Accelerate Your Journey to a Modern Data Platform Using Coalesce
This article will identify key challenges organizations face today in managing data platforms, and explore how advanced ETL tools can address these challenges.
Join the DZone community and get the full member experience.
Join For FreeMost organizations face challenges while adapting to data platform modernization. The critical challenge that data platforms have faced is improving the scalability and performance of data processing due to the increased volume, variety, and velocity of data used for analytics.
This article aims to summarize answers to the challenging questions of data platform modernization, and here are a few questions:
- How can we onboard new data sources with no code or less code?
- What steps are required to improve data integrity among various data source systems?
- How can continuous integration/continuous development workflows across environments be simplified?
- How can we improve the testing process?
- How do we identify data quality issues early in the pipeline?
Evolution of Data Platforms
The evolution of data platforms and corresponding tools achieved considerable advancements driven by data's vast volume and complexity. Various data platforms have been used for a long time to consolidate data by extracting it from a wide array of heterogeneous source systems and integrating them by cleaning, enriching, and nurturing the data to make it easily accessible to different business users and cross-teams in an organization.
- The on-premises Extract, Transform, Load (ETL) tools are designed to process data for large-scale data analysis and integration into a central repository optimized for read-heavy operations. These tools manage structured data.
- All the organizations started dealing with vast amounts of data as Big Data rose. It is a distributed computing framework for processing large data sets. Tools like HDFS (Hadoop) and MapReduce enabled the cost-effective handling of vast data. These ETL tools encountered data complexity, scalability, and cost challenges, leading to No-SQL Databases such as MongoDB, Cassandra, and Redis, and these platforms excelled at handling unstructured or semi-structured data and provided scalability for high-velocity applications.
- The need for faster insights led to the evolution of data integration tools to support real-time and near-real-time ingestion and processing capabilities, such as Apache Kafka for real-time data streaming, Apache Storm for real-time data analytics, real-time machine learning, and Apache Pulsar for distributed messaging and streaming. Many more data stream applications are available.
- Cloud-based solutions like cloud computing and data warehouses like Amazon RDS, Google Big Query, and Snowflake offer scalable and flexible database services with on-demand resources. Data lake and lake warehouse formation on cloud platforms such as AWS S3 and Azure Data Lake allowed for storing raw, unstructured data in its native format. This approach provided a more flexible and scalable alternative to traditional data warehouses, enabling more advanced analytics and data processing. They provide a clear separation between computing and storage with managed services for transforming data within the database.
- With the integration of AI/ML into data platforms through tools such as Azure Machine Learning and AWS Machine Learning, Google AI data analysis is astonishing. Automated insights, predictive analytics, and natural language querying are becoming more prevalent, enhancing the value extracted from data.
Challenges While Adapting a Data Platform Modernization
Data platform modernization is essential for staying competitive and controlling the full potential of data. The critical challenge data platforms have faced is improving the scalability and performance of data processing due to the increased volume, variety, and velocity of data used for analytics. Most of the organizations are facing challenges while adapting to data platform modernization. The key challenges are:
- Legacy systems integration: Matching Apple to Apple is complex because outdated legacy source systems are challenging to integrate with modern data platforms.
- Data migration and quality: Data cleansing and quality issues are challenging to fix during data migration.
- Cost management: Due to the expensive nature of data modernization, budgeting and managing the cost of a project are significant challenges.
- Skills shortage: Retaining and finding highly niche skilled resources takes much work.
- Data security and privacy: Implementing robust security and privacy policies can be complex, as new technologies come with new risks on new platforms.
- Scalability and flexibility: The data platforms should be scalable and adapt to changing business needs as the organization grows.
- Performance optimization: It is essential to ensure that new platforms will perform efficiently under various data loads and scales, and increasing data volumes and queries is challenging.
- Data governance and compliance: It is challenging to implement data governance policies and comply with regulatory requirements in a new environment if there is no existing data strategy defined for strategic solutions across the organization.
- Vendor lock-in: Organizations should look for interoperability and portability while modernizing instead of having a single vendor locked in.
- User adoption: To get end users' buy-in, we must provide practical training and communication strategies.
ETL Framework and Performance
The ETL Framework impacts performance in several aspects within any data integration. The framework's performance is evaluated against the following metrics.
- Process utilization
- Memory usage
- Time
- Network bandwidth utilization
Let us review how cloud-based ETL tools, as a framework, support fundamental data operations principles. This article covers how to simplify Data Operations with advanced ETL tools. For example, we will cover the Coalesce cloud-based ETL tool.
- Collaboration: The advanced cloud-based ETL tools allow data transformations written using platform native code and provide documentation within the models to generate clear documentation, making it easier for the data teams to understand and collaborate on data transformations.
- Automation: These tools allow data transformations and test cases to be written as code with explicit dependencies, automatically enabling the correct order of running scheduled data pipelines and CI/CD jobs.
- Version control: These tools seamlessly integrate with GitHub, Bitbucket, Azure DevOps, and GitLab, enabling the tracking of model changes and allowing teams to work on different versions of models, facilitating parallel development and testing.
- Continuous Integration and Continuous Delivery (CI/CD): ETL frameworks allow businesses to automate deployment processes by identifying changes and running impacted models and their dependencies along with the test cases, ensuring the quality and integrity of data transformations.
- Monitoring and observability: The modern data integration tools allow to run data freshness and quality checks to identify potential issues and trigger alerts,
- Modularity and reusability: It also encourages breaking down transformations into smaller, reusable models and allows sharing models as packages, facilitating code reuse across projects.
Coalesce Is One of the Choices
Coalesce is a cloud-based ELT (Extract Load and Transform) and ETL (Extract Transform and Load) tool that adopts data operation principles and uses tools that natively support them. It is one tool backed by the Snowflake framework for modern data platforms. Figure 1 shows an automated process for data transformation on the Snowflake platform. Coalesce generates the Snowflake native SQL code. Coalesce is a no/low-code data transformation platform.
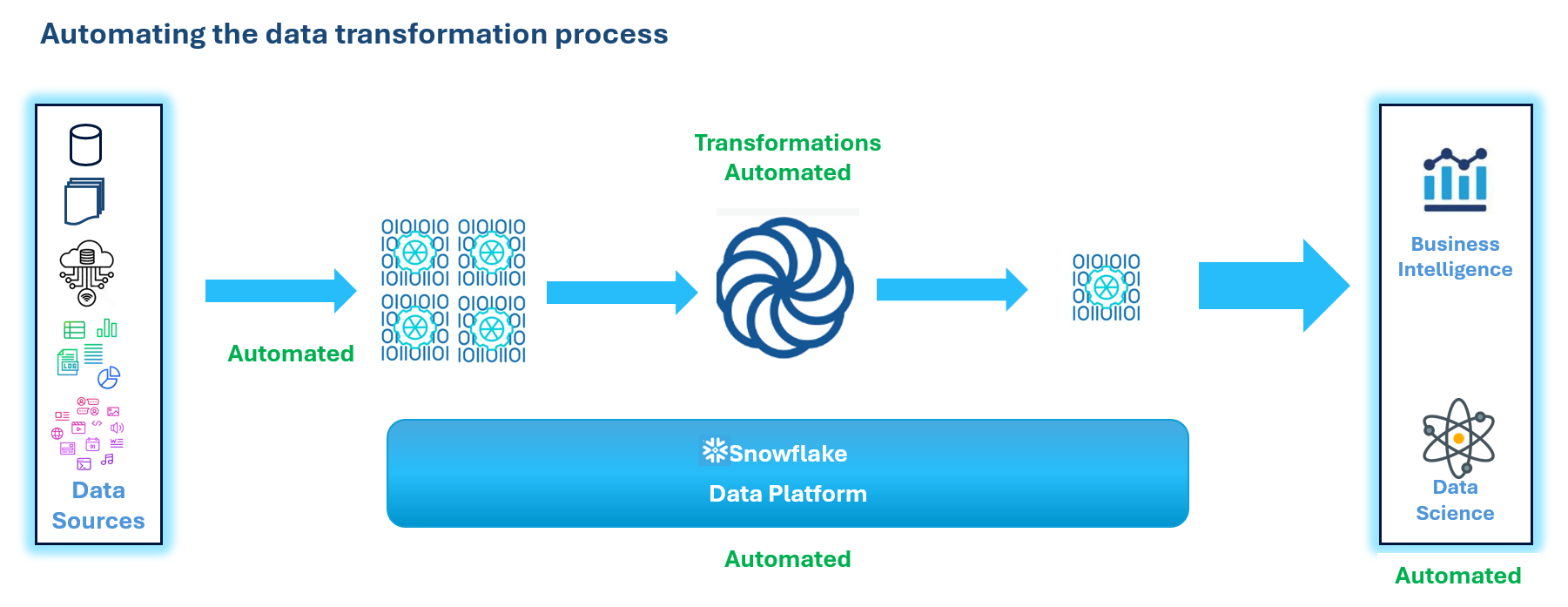
Figure 1: Automating the data transformation process using Coalesce
The Coalesce application comprises a GUI front end and a backend cloud data warehouse. Coalesce has both GUI and Codebase environments. Figure 2 shows a high-level Coalesce application architecture diagram.
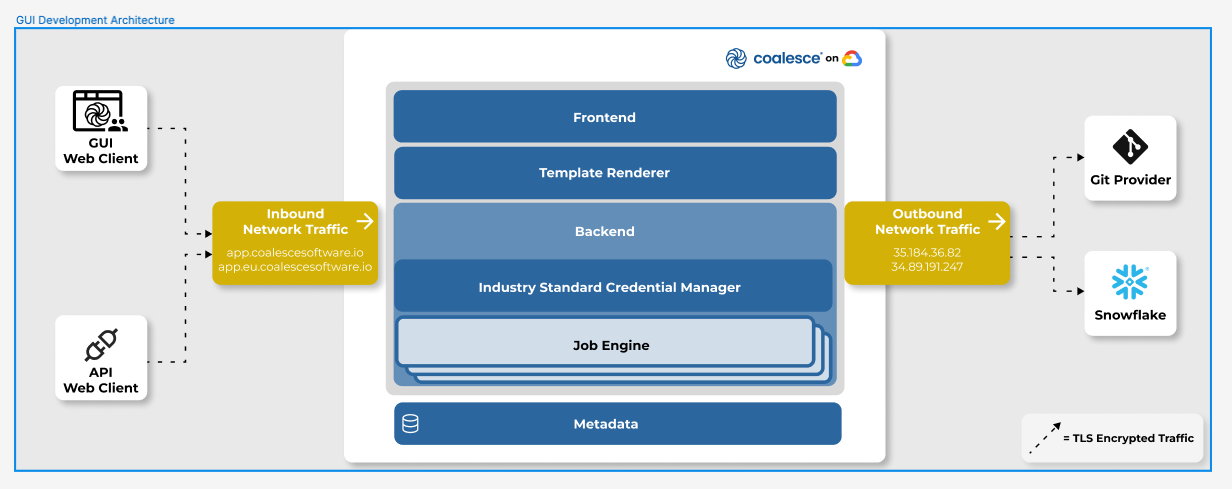
Figure 2: Coalesce Application Architecture (Image Credit: Coalesce)
Coalesce is a data transformation tool that uses graph-like data pipelines to develop and define transformation rules for various data models on modern platforms while generating Structured Query Language (SQL) statements. Figure 3 shows the combination of templates and nodes, like data lineage graphs with SQL, which makes it more potent for defining the transformation rules. Coalesce code-first GUI-driven approach has made building, testing, and deploying data pipelines easier. This coalesce framework improves the data pipeline development workflow compared to creating directed acyclic graphs (or DAGs) purely with code. Coalesce has column-aware inbuild column integrated functionality in the repository, which allows you to see data lineage for any column in the graphs.)
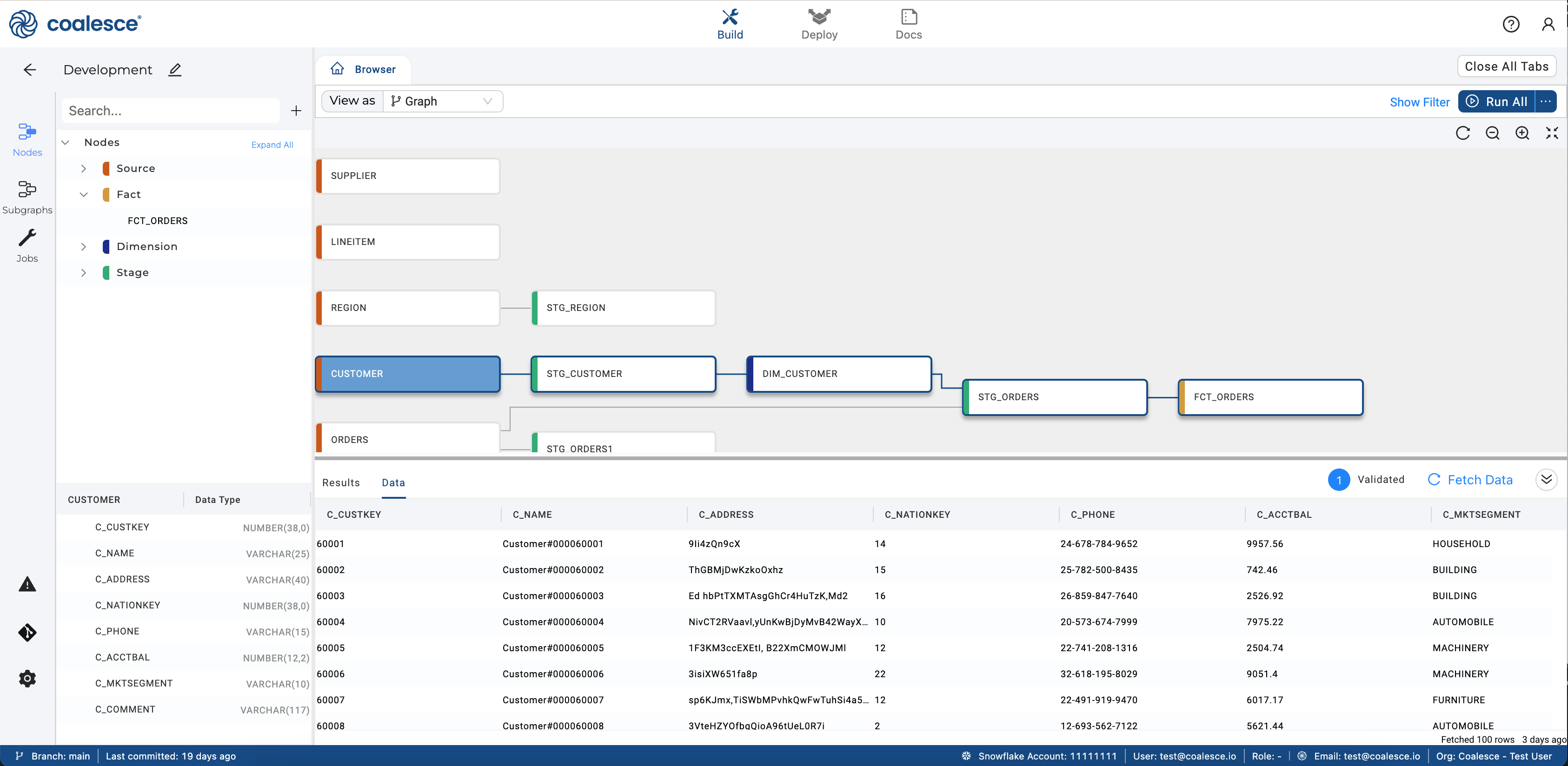
Figure 3: Directed Acyclic Graph with various types of nodes (Image Credit: Coalesce)
- Set up projects and repositories. The Continuous Integration (CI)/Continuous Development (CD) workflow without the need to define the execution order of the objects. Coalesce tool supports various DevOps providers such as GitHub, Bitbucket, GitLab, and Azure DevOps. Each Coalesce project should be tied to a single git repository, allowing easy version control and collaboration.
![Browser Git Integration Data Flow]()
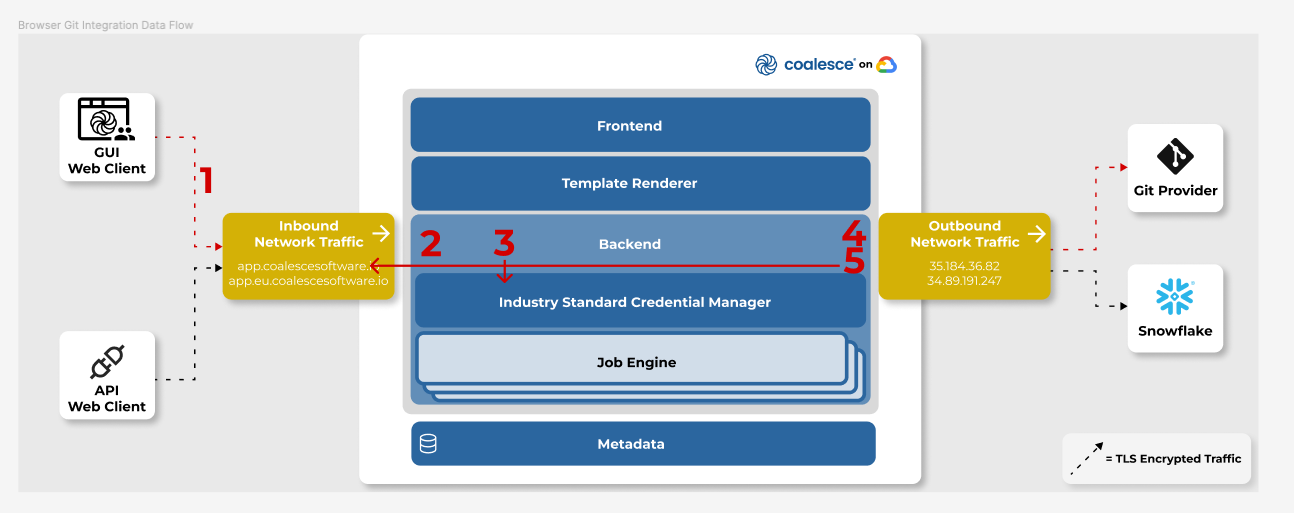
Figure 4: Browser Git Integration Data Flow (Image Credit: Coalesce)
Figure 4 demonstrates the steps for browser Git Integration with Coalesce. This article will detail the steps to configure Git with Coalesce. The reference link guide will provide detailed steps on this configuration.
When a user submits a Git request from the browser, an API call sends an authenticated request to the Coalesce backend (1). Upon successful authentication (2), the backend retrieves the Git personal access token (PAT) for the user from the industry standard credential manager (3) in preparation for the Git provider request. The backend then communicates directly over HTTPS/TLS with the Git provider (4) (GitHub, Bitbucket, Azure DevOps, GitLab), proxying requests (for CORS purposes) over HTTPS/TLS back to the browser (5). The communication in part 5 uses the native git HTTP protocol over HTTPS/TLS (this is the same protocol used when performing a git clone with an HTTP git repository URL).
- Set up the workspace. Within a project, we can create one or multiple Development Workspaces, each with its own set of code and configurations. Each project has its own set of deployable Environments, which can used to test and deploy code changes to production. In the tool itself, we configure Storage Locations and Mappings. A good rule is to create target schemas in Snowflake for DEV, QA, and Production. Then, map them in Coalesce.
- The build interface is where we will spend most of our time creating nodes, building graphs, and transforming data. Coalesce comes with default node types that are not editable. However, they can be duplicated and edited, or new ones can made from scratch. The standard nodes are the source node, stage node, persistent stage node, fact node, dimension node with SCD Type 1 and Type 2 support, and view node. With very ease of use, we can create various nodes and configure properties in a few clicks. A graph represents an SQL pipeline. Each node is a logical representation and can materialize as a table or a view in the database.
- User-defined nodes: Coalesce has User-Defined Nodes (UDN) for any particular object types or standards an organization may want to enforce. Coalesce packages have built-in nodes and templates for building Data Vault objects like Hubs, Links, PIT, Bridge, and Satellites. For example, package id for Data Vault 2.0 can be installed in the project's workspace.
- Investigate the data issues without inspecting the entire pipeline by narrowing the analysis using a lineage graph and sub-graphs.
- Adding new data objects without worrying about the orchestration and defining the execution order is easy.
- Execute tests through dependent objects and catch errors early in the pipeline. Node tests can run before or after the node's transformations, and this is user-configurable.
- Deployment interface: Deploy data pipelines to the data warehouse using Deployment Wizard. We can select the branch to deploy, override default parameters if required, and review the plan and deployment status. This GUI interface can deploy the code across all environments.
- Data refresh: We can only refresh it if we have successfully deployed the pipeline. Refresh runs the data transformations defined in data warehouse metadata. Use refresh to update the pipeline with any new changes from the data warehouse. To only refresh a subset of data, use Jobs. Jobs are a subset of nodes created by the selector query run during a refresh. In coalescing in the build interface, create a job, commit it to git, and deploy it to an environment before it can used.
- Orchestration: Coalesce orchestrates the execution of a transformation pipeline and allows users the freedom and flexibility to choose a scheduling mechanism for deployments and job refreshes that fit their organization's current workflows. Many tools, such as Azure Data Factory, Apache Airflow, GitLab, Azure DevOps, and others, can automate execution according to time or via specific triggers (e.g., upon code deployment). Snowflake also comes in handy by creating tasks and scheduling on Snowflake. Apache Airflow is a standard orchestrator used with Coalesce.
- Rollback: To roll back a deployment in Coalesce and restore the environment to its prior state regarding data structures, redeploy the commit deployed just before the deployment to roll back.
- Documentation: Coalesce automatically produces and updates documentation as developers work, freeing them to work on higher-value deliverables.
- Security: Coalesce never stores data at rest and data in motion is always encrypted, data is secured in the Snowflake account.
Upsides of Coalesce
| Feature | Benefits |
|---|---|
|
Template-driven development |
Speed development; Change once, update all |
|
Auto generates code |
Enforce standards w/o reviews |
|
Scheduled execution |
Automates pipelines with 3rd party orchestration tools such as Airflow, Git, or Snowflake tasks to schedule the jobs |
|
Flexible coding |
Facilitates self-service and easy to code |
|
Data lineage |
Perform impact analysis |
|
Auto generates documentation |
Quick to onboard new staff |
Downsides of Coalesce
Being Coalesce is a comprehensive data transformation platform with robust data integration capabilities it has some potential cons of using it as an ELT/ETL tool:
- Coalesce is built exclusively to support Snowflake.
- Reverse engineering schema from Snowflake into coalesce is not straightforward. Certain YAML files and configuration specification updates are required to get into graphs. The YAML file should be built with specifications to meet reverse engineering into graphs.
- The lack of logs after deployment and lack of logs during the data refresh phase can result in vague errors that are difficult to resolve issues.
- Infrastructure changes can be difficult to test and maintain, leading to frequent job failures. The CI/CD should be performed in a strictly controlled form.
- No built-in scheduler is available in the Coalesce application to orchestrate jobs like other ETL tools such as DataStage, Talend, Fivetran, Airbyte, and Informatica.
Conclusions
Here are the key take away from this article:
- As data platforms become more complex, managing them becomes difficult, and embracing the Data Operations principle is the way to address data operation challenges.
- We looked at the capabilities of ETL Frameworks and their performance.
- We examined Coalesce as a solution that supports data operation principles and allows us to build automated, scalable, agile, well-documented data transformation pipelines on a cloud-based data platform.
- We discussed the ups and downsides of Coalesce.
Opinions expressed by DZone contributors are their own.
Comments