company to store vast amounts of unprocessed data quickly and efficiently.
- Transform. Once the data is loaded, transformations are applied for different use cases. For example, data scientists might transform subsets of this data to train machine learning models, or analysts might apply business rules to prepare reports on user engagement. These transformations happen dynamically, often using the cloud's scalable computing resources
In this ELT scenario, the platform benefits from the flexibility and scalability of the cloud, allowing for real-time analysis of massive datasets without the upfront need to transform everything. This makes ELT perfect for handling big data, especially when the structure and use of data can evolve.
To further illustrate the practical applications of ETL and ELT, consider the following diagram:
Figure 2. ELT process for real-time analysis on a social media platform

Conclusion
Both ETL and ELT play vital roles in data integration and accessibility, but the right approach depends on your infrastructure, data volume, and business requirements. While ETL is better suited for traditional on-premises systems and well-structured data, ELT excels in handling large, complex data in cloud-based systems. Mastering these approaches can unlock the true potential of your data, enabling your business to derive insights faster, smarter, and more effectively.
As data ecosystems evolve, ELT will likely dominate in large-scale, cloud-based environments where real-time analysis is key. ETL, however, will remain vital in sectors that prioritize data governance and accuracy, like finance and healthcare. Hybrid solutions may emerge, combining the strengths of both methods.
To get started, here are some next steps:
- Assess your infrastructure. Determine whether ETL or ELT better suits your data needs.
- Try new tools. Explore different platforms to streamline your pipelines.
- Stay flexible. Adapt your strategy as your data requirements grow.
By staying agile and informed, you can ensure your data integration practices remain future ready.
This is an excerpt from DZone's 2024 Trend Report,
Data Engineering: Enriching Data Pipelines, Expanding AI, and Expediting Analytics.
Read the Free Report
Opinions expressed by DZone contributors are their own.
Comments