A New Era Has Come, and So Must Your Database Observability
We can't prevent the bad code from the deployment. We lack database observability, and we can't troubleshoot automatically. We need a new approach: database guardrails.
Join the DZone community and get the full member experience.
Join For FreeThe World Has Changed, and We Need To Adapt
The world has gone through a tremendous transformation in the last fifteen years. Cloud and microservices changed the world. Previously, our application was using one database; developers knew how it worked, and the deployment rarely happened. A single database administrator was capable of maintaining the database, optimizing the queries, and making sure things worked as expected. The database administrator could just step in and fix the performance issues we observed. Software engineers didn’t need to understand the database, and even if they owned it, it was just a single component of the system. Guaranteeing software quality was much easier because the deployment happened rarely, and things could be captured on time via automated tests.
Fifteen years later, everything is different. Companies have hundreds of applications, each one with a dedicated database. Deployments happen every other hour, deployment pipelines work continuously, and keeping track of flowing changes is beyond one’s capabilities. The complexity of the software increased significantly. Applications don’t talk to databases directly but use complex libraries that generate and translate queries on the fly. Application monitoring is much harder because applications do not work in isolation, and each change may cause multiple other applications to fail. Reasoning about applications is now much harder. It’s not enough to just grab the logs to understand what happened. Things are scattered across various components, applications, queues, service buses, and databases.
Databases changed as well. We have various SQL distributions, often incompatible despite having standards in place. We have NoSQL databases that provide different consistency guarantees and optimize their performance for various use cases. We developed multiple new techniques and patterns for structuring our data, processing it, and optimizing schemas and indexes. It’s not enough now to just learn one database; developers need to understand various systems and be proficient with their implementation details. We can’t rely on ACID anymore as it often harms the performance. However, other consistency levels require a deep understanding of the business. This increases the conceptual load significantly.
Database administrators have a much harder time keeping up with the changes, and they don’t have enough time to improve every database. Developers are unable to analyze and get the full picture of all the moving parts, but they need to deploy changes faster than ever. And the monitoring tools still swamp us with metrics instead of answers. Given all the complexity, we need developers to own their databases and be responsible for their data storage. This “shift left” in responsibility is a must in today’s world for both small startups and big Fortune 500 enterprises. However, it’s not trivial. How do we prevent the bad code from reaching production? How to troubleshoot issues automatically? How do we move from monitoring to observability? Finally, how do we give developers the proper tools and processes so they will be able to own the databases? Read on to find answers.
Measuring Application Performance Is Complex
It’s crucial to measure to improve the performance. Performance indicators (PIs) help us evaluate the performance of the system on various dimensions. They can focus on infrastructure aspects such as the reliability of the hardware or networking. They can use application metrics to assess the performance and stability of the system. They can also include business metrics to measure the success from the company and user perspective, including user retention or revenue. Performance indicators are important tracking mechanisms to understand the state of the system and the business as a whole. However, in our day-to-day job, we need to track many more metrics. We need to understand contributors to the performance indicators to troubleshoot the issues earlier and understand whether the system is healthy or not. Let’s see how to build these elements in the modern world.
We typically need to start with telemetry — the ability to collect the signals. There are multiple types of signals that we need to track: logs (especially application logs), metrics, and traces. Capturing these signals can be a matter of proper configuration (like enabling them in the hosting provider panel), or they need to be implemented by the developers. Recently, OpenTelemetry gained significant popularity. It’s a set of SDKs for popular programming languages that can be used to instrument applications to generate signals. This way, we have a standardized way of building telemetry within our applications. Odds are that most of the frameworks and libraries we use are already integrated with OpenTelemetry and can generate signals properly.
Next, we need to build a solution for capturing the telemetry signals in one centralized place. This way, we can see “what happens” inside the system. We can browse the signals from the infrastructure (like hosts, CPUs, GPUs, and network), applications (number of requests, errors, exceptions, data distribution), databases (data cardinality, number of transactions, data distribution), and many other parts of the application (queues, notification services, service buses, etc.). This lets us troubleshoot more easily as we can see what happens in various parts of the ecosystem.
Finally, we can build the Application Performance Management (APM). It’s the way of tracking metric indicators with telemetry and dashboards. APM focuses on providing end-to-end monitoring that goes across all the components of the system, including the web layer, mobile and desktop applications, databases, and the infrastructure connecting all the elements. It can be used to automate alarms and alerts to constantly assess whether the system is healthy.
APM may seem like a silver bullet. It aggregates metrics, shows the performance, and can quickly alert when something goes wrong, and the fire begins. However, it’s not that simple. Let’s see why.
Why Application Performance Monitoring Is Not Enough
APM captures signals and presents them in a centralized application. While this may seem enough, it lacks multiple features that we would expect from a modern maintenance system.
First, APM typically presents raw signals. While it has access to various metrics, it doesn’t connect the dots easily. Imagine that the CPU spikes. Should you migrate to a bigger machine? Should you optimize the operating system? Should you change the driver? Or maybe the CPU spike is caused by different traffic coming to the application? You can’t tell that easily just by looking at metrics.
Second, APM doesn’t easily show where the problem is. We may observe metrics spiking in one part of the system, but it doesn’t necessarily mean that the part is broken. There may be other reasons and issues. Maybe it’s wrong input coming to the system, maybe some external dependency is slow, and maybe some scheduled task runs too often. APM doesn’t show that, as it cannot connect the dots and show the flow of changes throughout the system. You just see the state then, but you don’t see how you got to that point easily.
Third, the resolution is unknown. Let’s say that the CPU spiked during the scheduled maintenance task. Should we upscale the machine? Should we disable the task? Should we run it some other time? Is there a bug in the task? Many things are not clear. We can easily imagine a situation when the scheduled task runs in the middle of the day just because it is more convenient for the system administrators; however, the task is now slow and competes with regular transactions for the resources. In that case, we probably should move the task to some time outside of peak hours. Another scenario is that the task was using an index that doesn’t work anymore. Therefore, it’s not about the task per se, but it’s about the configuration that has been changed with the last deployment. Therefore, we should fix the index. APM won’t show us all those details.
Fourth, APM is not very readable. Dashboards with metrics look great, but they are too often just checked whether they’re green. It’s not enough to see that alarms are not ringing. We need to manually review the metrics, look for anomalies, understand how they change, and if we have all the alarms in place. This is tedious and time-consuming, and many developers don’t like doing that. Metrics, charts, graphs, and other visualizations swamp us with raw data that doesn’t show the big picture.
Finally, one person can’t reason about the system. Even if we have a dedicated team for maintenance, the team won’t have an understanding of all the changes going through the system. In the fast-paced world with tens of deployments every day, we can’t look for issues manually. Every deployment may result in an outage due to invalid schema migration, bad code change, cache purge, lack of hardware, bad configuration, or many more issues. Even when we know something is wrong and we can even point to the place, the team may lack the understanding or knowledge needed to identify the root cause. Involving more teams is time-consuming and doesn’t scale.
While APM looks great, it’s not the ultimate solution. We need something better. We need something that connects the dots and provides answers instead of data. We need true observability.
What Makes the Observability Shine
Observability turns alerts into root causes and raw data into understanding. Instead of charts, diagrams, and graphs, we want to have a full story of the changes going through pipelines and how they affect the system. This should understand the characteristics of the application, including the deployment scheme, data patterns, partitioning, sharding, regionalization, and other things specific to the application.
Observability lets us reason about the internals of the system from the outside. For instance, we can reason that we deployed the wrong changes to the production environment because there is a metric spike in the database. We don’t focus on the database per se, but we analyze the difference between the current and the previous code. However, if there was no deployment recently, but we observe much higher traffic on the load balancer, then we can reason that it’s probably due to different traffic coming to the application. Observability makes the interconnections clear and visible.
To build observability, we need to capture static signals and dynamic history. We need to include our deployments, configuration, extensions, connectivity, and characteristics of our application code. It’s not enough just to see that “something is red now.” We need to understand how we got there and what could be the possible reason. To achieve that, a good observability solution needs to go through multiple steps.
First, we need to be able to pinpoint the problem. In the modern world of microservices and bounded contexts, it’s not trivial. If the CPU spikes, we need to be able to answer which service or application caused that, which tenant is responsible, or whether this is for all the traffic or some specific requests in the case of a web application. We can do that by carefully observing metrics with multiple dimensions, possibly with dashboards and alarms.
Second, we need to include multiple signals. CPU spikes can be caused by a lack of hardware, wrong configuration, broken code, unexpected traffic, or simply things that shouldn’t be running at that time. What’s more, maybe something unexpected happened around the time of the issue. This could be related to a deployment, an ongoing sports game, a specific time of week or time of year, some promotional campaign we just started, or some outage in the cloud infrastructure. All these inputs must be provided to the observability system to understand the bigger picture.
Third, we need to look for anomalies. It may seem counterintuitive, but digital applications rot over time. Things change, traffic changes, updates are installed, security fixes are deployed, and every single change can break our application. However, the outage may not be quick and easy. The application may get slower and slower over time, and we won’t notice that easily because alarms do not go off or they become red only for a short period. Therefore, we need to have anomaly detection built-in. We need to be able to look for traffic patterns, weekly trends, and known peaks during the year. A proper observability solution needs to be aware of these and automatically find the situations in which the metrics don’t align.
Fourth, we need to be able to automatically root cause the issue and suggest a solution. We can’t push the developers to own the databases and the systems without proper tooling. The observability systems need to be able to automatically suggest improvements. We need to unblock the developers so they can finally be responsible for the performance and own the systems end to end.
Databases and Observability We Need Today
Let’s now see what we need in the domain of databases. Many things can break, and it’s worth exploring the challenges we may face when working with SQL or NoSQL databases. We are going to see the three big areas where things may go wrong. These are code changes, schema changes, and execution changes.
Code Changes
Many database issues come from the code changes. Developers modify the application code, and that results in different SQL statements being sent to the database. These queries may be inherently slow, but these won’t be captured by the testing processes we have in place now.
Imagine that we have the following application code that extracts the user aggregate root. The user may have multiple additional pieces of information associated with them, like details, pages, or texts:
const user = repository.get("user")
.where("user.id = 123")
.leftJoin("user.details", "user_details_table")
.leftJoin("user.pages", "pages_table")
.leftJoin("user.texts", "texts_table")
.leftJoin("user.questions", "questions_table")
.leftJoin("user.reports", "reports_table")
.leftJoin("user.location", "location_table")
.leftJoin("user.peers", "peers_table")
.getOne()
return user;The code generates the following SQL statement:
SELECT *
FROM users AS user
LEFT JOIN user_details_table AS detail ON detail.user_id = user.id
LEFT JOIN pages_table AS page ON page.user_id = user.id
LEFT JOIN texts_table AS text ON text.user_id = user.id
LEFT JOIN questions_table AS question ON question.user_id = user.id
LEFT JOIN reports_table AS report ON report.user_id = user.id
LEFT JOIN locations_table AS location ON location.user_id = user.id
LEFT JOIN peers_table AS peer ON Peer.user_id = user.id
WHERE user.id = '123'Because of multiple joins, the query returns nearly 300 thousand rows to the application that are later processed by the mapper library. This takes 25 seconds in total. Just to get one user entity.
The problem with such a query is that we don’t see the performance implications when we write the code. If we have a small developer database with only a hundred rows, then we won’t get any performance issues when running the code above locally. Unit tests won’t catch that either because the code is “correct” — it returns the expected result. We won’t see the issue until we deploy to production and see that the query is just too slow.
Another problem is a well-known N+1 query problem with Object Relational Mapper (ORM) libraries. Imagine that we have table flights that are in 1-to-many relation with table tickets. If we write a code to get all the flights and count all the tickets, we may end up with the following:
var totalTickets = 0;
var flights = dao.getFlights();
foreach(var flight in flights){
totalTickets + flight.getTickets().count;
}This may result in N+1 queries being sent in total. One query to get all the flights, and then n queries to get tickets for every flight:
SELECT * FROM flights;
SELECT * FROM tickets WHERE ticket.flight_id = 1;
SELECT * FROM tickets WHERE ticket.flight_id = 2;
SELECT * FROM tickets WHERE ticket.flight_id = 3;
...
SELECT * FROM tickets WHERE ticket.flight_id = n;Just as before, we don’t see the problem when running things locally, and our tests won’t catch that. We’ll find the problem only when we deploy to an environment with a sufficiently big data set.
Yet another thing is about rewriting queries to make them more readable. Let’s say that we have a table boarding_passes. We want to write the following query (just for exemplary purposes):
SELECT COUNT(*)
FROM boarding_passes AS C1
JOIN boarding_passes AS C2 ON C2.ticket_no = C1.ticket_no AND C2.flight_id = C1.flight_id AND C2.boarding_no = C1.boarding_no
JOIN boarding_passes AS C3 ON C3.ticket_no = C1.ticket_no AND C3.flight_id = C1.flight_id AND C3.boarding_no = C1.boarding_no
WHERE
MD5(MD5(C1.ticket_no)) = '525ac610982920ef37b34aa56a45cd06'
AND MD5(MD5(C2.ticket_no)) = '525ac610982920ef37b34aa56a45cd06'
AND MD5(MD5(C3.ticket_no)) = '525ac610982920ef37b34aa56a45cd06'This query joins the table with itself three times, calculates the MD5 hash of the ticket number twice, and then filters rows based on the condition. This code runs for 8 seconds on my machine with the demo database.
A programmer may now want to avoid this repetition and rewrite the query to the following:
WITH cte AS (
SELECT *, MD5(MD5(ticket_no)) AS double_hash
FROM boarding_passes
)
SELECT COUNT(*)
FROM cte AS C1
JOIN cte AS C2 ON C2.ticket_no = C1.ticket_no AND C2.flight_id = C1.flight_id AND C2.boarding_no = C1.boarding_no
JOIN cte AS C3 ON C3.ticket_no = C1.ticket_no AND C3.flight_id = C1.flight_id AND C3.boarding_no = C1.boarding_no
WHERE
C1.double_hash = '525ac610982920ef37b34aa56a45cd06'
AND C2.double_hash = '525ac610982920ef37b34aa56a45cd06'
AND C3.double_has = '525ac610982920ef37b34aa56a45cd06'The query is now more readable as it avoids repetition. However, the performance dropped, and the query now executes in 13 seconds. Now, when we deploy changes like these to production, we may reason that we need to upscale the database. Seemingly, nothing has changed, but the database is now much slower. With good observability tools, we would see that the query executed behind the scenes is now different, which leads to a performance drop.
Schema Changes
Another problem around databases is when it comes to schema management. There are generally three different ways of modifying the schema: we can add something (table, column index, etc.), remove something, or modify something. Each schema modification is dangerous because the database engine may need to rewrite the table — copy the data on the side, modify the table schema, and then copy the data back. This may lead to a very long deployment (minutes, hours, even months) that we can’t optimize or stop in the middle. Additionally, we typically won’t see the problems when running things locally because we typically run our tests against the latest schema. A good observability solution needs to capture these changes before running in production.
Indexes pose another interesting challenge. Adding an index seems to be safe. However, as is the case with every index, it needs to be maintained over time. Indexes generally improve the read performance because they help us find rows much faster. At the same time, they decrease the modification performance as every data modification must be performed in the table and in all the indexes. However, indexes may not be useful after some time. It’s often the case that we configure an index; a couple of months later, we change the application code, and the index isn’t used anymore. Without good observability systems, we won’t be able to notice that the index isn’t useful anymore and decreases the performance.
Execution Changes
Yet another area of issues is related to the way we execute queries. Databases prepare a so-called execution plan of the query. Whenever a statement is sent to the database, the engine analyzes indexes, data distribution, and statistics of the tables’ content to figure out the fastest way of running the query. Such an execution plan heavily depends on the content of our database and running configuration. The execution plan dictates what join strategy to use when joining tables (nested loop join, merge join, hash join, or maybe something else), which indexes to scan (or tables instead), and when to sort and materialize the results.
We can affect the execution plan by providing query hints. Inside the SQL statements, we can specify what join strategy to use or what locks to acquire. The database may use these hints to improve the performance but may also disregard them and execute things differently. However, we don’t know whether the database used them or not.
Things get worse over time. Indexes may change after the deployment, data distribution may depend on the day of the week, and the database load may be much different between countries when we regionalize our application. Query hints that we provided half a year ago may not be relevant anymore, but our tests won’t catch that. Unit tests are used to verify the correctness of our queries, and the queries will still return the same results. We have simply no way of identifying these changes automatically.
Database Guardrails Is the New Standard
Based on what we said above, we need a new approach. No matter if we run a small product or a big Fortune 500 company, we need a novel way of dealing with databases. Developers need to own their databases and have all the means to do it well. We need good observability and database guardrails — a novel approach that:
- Prevents the bad code from reaching production,
- Monitors all moving pieces to build a meaningful context for the developer,
- It significantly reduces the time to identify the root cause and troubleshoot the issues, so the developer gets direct and actionable insights
We can’t let ourselves go blind anymore. We need to have tools and systems that will help us change the way we interact with databases, avoid performance issues, and troubleshoot problems as soon as they appear in production. Let’s see how we can build such a system. There are four things that we need to capture to build successful database guardrails. Let’s walk through them.
Database Internals
Each database provides enough details about the way it executes the query. These details are typically captured in the execution plan that explains what join strategies were used, which tables and indexes were scanned, or what data was sorted.
To get the execution plan, we can typically use the EXPLAIN keyword. For instance, if we take the following PostgreSQL query:
SELECT TB.*
FROM name_basics AS NB
JOIN title_principals AS TP ON TP.nconst = NB.nconst
JOIN title_basics AS TB ON TB.tconst = TP.tconst
WHERE NB.nconst = 'nm00001'We can add EXPLAIN to get the following query:
EXPLAIN
SELECT TB.*
FROM name_basics AS NB
JOIN title_principals AS TP ON TP.nconst = NB.nconst
JOIN title_basics AS TB ON TB.tconst = TP.tconst
WHERE NB.nconst = 'nm00001'The query returns the following output:
Nested Loop (cost=1.44..4075.42 rows=480 width=89)
-> Nested Loop (cost=1.00..30.22 rows=480 width=10)
-> Index Only Scan using name_basics_pkey on name_basics nb (cost=0.43..4.45 rows=1 width=10)
Index Cond: (nconst = 'nm00001'::text)
-> Index Only Scan using title_principals_nconst_idx on title_principals tp (cost=0.56..20.96 rows=480 width=20)
Index Cond: (nconst = 'nm00001'::text)
-> Index Scan using title_basics_pkey on title_basics tb (cost=0.43..8.43 rows=1 width=89)
Index Cond: (tconst = tp.tconst)This gives a textual representation of the query and how it will be executed. We can see important information about the join strategy (Nested Loop in this case), tables and indexes used (Index Only Scan for name_basics_pkey, or Index Scan for title_basics_pkey), and the cost of each operation. Cost is an arbitrary number indicating how hard it is to execute the operation. We shouldn’t draw any conclusions from the numbers per se, but we can compare various plans based on the cost and choose the cheapest one.
Having plans at hand, we can easily tell what’s going on. We can see if we have an N+1 query issue if we use indexes efficiently and if the operation runs fast. We can get some insights into how to improve the queries. We can immediately tell if a query is going to scale well in production just by looking at how it reads the data. Once we have these plans, we can move on to another part of successful database guardrails.
Integration With Applications
We need to extract plans somehow and correlate them with what our application does. To do that, we can use OpenTelemetry (OTel). OpenTelemetry is an open standard for instrumenting applications. It provides multiple SDKs for various programming languages and is now commonly used in frameworks and libraries for HTTP, SQL, ORM, and other application layers.
OpenTelemetry captures signals: logs, traces, and metrics. They are later captured into spans and traces that represent the communication between services and timings of operations.
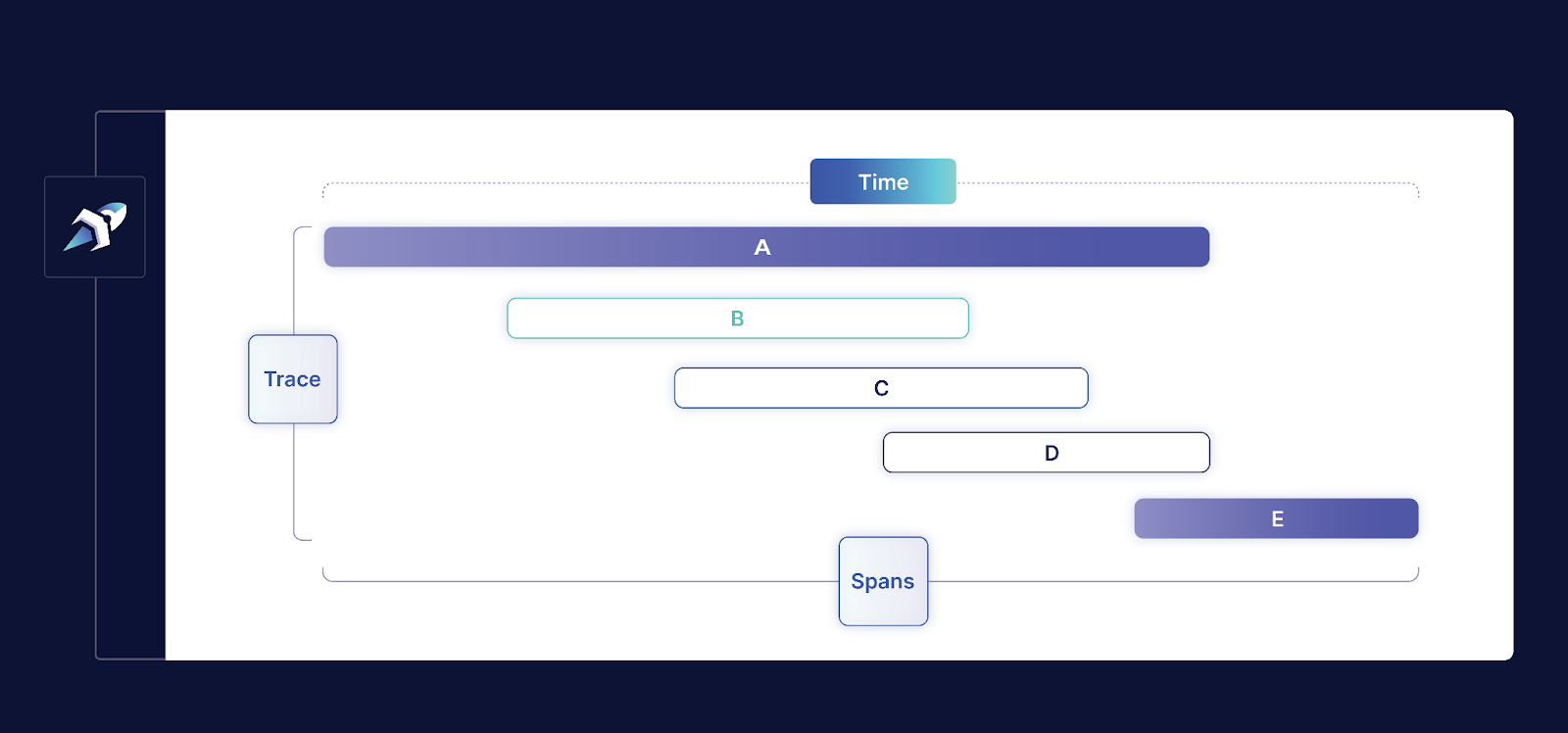
Each span represents one operation performed by some server. This could be file access, database query, or request handling.
We can now extend OpenTelemetry signals with details from databases. We can extract execution plans, correlate them with signals from other layers, and build a full understanding of what happened behind the scenes. For instance, we would clearly see the N+1 problem just by looking at the number of spans. We could immediately identify schema migrations that are too slow or operations that will take the database down. Now, we need the last piece to capture the full picture.
Semantic Monitoring of All Databases
Observing just the local database may not be enough. The same query may execute differently depending on the configuration or the freshness of statistics. Therefore, we need to integrate monitoring with all the databases we have, especially with the production ones.
By extracting statistics, number of rows, running configuration, or installed extensions, we can get an understanding of how the database performs. Next, we can integrate that with the queries we run locally. We take the query that we captured in the local environment and then reason about how it would execute in production. We can compare the execution plan and see which tables are accessed or how many rows are being read. This way, we can immediately tell the developer that the query is not going to scale well in production. Even if the developer has a different database locally or has a low number of rows, we can still take the query or the execution plan, enrich it with the production statistics, and reason about the performance after the deployment. We don’t need to wait for the deployment of the load tests, but we can provide feedback nearly immediately.
The most important part is that we move from raw signals to reasoning. We don’t swamp the user with plots or metrics that are hard to understand or that the user can’t use easily without setting the right thresholds. Instead, we can provide meaningful suggestions. Instead of saying, “CPU spiked to 80%,” we can say, “The query scanned the whole table, and you should add an index on this and that column.” We can give developers answers, not only the data points to reason about.
Automated Troubleshooting
That’s just the beginning. Once we understand what is actually happening in the database, the sky's the limit. We can run anomaly detection on the queries to see how they change over time, if they use the same indexes as before, or if they changed the join strategy. We can catch ORM configuration changes that lead to multiple SQL queries being sent for a particular REST API. We can submit automated pull requests to tune the configuration. We can correlate the application code with the SQL query so we can rewrite the code on the fly with machine-learning solutions.
Summary
In recent years, we observed a big evolution in the software industry. We run many applications, deploy many times a day, scale out to hundreds of servers, and use more and more components. Application Performance Monitoring is not enough to keep track of all the moving parts in our applications. Here at Metis, we believe that we need something better. We need a true observability that can finally show us the full story. And we can use observability to build database guardrails that provide the actual answers and actionable insights. Not a set of metrics that the developer needs to track and understand, but automated reasoning connecting all the dots. That’s the new approach we need and the new age we deserve as developers owning our databases.
Opinions expressed by DZone contributors are their own.
Comments