Adopting Microservices at Netflix: Lessons for Team and Process Design
Join the DZone community and get the full member experience.
Join For Free[this article was written by tony mauro .]
in a previous blog post , we shared best practices for designing a microservices architecture, based on adrian cockcroft’s presentation at nginx.conf2014 about his experience as director of web engineering and then cloud architect at netflix . in this follow-up post, we’ll review his recommendations for retooling your development team and processes for a smooth transition to microservices.
optimize for speed, not efficiency

source: xyzproject@dreamstime.com
the top lesson that cockcroft learned at netflix is that speed wins in the marketplace. if you ask any developer whether a slower development process is better, no one ever says yes. nor do management or customers ever complain that your development cycle is too fast for them. the need for speed doesn’t just apply to tech companies, either: as software becomes increasingly ubiquitous on the internet of things – in cars, appliances, and sensors as well as mobile devices – companies that didn’t used to do software development at all now find that their success depends on being good at it.
netflix made an early decision to optimize for speed. this refers specifically to tooling your software development process so that you can react quickly to what your customers want, or even better, can create innovative web experiences that attract customers. speed means learning about your customers and giving them what they want at a faster pace than your competitors. by the time competitors are ready to challenge you in a specific way, you’ve moved on to the next set of improvements.
this approach turns the usual paradigm of optimizing for efficiency on its head. efficiency generally means trying to control the overall flow of the development process to eliminate duplication of effort and avoid mistakes, with an eye to keeping costs down. the common result is that you end up focusing on savings instead of looking for opportunities that increase revenue.
in cockcroft’s experience, if you say “i’m doing this because it’s more efficient,” the unintended result is that you’re slowing someone else down. this is not an encouragement to be wasteful, but you should optimize for speed first. efficiency becomes secondary as you satisfy the constraint that you’re not slowing things down. the way you grow the business to be more efficient is to go faster.
make sure your assumptions are still true
many large companies that have enjoyed success in their market (we can call them incumbents ) are finding themselves overtaken by nimbler, usually smaller, organizations ( disruptors ) that react much more quickly to changing consumer behavior. their large size isn’t necessarily the root of the problem – netflix is no longer a small company, for example. as cockcroft sees it, the main cause of difficulty for industry incumbents is that they’re operating under business assumptions that are no longer true. or, as will rogers put it,
it’s not what we don’t know that hurts. it’s what we know that ain’t so.”
of course, you have to make assumptions as you formulate a business model, and then it makes sense to optimize your business practices around them. the danger comes from sticking with assumptions after they’re no longer true, which means you’re optimizing on the wrong thing. that’s when you become vulnerable to industry disruptors who are making the right assumptions and optimizations for the current business climate.
as examples, consider the following assumptions that hold sway at many incumbents. we’ll examine them further in the indicated sections and describe the approach netflix adopted.
- computing power is expensive. this was true when increasing your computing capacity required capital expenditure on computer hardware. see put your infrastructure in the cloud .
- process prevents problems. at many companies, the standard response to something going wrong is to add a preventative step to the relevant procedure. see create a high freedom, high responsibility culture with less process .
here are some ways to avoid holding onto assumptions that have passed their expiration date:
- as obvious as it might seem, you need to make your assumptions explicit, then periodically review them to make sure they still hold true.
- keep aware of technological trends. as an example, the cost of solid state storage drive (ssds) storage continues to go down. it’s still more expensive than regular disks, but the cost difference is becoming small enough that many companies are deciding the superior performance is worth paying a bit more for. [ed: in this entertaining video , fastly founder and ceo artur bergman explains why he believes ssds are always the right choice.]
- talk to people who aren’t your customers. this is especially necessary for incumbents, who need to make sure that potential new customers are interested in their product. otherwise, they don’t hear about the fact that they’re not being used. as an example, some vendors in the storage space are building hyper-converged systems even as more and more companies are storing their data in the cloud and using open source storage management software. netflix, for example, stores data on amazon web services (aws) servers with ssds and manages it with apache cassandra . a single specialist in java distributed systems is managing the entire configuration without any commercial storage tools or help from engineers specializing in storage, san, or backup.
- don’t base your future strategy on current it spending, but instead on level of adoption by developers. suppose that your company accounts for nearly all spending in the market for proprietary virtualization software, but then a competitor starts offering an open source-based product at only 1% the cost of yours. if people start choosing it instead of your product, than at the point that your share of total spending is still 90%, your market share has declined to only 10%. if you’re only attending to your revenue, it seems like you’re still in good shape, but 10% of market share can collapse really quickly.
put your infrastructure in the cloud

source: fbmadeira@dreamstime.com
in make sure your assumptions are still true , we mentioned that in the past it was valid to base your business plan on the assumption that computing power was expensive, because it was: the only way to increase your computing capacity was to buy computer hardware. you could then make money by using this expensive resource in the right way to solve customer problems.
the advent of cloud computing has pretty much completely invalidated this assumption. it is now possible to buy the amount of capacity you need when you need it, and to pay for only the time you actually use it. the new assumption you need to make is that (virtual) machines are ephemeral. you can create and destroy them at the touch of a button or a call to an api, without any need to negotiate with other departments in your company.
one way to think of this change is that the self-service cloud makes formerly impossible things instantaneous. all of netflix’s engineers are in california, but they manage a worldwide infrastructure. the cloud enables them to experiment and determine whether (for example) adding servers in particular location improves performance. suppose they notice problems with video delivery in brazil. they can easily set up 100 cloud server instances in são paulo within a couple hours. if after a week they determine that the difference in delivery speed and reliability isn’t large enought to justify the cost of the additional server instances, they can shut them down just as quickly and easily as they created them.
this kind of experiment would be so expensive with a traditional infrastructure that you would never attempt it. you would have to hire an agent in são paulo to coordinate the project, find a data center, satisfy brazilian government regulations, ship machines to brazil, and so on. it would be six months before you could even run the test and find out that increased local capacity didn’t improve your delivery speed.
create a high freedom, high responsibility culture with less process
in make sure your assumptions are still true , we observed that many companies create rules and processes to prevent problems. when someone makes a mistake, they add a rule to the hr manual that says “well, don’t do that again.” if you read some hr manuals from this perspective, you can extract a historical record of everything that went wrong at the company. when something goes wrong in the development process, the corresponding reaction is to add a new step to the procedure. the major problem with creating process to prevent problems is that over time you build up complex “scar tissue” processes that slow you down.
netflix doesn’t have an hr manual. there is a single guideline: “act in netflix’s best interest.” the idea is that if an employee can’t figure out how to interpret the guideline in a given situation, he or she doesn’t have enough judgment to work there. if you don’t trust the judgment of the people on your team, you have to ask why you’re employing them. it’s true that you’ll have to fire people occasionally for violating the guideline. overall, the high level of mutual trust among members of a team, and across the company as a whole, becomes a strong binding force.
the following books outline new ways of thinking about process if you’re looking to transform your organization:
- the goal: a process of ongoing improvement by eliyahu m. goldratt and jeff cox. this book has become a standard management text at business schools since its original publication in 1984. written as a novel about a manager who has only 90 days to improve performance at his factory or have it closed down, it embodies goldratt’s theory of constraints in the context of process control and automation.
- the phoenix project: a novel about it, devops, and helping your business win by gene kim and kevin behr. as the title indicates, it’s also a novel, about an it manager who has 90 days to save a project that’s late and over budget, or his entire department will be outsourced. he discovers devops as the solution to his problem.
replace silos with microservice teams
most software development groups are separated into silos, with no overlap of personnel between them. the standard process for a software development project starts with the product manager meeting with the user experience and development groups to discuss ideas for new features. after the idea is implemented in code, the code is passed to the quality assurance (qa) and database administration teams and discussed in more meetings. communication with the system, network, and san administrators is often via tickets. the whole process tends to be slow and loaded with overhead.
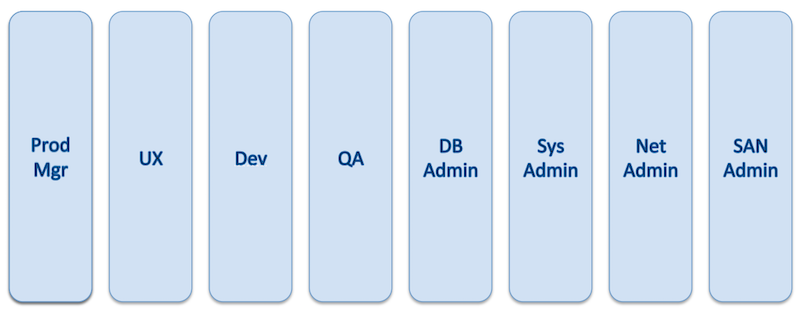
source: adrian cockcroft
some companies try to speed up by creating small “start-up”-style teams that handle the development process from end to end, or sometimes such teams are the result of acquisitions where the acquired company continues to run independently as a separate division. but if the small teams are still doing monolithic delivery, there are usually still handoffs between individuals or groups with responsibility for different functions. the process suffers from the same problems as monolithic delivery in larger companies – it’s simply not very efficient or agile.

source: adrian cockcroft
conway’s law says that the interface structure of a software system will reflect the social structure of the organization that produced it. so if you want to switch to a microservices architecture, you need to organize your staff into product teams and use devops methodology. there are no longer distinct product managers, ux managers, development managers, and so on, managing downward in their silos. there is a manager for each product feature (implemented as a microservice), who supervises a team that handles all aspects of software development for the microservice, from conception through deployment. the platform team provides infrastructure support that the product teams access via apis. at netflix, the platform team was mostly aws in seattle, with some netflix-managed infrastructure layers built on top. but it doesn’t matter whether your cloud platform is in-house or public; the important thing is that it’s api-driven, self-service, and automatable.
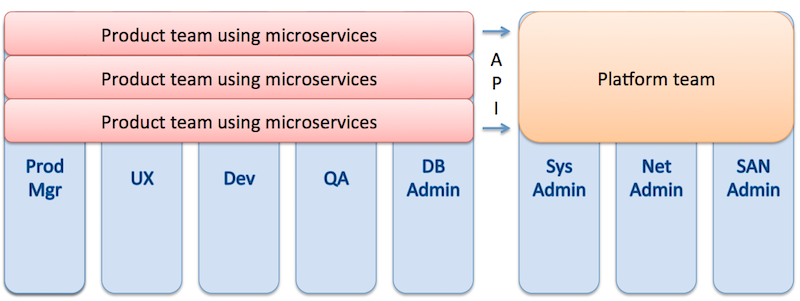
source: adrian cockcroft
adopt continuous delivery, guided by the ooda loop
a siloed team organization is usually paired with monolithic delivery model, in which an integrated, multi-function application is released as a unit (often version-numbered) on a regular schedule. most software development teams use this model initially because it is relatively simple and works well enough with a small number of developers (say, 50 or fewer). however, as the team grows it becomes a real issue when you discover a bug in one developer’s code during qa or production testing and the work of 99 other developers is blocked from release until the bug is fixed.
in 2009 netflix adopted a continuous delivery model, which meshes perfectly with a microservices architecture. each microservice represents a single product feature that can be updated independently of the other microservices and on its own schedule. discovering a bug in a microservice has no effect on the release schedule of any other microservice. continuous delivery relies on packaging microservices in standard containers. netflix initially used aws machine images (amis) and it was possible to deploy an update into a test or production environment in about 10 minutes. with docker, that time is reduced even further, to mere seconds in some cases.
at netflix, the conceptual framework for continuous development and delivery is an observe-orient-decide-act (ooda) loop .

source: adrian cockcroft (http://www.slideshare.net/adrianco)
observe refers to examining your current status to look for places where you can innovate. you want your company culture to implicitly authorize anyone who notices an opportunity to start a project to exploit it. for example, you might notice what the diagram calls a “customer pain point”: a lot of people abandoning the registration process on your website when they reach a certain step. you can undertake a project to investigate why and fix the problem.
orient refers to analyzing metrics to understand the reasons for the phenomena you’ve observed at the observe point. often this involves analyzing large amounts of unstructured data, such as log files; this is often referred to as big data analysis. the answers you’re looking for are not already in your business intelligence database. you’re examining data that no one has previously looked at and asking questions that haven’t been asked before.
decide refers to developing and executing a project plan. company culture is a big factor at this point. as previously discussed, in a high-freedom, high-responsibility culture you don’t need to get management approval before starting to make changes. you share your plan, but you don’t have to ask for permission.
act refers to testing your solution and putting it into production. you deploy a microservice that includes your incremental feature to a cloud environment, where it’s automatically put into an ab test to compare it to the previous solution, side by side, for as long as it takes to collect the data that shows whether your approach is better. cooperating microservices aren’t disrupted, and customers don’t see your changes unless they’re selected for the test. if your solution is better, you deploy it into production. it doesn’t have to be a big improvement, either. if the number of clients for your microservice is large enough, then even a fraction of a percent improvement (in response time, say) can be shown to be statistically valid, and the cumulative effect over time of many small changes can be significant.
now you’re back at the observe point. you don’t always have to perform all the steps or do them in strict order, either. the important characteristic of the process is that it enables you quickly to determine what your customers want and to create it for them. cockcroft says “it’s hard not to win” if you’re basing your moves on enough data points and your competitors are making guesses that take months to be proven or disproven.
the state of art is to circle the loop every one to two weeks, but every microservice team can do it independently. with microservices you can go much faster because you’re not trying to get entire company going around the loop in lockstep.
how nginx plus can help
at nginx we believe it’s crucial to your future success that you adopt a 4-tier application architecture in which applications are developed and deployed as sets of microservices . we hope the information we’ve shared in this post and its predecessor, adopting microservices at netflix: lessons for architectural design , are helpful as you plan your transition to today’s state-of-the-art architecture for application development.
when it’s time to deliver your apps, nginx plus offers an application delivery platform that provides the superior performance, reliability, and scalability your users expect. fully adopting a microservices-based architecture is easier and more likely to succeed when you move to a single software tool for web serving, load balancing, and content caching. nginx plus combines those functions and more in one easy to deploy and manage package. our approach empowers developers to define and control the flawless delivery of their microservices, while respecting the standards and best practices put into place by a platform team. click here to learn more about how nginx plus can help your applications succeed.
video recordings
fast delivery
nginx.conf2014, october 2014
migrating to microservices, part 1
silicon valley microservices meetup, august 2014
migrating to microservices, part 2
silicon valley microservices meetup, august 2014
Published at DZone with permission of Patrick Nommensen, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments