A Guide to Data Labeling and Annotating: Importance, Types, and Best Practices
Labeling and annotating data are crucial in the digital era to improve decision-making. They provide context and structure to raw data.
Join the DZone community and get the full member experience.
Join For FreeData is a vital part of making informed decisions for businesses and organizations across a range of industries today. Nevertheless, raw data alone is rarely sufficient for deriving insights and guiding decision-making. By providing context and structure to raw data, annotations, and labels help make sense of it.
The annotation of data refers to the addition of metadata or descriptive information to raw data, such as images, videos, or texts. Data can be categorized and organized using labels, tags, or captions. Annotated data can be labeled manually or automatically to make it easier to interpret and utilize by assigning specific attributes or values.
Analyzing data with data annotations and labels enhances accuracy and effectiveness. Machine learning algorithms and other data analysis techniques can be applied to annotated and labeled data to gain better insights and make better decisions because they provide context and structure.
Thus, businesses and organizations must recognize that data annotation and labeling are critical in the data-driven digital age. For accurate decision-making, these processes are crucial to unlocking the full potential of raw data.
Data Annotation Differs From Labeling
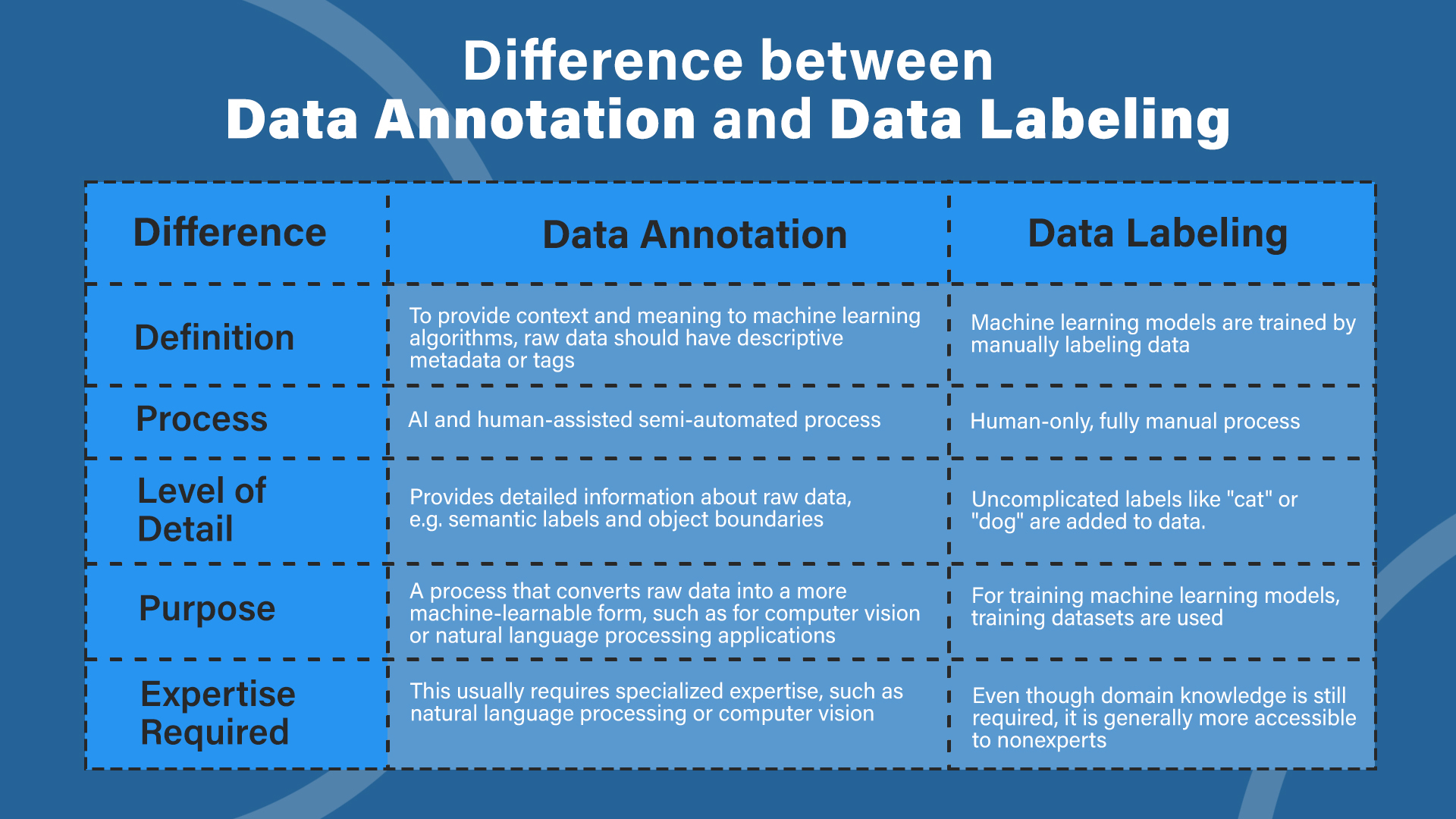
A large part of machine learning and artificial intelligence (AI) involves labeling and annotation of data. A descriptive element is added to raw data to make it more usable and meaningful. A label or tag is added to data to help machine learning algorithms categorize or classify it. By adding text, images, and videos to annotations, deeper insights can be gained into data.
Their Purpose: What Do They Do?
A number of purposes can be served by labeling and annotating data, including but not limited to:
- Data annotation is commonly used for the training of machine learning models. Machine learning algorithms can make predictions based on annotated data by adding annotations to data.
- By providing additional information about the content of the data, annotations can also assist in improving search results. The use of tags in a blog post, for example, can assist search engines in understanding the topic covered in the post and, as a result, improve its ranking in search engine results.
- Data annotation can be used to enhance user experiences by providing more personalized and relevant recommendations or content. It is possible to provide personalized recommendations by annotating user behavior data in order to identify patterns and preferences.
- In addition to providing context and information, data annotation can also be used to facilitate data analysis. By adding annotations to financial data, for example, it is possible to identify trends and anomalies that can then be used to make informed business decisions.
How Do Data Annotation and Labeling Work?
Most data is labeled and annotated by humans, but some tasks can be automated by machine learning algorithms. Here are a few examples:
- Customer feedback, survey results, and social media are all sources of raw data.
- Data scientists determine what types of labels and annotations are needed, as well as what types of labels to use.
- Humans add labels to data through the use of specialized tools and software.
- Data scientists ensure that labeled data is accurate and consistent.
- With the use of labeled data, machine learning models can be trained for various applications.
Types of Annotations and Labels Most Commonly Used
- A label, bounding box, or point is annotated on an image to enable object recognition and detection.
- Identifying and highlighting key phrases or words in a text.
- Transcribing or labeling audio and video content in order to analyze and interpret it.
What Are the Best Practices for Data Labels and Annotations?
To start with, the accuracy and consistency of data labels and annotations can be ensured by adhering to a few best practices. It's crucial to clearly define the labeling or annotation task, including clear instructions, guidelines, and criteria. This avoids ambiguity and gives annotators clear instructions.
Also, the annotators must be trained and monitored to make sure their labels are accurate and consistent. To accomplish this, we should provide clear feedback and guidance when issues arise and review and check the labeled data on a regular basis. It enables errors and inconsistencies to be caught early on and corrected promptly.
A culture of collaboration and communication between annotators and data scientists should be encouraged. It includes providing a platform for healthy discussion and positive feedback exchange, as well as encouraging open and honest communication about any issues or concerns that may arise. A culture of collaboration and communication will facilitate the resolution of issues and discrepancies and ensure the quality of the labeled data.
How Should I Choose a Data Annotation or Data Labeling Company?
Now that we have read about the advantages and uses of data annotation and labeling let’s know about what it takes to choose the best annotation company.
To start with, you should make certain that the company you are about to choose possesses the precise expertise in the industry or application you require, as well as a positive reputation for providing high-quality, accurate results. A team of trained annotators should be available for your company, and the annotators should be knowledgeable about your domain and understand your specific requirements. Don't forget to ask for references to verify the expert's claims, experience, and expertise.
Quality Checks
Ensure consistency and accuracy through stringent quality control processes. Perform multiple rounds of quality checks on the labeled data to ensure quality. It is important to resolve any issues that arise during the labeling process.
Secure Data
Use robust data security protocols to prevent unauthorized access to your data. Secure, encrypted, and regularly backed-up systems should prevent unauthorized access. Make sure they adhere to laws like GDPR, HIPAA, and CCPA that protect personal data.
Scalability
It is important to select a labeling company that can handle both your current and future labeling requirements. The capability to handle large amounts of data is a crucial characteristic to look for. Flexible pricing models should accommodate your budget and project requirements.
Automation
Tools and software should be used to streamline the labeling process. A user-friendly interface should enable annotators to provide you with feedback. Artificial intelligence (AI) is an effective way to speed up, improve, and automate labeling processes.
Provide Excellent Customer Service
Make sure the company you choose has excellent customer service and support. Your project manager should not only answer your questions and provide regular updates on your project but also respond to your concerns. Assigning a single point of contact for the entire project is helpful when working with companies.
Summary
Data annotations and labeling are vital components of a data-driven digital age. Using them enhances the accuracy and effectiveness of decision-making by adding context and structure to raw data. Adding annotations and labels to data assists machine learning algorithms in categorizing and classifying data, thereby allowing the algorithms to gain a better understanding of the data and make more informed decisions. Further, they can enhance user experiences, improve search results, and facilitate data analysis. It is important to clearly define labeling tasks, provide accurate and consistent feedback, and foster a culture that promotes collaboration and communication when labeling and annotating data. Expertise, quality assurance, data security, scalability, and automation should all be considered when choosing a data annotation or labeling firm.
Opinions expressed by DZone contributors are their own.
Comments