Column Store Database Benchmarks: MariaDB ColumnStore vs. ClickHouse vs. Apache Spark
An in-depth comparison looking at the query performance of MariaDB ColumnStore, ClickHouse, and Apache Spark.
Join the DZone community and get the full member experience.
Join For FreeThis blog shares some column store database benchmark results and compares the query performance of MariaDB ColumnStore v. 1.0.7 (based on InfiniDB), Clickhouse, and Apache Spark.
I’ve already written about ClickHouse (Column Store database).
The purpose of the benchmark is to see how these three solutions work on a single big server with many CPU cores and large amounts of RAM. Both systems are massively parallel (MPP) database systems, so they should use many cores for SELECT queries.
For the benchmarks, I chose three datasets:
- Wikipedia page Counts, loaded full with the year 2008, ~26 billion rows.
- Query analytics data from Percona Monitoring and Management.
- Online shop orders.
This blog post shares the results for the Wikipedia page counts (same queries as for the ClickHouse benchmark). In the following posts, I will use other datasets to compare the performance.
Databases, Versions and Storage Engines Tested
- MariaDB ColumnStore v. 1.0.7, ColumnStore storage engine.
- Yandex ClickHouse v. 1.1.54164, MergeTree storage engine.
- Apache Spark v. 2.1.0, Parquet files and ORC files.
Although all of the above solutions can run in a “cluster” mode (with multiple nodes), I’ve only used one server.
Hardware
This time, I’m using newer and faster hardware:
- CPU: physical = 2, cores = 32, virtual = 64, hyperthreading = yes.
- RAM: 256Gb.
- Disk: Samsung SSD 960 PRO 1TB, NVMe card.
Data Sizes
I’ve loaded the above data into ClickHouse, ColumnStore, and MySQL (for MySQL the data included a primary key; Wikistat was not loaded to MySQL due to the size). MySQL tables are InnoDB with a primary key.


Query Performance
Wikipedia page counts queries:




Partitioning and Primary Keys
All of the solutions have the ability to take advantage of data “partitioning” and to only scan needed rows.
ClickHouse has “primary keys” (for the MergeTree storage engine) and scans only the needed chunks of data (similar to partition “pruning” in MySQL). No changes to SQL or table definitions are needed when working with ClickHouse.
ClickHouse example:
:) select count(*), toMonth(date) as mon
:-] from wikistat where toYear(date)=2008
:-] and toMonth(date) = 1
:-] group by mon
:-] order by mon;
SELECT
count(*),
toMonth(date) AS mon
FROM wikistat
WHERE (toYear(date) = 2008) AND (toMonth(date) = 1)
GROUP BY mon
ORDER BY mon ASC
┌────count()─┬─mon─┐
│ 2077594099 │ 1 │
└────────────┴─────┘
1 rows in set. Elapsed: 0.787 sec. Processed 2.08 billion rows, 4.16 GB (2.64 billion rows/s., 5.28 GB/s.)
:) select count(*), toMonth(date) as mon from wikistat where toYear(date)=2008 and toMonth(date) between 1 and 10 group by mon order by mon;
SELECT
count(*),
toMonth(date) AS mon
FROM wikistat
WHERE (toYear(date) = 2008) AND ((toMonth(date) >= 1) AND (toMonth(date) <= 10))
GROUP BY mon
ORDER BY mon ASC
┌────count()─┬─mon─┐
│ 2077594099 │ 1 │
│ 1969757069 │ 2 │
│ 2081371530 │ 3 │
│ 2156878512 │ 4 │
│ 2476890621 │ 5 │
│ 2526662896 │ 6 │
│ 2460873213 │ 7 │
│ 2480356358 │ 8 │
│ 2522746544 │ 9 │
│ 2614372352 │ 10 │
└────────────┴─────┘
10 rows in set. Elapsed: 13.426 sec. Processed 23.37 billion rows, 46.74 GB (1.74 billion rows/s., 3.48 GB/s.)As we can see here, ClickHouse has processed ~2 billion rows for one month of data, and ~23 billion rows for ten months of data. Queries that only select one month of data are much faster.
For ColumnStore we need to re-write the SQL query and use “between ‘2008-01-01’ and 2008-01-10′” so it can take advantage of partition elimination (as long as the data is loaded in approximate time order). When using functions (i.e., year(dt) or month(dt)), the current implementation does not use this optimization. (This is similar to MySQL, in that if the WHERE clause has month(dt) or any other functions, MySQL can’t use an index on the dt field.)
ColumnStore example:
MariaDB [wikistat]> select count(*), month(date) as mon
-> from wikistat where year(date)=2008
-> and month(date) = 1
-> group by mon
-> order by mon;
+------------+------+
| count(*) | mon |
+------------+------+
| 2077594099 | 1 |
+------------+------+
1 row in set (2 min 12.34 sec)
MariaDB [wikistat]> select count(*), month(date) as mon
from wikistat
where date between '2008-01-01' and '2008-01-31'
group by mon order by mon;
+------------+------+
| count(*) | mon |
+------------+------+
| 2077594099 | 1 |
+------------+------+
1 row in set (12.46 sec)Apache Spark does have partitioning, however. It requires the use of partitioning with parquet format in the table definition. Without declaring partitions, even the modified query (“select count(*), month(date) as mon from wikistat where date between ‘2008-01-01’ and ‘2008-01-31’ group by mon order by mon”) will have to scan all the data.
The following table and graph show the performance of the updated query:


Working With Large Datasets
With 1Tb uncompressed data, doing a “GROUP BY” requires lots of memory to store the intermediate results (unlike MySQL, ColumnStore, ClickHouse and Apache Spark use hash tables to store groups by “buckets”). For example, this query requires a very large hash table:
SELECT
path,
count(*),
sum(hits) AS sum_hits,
round(sum(hits) / count(*), 2) AS hit_ratio
FROM wikistat
WHERE project = 'en'
GROUP BY path
ORDER BY sum_hits DESC
LIMIT 100As “path” is actually a URL (without the hostname), it takes a lot of memory to store the intermediate results (hash table) for GROUP BY.
MariaDB ColumnStore does not allow us to “spill” data on disk for now (only disk-based joins are implemented). If you need to GROUP BY on a large text field, you can decrease the disk block cache setting in columnstore.xml (i.e., set disk cache to 10% of RAM) to make room for an intermediate GROUP BY:
<DBBC>
<!-- The percentage of RAM to use for the disk block cache. Defaults to 86% -->
<NumBlocksPct>10</NumBlocksPct>In addition, as the query has an ORDER BY, we need to increase max_length_for_sort_data in MySQL:
ERROR 1815 (HY000): Internal error: IDB-2015: Sorting length exceeded. Session variable max_length_for_sort_data needs to be set higher.
mysql> set global max_length_for_sort_data=8*1024*1024;SQL Support
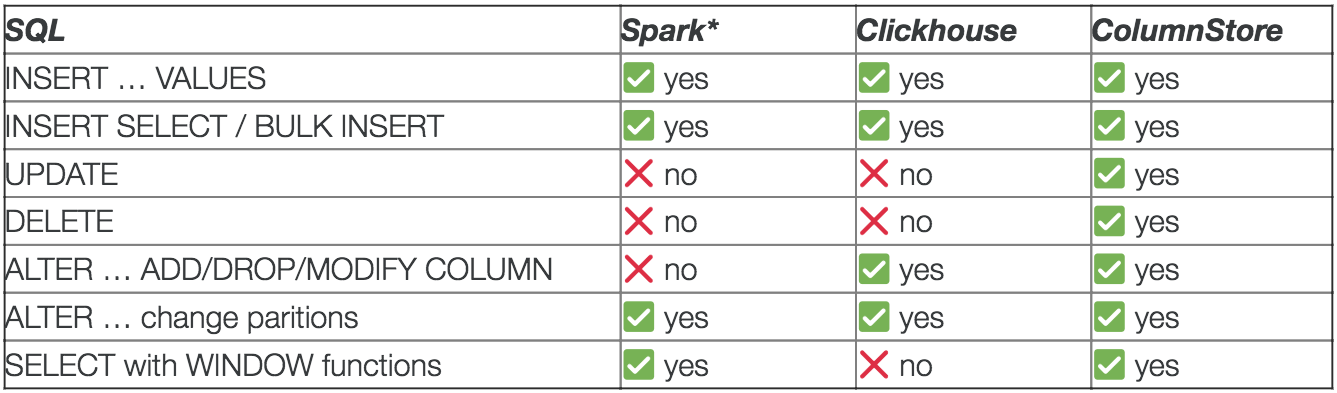
Spark does not support UPDATE/DELETE. However, Hive supports ACID transactions with UPDATE and DELETE statements. BEGIN, COMMIT, and ROLLBACK are not yet supported (only the ORC file format is supported).
ColumnStore is the only database out of the three that supports a full set of DML and DDL (almost all of the MySQL’s implementation of SQL is supported).
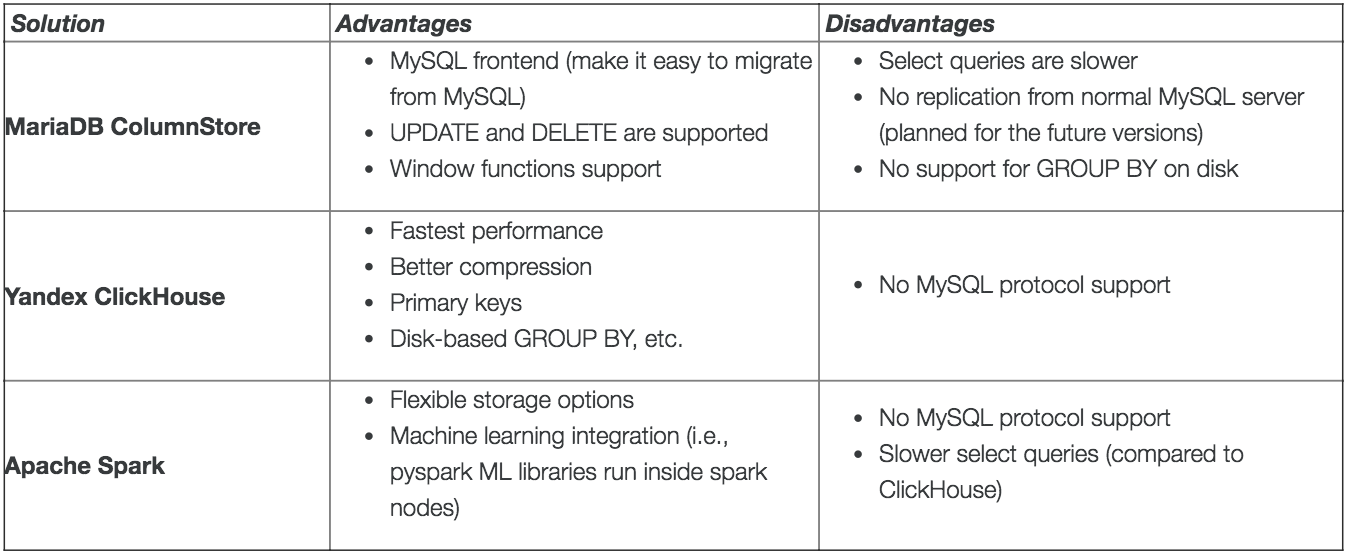
Comparing ColumnStore to ClickHouse and Apache Spark
Conclusion
Yandex ClickHouse is the winner of this benchmark. It shows both better performance (>10x) and better compression than MariaDB ColumnStore and Apache Spark. If you are looking for the best performance and compression, ClickHouse looks very good.
At the same time, ColumnStore provides a MySQL endpoint (MySQL protocol and syntax), so it is a good option if you are migrating from MySQL. Right now, it can’t replicate directly from MySQL but if this option is available in the future we can attach a ColumnStore replication slave to any MySQL master and use the slave for reporting queries (i.e., BI or data science teams can use a ColumnStore database, which is updated very close to real-time).
Published at DZone with permission of Alexander Rubin, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments