Automated Multi-Repo IBM App Connect Enterprise BAR Builds
This article shows the use of commodity tools and standard formats to enable industry-standard pipelines, whether the destination is integration nodes or containers.
Join the DZone community and get the full member experience.
Join For FreeThe IBM App Connect Enterprise (ACE) toolkit has long been used for application development and also for building BAR files to be deployed to integration nodes, with the IDE’s capabilities making it relatively simple to work with applications and libraries contained in multiple source repositories. The toolkit is not easily automated as such, however, and it may appear that the source layout must be reorganized before automation is possible: the command-line build tools lack some of the toolkit's project-handling capabilities and therefore present some challenges when working with complex source environments. Despite the challenges, this article shows an alternative to reorganization, with relatively little work being needed to allow for automation to proceed.
Quick summary: The toolkit presents a virtual filesystem based on projects, and the command-line equivalent is to fix up the extracted source during a build; a working example is shown below.
Motivation
Many long-standing ACE and IIB customers separate their storage of source code (containing application and library projects) from their storage of built artifacts (BAR files), with the BAR files being built by developers from source and then checked into an asset repository. The build process involves importing projects into the toolkit (from git, for example), building BAR files, deploying to a local server, testing to ensure that the applications work locally, and then pushing the BAR files to an asset repository (such as Artifactory).
Once the BAR files are available in the repository, the deployment pipeline starts, with the BAR files being deployed to several environments in turn: Development, Quality Assurance (QA), User Acceptance Test (UAT), Pre-Production, and Production are commonly-used names, but different organizations choose different names and number of stages. In almost all cases, however, each stage involves more validation before the deployment proceeds to the next stage. If QA is the first stage, then the picture might look as follows:
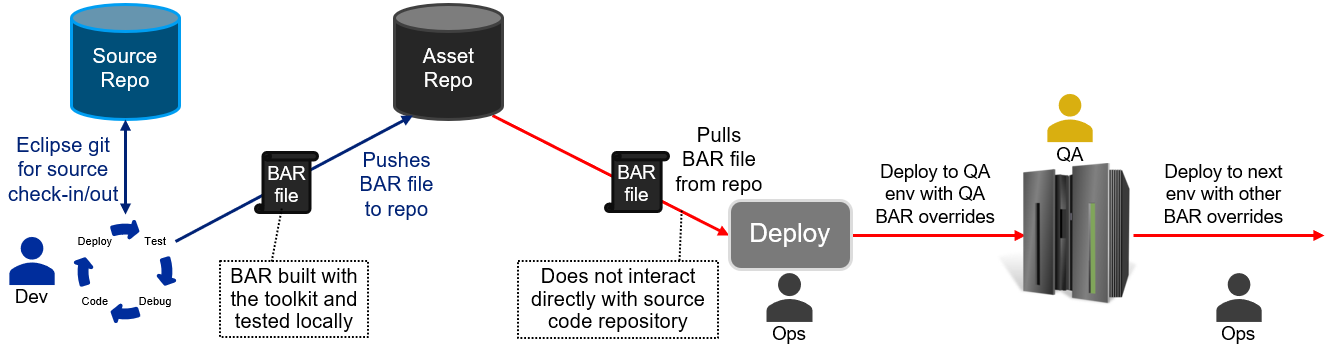
This pattern is common at least in part because it provides a great deal of assurance that the BAR file contains applications and libraries that work as expected: each stage will cover some aspects of testing to ensure that production deployment will result in successful operation. Many companies have automated much of the later stages, leading to efficient progression once the BAR files have been created, but this does not help the initial effort required on the left side of the picture: the initial stage involves manual effort, and this can reduce agility and increase time to deployment for changes.
This is especially true for changes that affect libraries used by multiple applications, as many application BAR files may need to be built, tested locally, and then pushed to the asset repository by developers. A new release of ACE may also trigger similar effort, as might a new fixpack in some cases, and as a result many organizations would prefer to automate the earlier stages as well.
One common pattern to achieve this is to have the BAR files built automatically from source control, and not have the developers build them: the automated builds create a BAR file and run unit tests, and then push the BAR file to the asset repository when everything has succeeded. Modifying the picture above to include this style of automation might look like this:
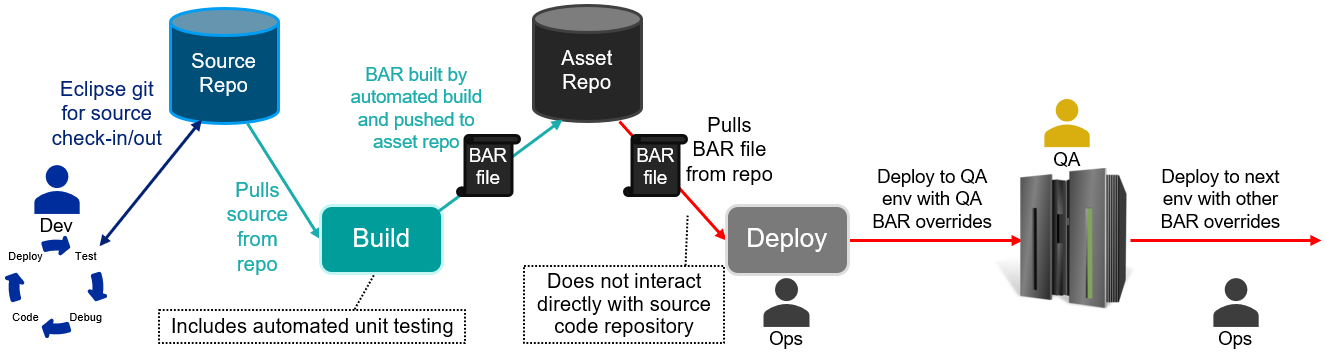
The introduction of an automated BAR build phase allows much more rapid build and testing of applications when an ACE release upgrade is planned or an application is changed, and is much closer to the industry-standard build pipelines for other languages. This style of pipeline would also work with container builds, where the BAR file is replaced by a container image containing the applications and libraries, with promotion through the various stages.
This approach works well in general, but can become complicated when applications share common libraries spread across multiple repositories: pulling source down from the repo and building it is easier when everything is in a single repository (like the ACE demo pipeline) and gets harder when portions of the source code must be downloaded from multiple repositories. (Note that while it is possible to distribute shared libraries as binary BARs using tools such as Maven, this approach does not work very well with static libraries, and this article assumes building from source in order to cover the widest range).
This article will not attempt to resolve the debates around “monorepo or multiple repos” (see ongoing internet arguments), but does recognize that it can be complicated to get BAR builds going in an automated way for complex project sets. We are deliberately ignoring the questions around deployment dependencies (“what if integration applications require different versions of a shared library?”) as those are liable to arise regardless of how automated the BAR build process might be. Even if we ignore those questions, however, there are still issues around the layout of the projects on disk, and these are covered in the next section.
Toolkit Virtual Project Folders
Consider an example set of repositories with an application and libraries in separate locations:
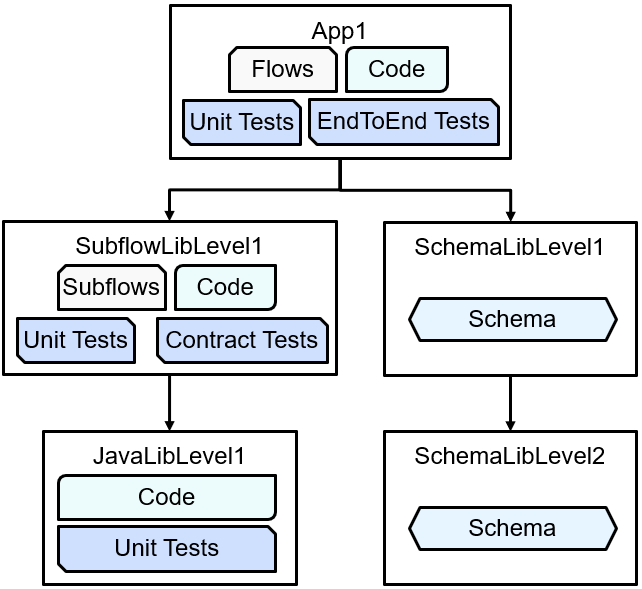
with each component in a separate git repo. This can be seen starting at the App1 repo and while the structure is relatively simple in that there are no “diamond dependencies” or anything else difficult, it can still illustrate one of the key issues around filesystem layout.
These repositories are linked using git subcomponents, where the parent repo has a subcomponent pointer to the child repo at a particular commit point. It is also possible to use Eclipse “Project Set” files to link the projects, or the Google “repo” tool, or git subtrees, but the basic principles are similar from an ACE point of view, at least as far as the toolkit is concerned. The Eclipse git plugin handles subcomponents as expected, with a “recursive” clone mode similar to that of the git command, but ACE command-line tools immediately start to run into problems: although the git command can extract the projects correctly, when the mqsicreatebar command is asked to build App1 it fails with errors such as
Referenced project "SubflowLibLevel1" does not exist on the file system
For the toolkit variant of this example, as long as the top-level application has been cloned with submodules as shown:
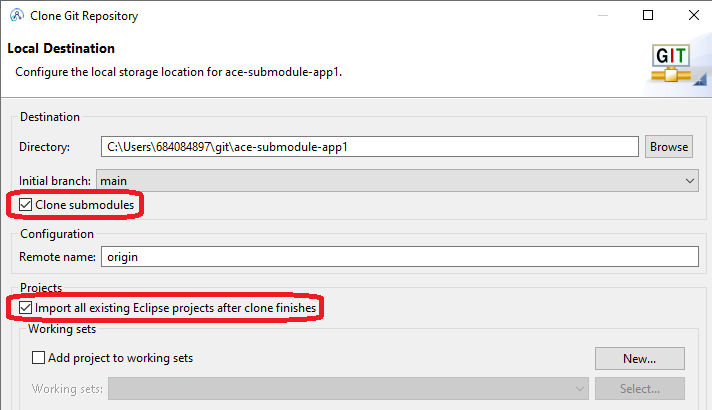
then the layout in the toolkit looks completely normal, with the projects appearing in the navigator as expected:
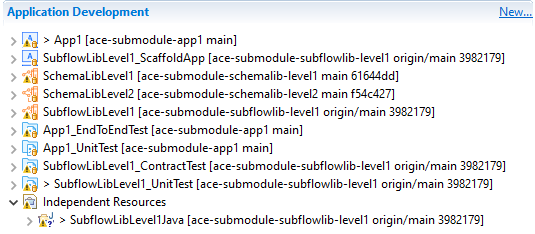
and BAR files can be built for App1 including the various libraries.
However, while the navigator looks clean and everything works as expected, what actually happens on disk is as follows (project directories in red):
ace-submodule-app1
├── ace-submodule-schemalib-level1
│ ├── ace-submodule-schemalib-level2
│ │ └── SchemaLibLevel2
│ └── SchemaLibLevel1
├── ace-submodule-subflowlib-level1
│ ├── ace-submodule-javalib-level1
│ │ └── JavaLibLevel1
│ ├── SubflowLibLevel1
│ │ └── SubflowLibLevel1
│ ├── SubflowLibLevel1_ContractTest
│ ├── SubflowLibLevel1_ScaffoldApp
│ └── SubflowLibLevel1_UnitTest
├── App1
├── App1_EndToEndTest
└── App1_UnitTest
The toolkit presents a virtual layout based on projects, regardless of where they may be on disk. As a result, organizations using the toolkit to build BARs find this works very well, as the toolkit handles all the complexity. While reality occasionally breaks through (some schema editor content-assist does not handle the relative paths correctly), in general this style of project is eminently usable in the toolkit.
Command-line builds, however, do not work as well: both ibmint and mqsicreatebar fail to find the projects in the subdirectories. This is not really a defect in the tools (rather showing instead how powerful the toolkit is in presenting a virtual project layout!) but is unhelpful in building automated BAR build pipelines.
Reorganizing Projects on Disk After Source Clone
Ideally, the pipeline would look something like this:

with the source checked out at the beginning, followed by building, testing, and then BAR packaging, all without manual effort; this is clearly not possible if the command-line tools are unable to understand the filesystem layout.
The solution in this case is to modify the layout on disk during the build so that it looks as follows:
ace-submodule-app1
├── ace-submodule-schemalib-level1
├── ace-submodule-subflowlib-level1
├── App1
├── App1_EndToEndTest
├── App1_UnitTest
├── JavaLibLevel1
├── SchemaLibLevel1
├── SchemaLibLevel2
└── SubflowLibLevel1
and then ibmint and mqsicreatebar will work as expected. Note only the required the projects are moved: the subcomponent tests are left where they were, as they are not being run at this level. The subcomponent tests would be run during the build for those components, but would not normally be run during application build (similar to library packages in other languages).
To achieve this, the example repo file build-and-ut.sh shows how this can be scripted without needing to encode the names of the projects in the parent repository, as forcing the parent repository to “know” which projects exist in the subcomponent repositories would cause maintenance issues in both places. Shell commands such as
find ace* -name ".project" -exec dirname {} ";" | xargs -n1 -i{} echo mv {} .
can find the directories with a .project file in them, and create the move (mv) commands to put them in the correct place. Adding filters to eliminate test projects is relatively simple also, as can be seen from the script in the repo.
For the shared library build, a similar approach also works, where the problem exists but is less widespread. The directory structure
ace-submodule-subflowlib-level1
├── ace-submodule-javalib-level1
│ └── JavaLibLevel1
├── SubflowLibLevel1
│ └── SubflowLibLevel1
├── SubflowLibLevel1_ContractTest
├── SubflowLibLevel1_ScaffoldApp
└── SubflowLibLevel1_UnitTest
is changed (by another build-and-ut.sh) to
ace-submodule-subflowlib-level1
├── ace-submodule-javalib-level1
├── JavaLibLevel1
├── SubflowLibLevel1
│ └── SubflowLibLevel1
├── SubflowLibLevel1_ContractTest
├── SubflowLibLevel1_ScaffoldApp
└── SubflowLibLevel1_UnitTest
with the Java project being moved up to the correct level to be found during the build. The Java code itself is the next level down, but that is not built as an ACE application or library (it’s a plain Java project that is pulled into SubflowLibLevel1) and so can be built and tested with standard Java tools (see the ant build.xml for details).
This style of approach will also work if the repositories are in peer directories (as they would be for Eclipse project set clones using PSF files) with minor adjustments to the scripts. ACE v12 is designed to work with standard filesystem tools as long as the resulting directory structure is compatible with ACE expectations, so almost any solution (even unusual ones, such as using docker volume mounts to create a virtual top-level directory) that creates the correct format will work.
Notes on the Projects and Jenkins Pipeline
This article is mostly about how to extract and build ACE projects, and the projects (starting at App1) are designed to show this aspect in a simple way. Each level also has tests to cover the various aspects of the code, and the tests are described in the repositories for those interested in the contract test approach or other testing.
The various projects are also set up to use GitHub Actions to run builds and tests to check code before it is allowed to be merged; see the various .github/workflows directories in the app and library repositories for details.
The App1 repo also contains more details on how to set up Jenkins, including the need for advanced sub-modules behaviors with the recursive option set.
Summary
Although moving from manual to automated BAR builds may seem difficult when faced with complex source repositories, the ACE design allows the use of commodity tools and standard formats to enable industry-standard pipelines even in complex cases. Regardless of whether the pipeline destination is integration nodes or containers, the ACE commands and test capabilities allow for increasing agility along the whole software delivery pipeline.
Thanks to Marc Verhiel for inspiration and feedback for this post.
Published at DZone with permission of Trevor Dolby. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments