Strategies for Governing Data Quality, Accuracy, and Consistency
It is easier than ever to accumulate data but also challenges remain to ensure complete and correct data is captured. Discover key techniques and methodologies.
Join the DZone community and get the full member experience.
Join For FreeThis is an article from DZone's 2022 Database Systems Trend Report.
For more:
Read the Report
Introduction
In 2006, mathematician and entrepreneur Clive Humby coined the phrase, "Data is the new oil." The primary point of this comparison is to highlight that, while extremely useful, data must be extracted, processed, and refined before its full value can be realized. Now over fifteen years later, it is easier than ever to accumulate data, but many businesses still face challenges ensuring that the data captured is both complete and correct.
The Impact of Data Quality
At the beginning of a company's data journey, simply loading application data into a database provides valuable information. However, the purpose of data-driven decision-making is to reduce uncertainty. If the data is of low quality, this may introduce additional risk and lead to negative outcomes. To put this into concrete numbers, data quality issues cost organizations about $12.9 million annually, according to a 2021 Gartner survey.
Apart from decision making, reactively detecting and remediating data issues takes a significant amount of developer resources. Specifically, a 2022 Wakefield Research Survey of 300 data professionals highlighted that business stakeholders are often affected by erroneous data before they are found by data teams. Additionally, the survey outlined that data teams spent 793 hours per month fixing data quality-related problems. This is negative in two dimensions. First, teams spend significant effort to fix issues. Secondly, stakeholders lose trust in the quality of data produced.
Moreover, there are numerous and diverse approaches to proactively curate data quality. The remainder of this brief outlines key techniques and methodologies to ensure data is consistently up to standard and matches the expected semantics. Furthermore, these strategies ensure most errors are detected early, and the scope of any late detected problems is quickly understood.
Data Pipeline Contracts
Defining the core requirements for a dataset brings clarity for both the producers and consumers of that dataset. When should this data arrive? How fresh should it be? Are there any expectations on column bounds? Is consistency required with other tables in the data warehouse?
These are just a few of the questions that should be explored so that there is alignment in expectations between the teams that are originating the data and the downstream consumers. Succinctly put, the first step in better data quality practices is declaring what exactly a dataset should look like for a specific use case.
Importantly, the amount of rigor around a specific set of tables should be anchored to both the cost of audit execution and the analytic value those subjects provide. For example, data flowing into an expensive, high-performance database for use in regulatory reporting requires more quality assurances than an exploratory dataset stored in a data lake of distributed object storage.
Data Observability
The journey to better data quality practices starts with looking at individual jobs. However, similar techniques used to reduce risk in business decisions can also be leveraged when improving data governance. Instead of looking at single jobs, a systems-based, ongoing approach is used to offer the necessary context. A comprehensive, cross-organizational strategy will surface issues that are not obvious when looking at single jobs.
In particular, data observability is the term to underscore a comprehensive overview of a data system's health. A more holistic approach shifts the readiness stance from reactive to proactive. A proactive stance limits the scope of remediation needed when errors are introduced — and it also reduces the time spent by data engineers tracking down the provenance of a particular failure.
What Is Data Quality?
Before laying out methodologies for data quality initiatives, it is helpful to define what exactly is meant when discussing data quality. This section will clarify terms and provide examples to make the term "data quality" more concrete. Put simply, data quality prescribes the attributes to which producers and consumers agree a dataset must conform in order to drive accurate, timely downstream analysis.
Data Quality as a Contract
The union of requirements described above constitutes a contract between parties in the data pipeline. This may manifest such that it's explicitly enforced by producers or it may be an implicit set of expectations from users. To shed more light on this relationship, four types of data standards are outlined below:
- Correctness refers to ensuring that the column values for data conform to the expected domain. It essentially is answering this question: Does the data produce correct answers when business calculations are applied?
- Completeness checks ensure that the data contains all the content that is expected for a given dataset. Did the expected amount of data arrive and are all columns populated with the necessary information?
- Consistency may have several different meanings depending on the usage. In this instance, it focuses on whether the data in a table matches what exists in related tables elsewhere in the ecosystem.
- Timeliness is key. Some analysis requires data to be current within a certain time period from the event that generated the data.
Shared Understanding of Dataset Semantics
A key objective is the alignment of expectations between data sources and downstream dependencies. Data quality is a codification of these agreements. In order to have a successful implementation, ownership should be pushed to the teams that have the best understanding and frame of reference.
Metric Definition Ownership
Often, product teams do not have a strong intuition about how their data will be used in downstream analysis. For this reason, they cannot be the sole owners of the data quality metric definition. There must be a negotiation about what is possible for an application to produce and the properties stakeholders need for their reporting to create actionable results.
Producer Constraints and Consumer Requirements
Typically, producers define the rules for a complete and correct dataset from their application. Typical questions for producers are indicated below:
- Is there a reasonable volume of data given the historical row counts for a specific job?
- Are all column values populated as expected? (e.g., no unexpected null values)
- Do column values fall in the anticipated domain?
- Is data being committed at an appropriate cadence?
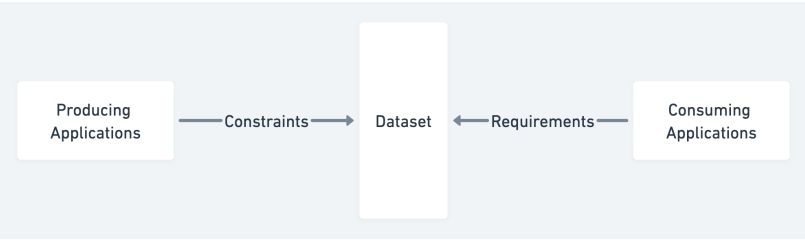
Figure 1: Producer constraints and consumer requirements
Consumers' needs are tightly coupled to the actual usage of the data. Typical questions are as follows:
- Did the complete data arrive in time to publish reports?
- Do column values have referential integrity between facts and dimensions?
- Do business calculations produce results in the expected range?
Frameworks for Promoting Data Standards
Data quality frameworks successfully provide a systemic approach to data quality. A comprehensive approach guides data engineers toward best practices and ensures that a rigorous methodology is consistently applied across an ecosystem.
Audits
Data audits are a central piece of a data standards framework and expose the low-level information about whether a dataset complies with agreed-upon properties. There are several types of audits and methods in which to apply them.
Types of Audits
Below is a brief overview of common data quality audits:
- Row counts within range
- Null counts for column within range
- Column value within domain
- Referential integrity check
- Relationship between column values
- Sum produces non-zero value
Furthermore, there are endless possibilities on what can be defined as an audit, but they all reduce to answering this question: does the content match what the producer intends to send and what the consumer expects to receive? When creating audits, data owners must be cognizant of the tradeoff between the cost of collecting the audit versus the increase in confidence that passing a check will give.
Audits may also be blocking or non-blocking. Blocking audits prevent the failed data pipeline from proceeding until a correction is applied. Conversely, non-blocking audits alert pipeline owners to the failure and allow the pipeline to proceed. Ideally, each consumer will determine which audits are blocking/non-blocking for their specific use case. Exploratory use cases may even be comfortable executing against data that has not yet been audited with the understanding that there are no quality guarantees.
Write-Audit-Publish
Write-Audit-Publish (WAP) is a pattern where all data is written first to a staging location in the database and must pass all blocking audits before the commit is made visible to readers. Typically, this is enabled by special functionality within a database or by swapping the table or view.
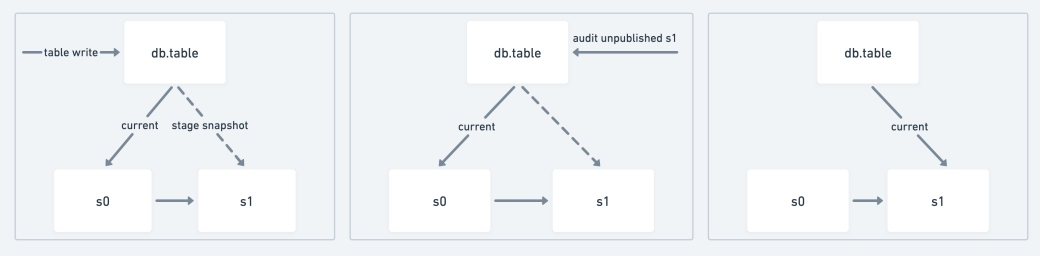
Figure 2: WAP pattern workflow
Specifically, WAP ensures that there are no race conditions where consumers unintentionally read data that has not yet been validated. Proactive action must be taken to perform reads of unaudited data, and it must be a conscious decision by the reader.
Integrated Audits
A variation of WAP that is supported in some database engines is the concept of integrated audits. A job writing data can specify the expected column values or range of values. The engine will then validate that all rows being written conform to those expectations, or otherwise, the write will fail.
Remediation
What happens when errors are introduced into a system? According to the 2022 Wakefield Research Survey referenced in the introduction, the majority of respondents stated that it took four or more hours to detect data issues. Additionally, more than half responded that remediation took an average of nine hours. The goal of a robust data quality strategy is to reduce both of these metrics.
Issue Detection
First, comprehensive audits throughout the dependency graph of a data pipeline reduce the amount of time before erroneous data is identified. Detection at the point of introduction guarantees that the scope of corruption is limited. Additionally, it is more likely that the team that discovers the problem is also able to enact the necessary fixes to remediate the pipeline. Dependent jobs will have high confidence that the data they receive matches expectations, and they can further reduce the scope of validation that is needed.
Measuring Impact
Once an issue is detected, a specific audit failure gives the investigating engineer adequate insight to begin debugging the failure. This is in contrast to the scenario where stakeholders discover errors. In that case, there must be an investigation to track the flow of jobs backward up the dependency graph. This investigation will necessarily increase the time to resolution due to the increase in the scope of jobs that must be evaluated before debugging can occur.
Dataset Provenance and Lineage
Lineage refers to the set of source nodes in a dependency graph upstream from a given execution. With debugging data issues, significant time is saved if there is strong tooling around understanding the provenance of an erroneous dataset. Knowing the places where an error may have been introduced reduces the search space, and consequently allows data engineers to focus their debugging efforts.
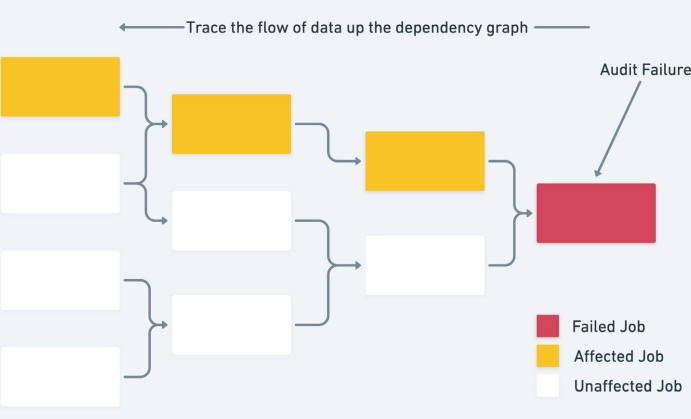
Figure 3: Data provenance
In addition, when an issue is detected post-hoc, lineage tools help assess the set of jobs that are impacted by a data failure. Without such tooling, it is labor intensive to manually search through dependencies and discover all affected operations.
Tracking
Building trust requires a history of delivering on promises. Demonstrating adherence to commitments over time gives consumers confidence in the product of a process. Data quality, just like other relevant company key performance indicators, benefits from mindful collection and review.
Measure Quality Over Time
Tracking metrics on data quality over time allows an organization to guide resources and improve the areas which will have the most impact. Are there certain use cases that are consistently failing audits? Does data typically arrive past service-level objectives? If these questions are getting affirmative responses, it is a signal that there must be a deeper discussion between the responsible team and upstream teams. The data contracts must be re-evaluated if compliance is not possible.
Key Indicators Tied to Impactful Use Cases
Audits must have a clear connection to the ground truth of the organization. This ensures a focus on quality metrics that are directly tied to real, actionable aspects of an organization's data health. In this case, the value of the audit is directly measurable and corresponds one-to-one with the value of the business calculation that it supports.
Conclusion
Businesses are increasingly leveraging data to improve their organizational decision-making. According to a 2021 NewVantage survey, a staggering 97 percent of respondents indicated investment in data initiatives. High standards for data quality establish trust and reduce uncertainty when using data as an input for decision-making.
Data quality frameworks enforce a consistent approach across all processes. Automatically and consistently applied tooling reduces the amount of engineering hours necessary to provide adequate auditing coverage. A high level of coverage results in issues being caught early in the pipeline and improves remediation metrics. A reduction in the amount and scope of impact of errors builds trust with business stakeholders. Finally, a high level of trust between engineering and business teams is a requirement to build a successful data-driven culture.
This is an article from DZone's 2022 Database Systems Trend Report.
For more:
Read the Report
Opinions expressed by DZone contributors are their own.
Comments