Semi-Supervised Learning: How to Overcome the Lack of Labels
Dive into the concept of semi-supervised learning and explore its principles, applications, and potential to revolutionize how we approach data-hungry ML tasks.
Join the DZone community and get the full member experience.
Join For FreeAll successfully implemented machine learning models are backed by at least two strong components: data and model. In my discussions with ML engineers, I heard many times that, instead of spending a significant amount of time on data preparation, including labeling for supervised learning, they would rather spend their time on model development. When it comes to most problems, labeling huge amounts of data is way more difficult than obtaining it in the first place.
Unlabeled data fails to provide the desired accuracy during training, and labeling huge datasets for supervised learning can be time-consuming and expensive. What if the data labeling budget was limited? What data should be labeled first? These are just some of the daunting questions facing ML engineers who would rather be doing productive work instead.
In reality, there are many fields where a lack of labels is natural. Below are some examples of fields where we can observe a lack of labels and the reasons why this occurs.
Researchers and practitioners have developed several strategies to address these labeling challenges:
- Transfer learning and domain adaptation
- Synthetic data generation
- Semi-supervised learning
- Active learning
Among these approaches, semi-supervised learning stands out as a particularly promising solution. This technique allows leveraging both small amounts of labeled data and much larger amounts of unlabeled data simultaneously. By combining the strengths of supervised and unsupervised learning, semi-supervised learning offers a potential solution to the labeling challenge while maintaining model performance.
In this article, we will dive into the concept of semi-supervised learning and explore its principles, applications, and potential to revolutionize how we approach data-hungry ML tasks.
Understanding Semi-Supervised Learning
Semi-supervised learning is a machine learning approach that combines supervised and unsupervised learning by training models with a small amount of labeled data and a larger pool of unlabeled data. This approach can be represented mathematically as follows:
- Let DS: (x, y) ~ p(x,y) be a small labeled dataset, and DU: x ~ p(x) be a large unlabeled dataset. As usual, we use labeled data for supervised learning, and unlabeled data for unsupervised learning.
- In semi-supervised learning, we use both datasets to minimize a loss function that combines supervised and unsupervised components: L = μsLs + μu Lu.
- This loss function allows the model to learn from both labeled and unlabeled data simultaneously. It is worth mentioning that this method is more successful with a larger amount of labeled data.
Semi-supervised learning is especially useful when acquiring a comprehensive set of labeled data is too costly or impractical. However, its effectiveness is dependent on the assumption that unlabeled data can provide meaningful information for model training, which is not always the case.
The difficulty lies in balancing the use of labeled and unlabeled data, as well as ensuring that the model does not reinforce incorrect pseudo-labels generated by the unlabeled data.
Core Concepts in Semi-Supervised Learning
The research community has introduced several semi-supervised learning concepts. Let’s dive into the most impactful ones below.
Confidence and Entropy
The main idea of entropy minimization is to ensure that a classifier trained on labeled data makes confident predictions on unlabeled data as well (as in, produces predictions with minimal entropy). Entropy, in this context, refers to the uncertainty of the model's predictions. Lower entropy indicates higher confidence. This approach has been proven to have a regularizing effect on the classifier.
A similar concept is pseudo labeling, also known as self-training in some literature, which involves:
- Asking the classifier to predict labels for unlabeled data.
- Using the most confidently predicted samples as additional ground truth for the next iteration of training.
This is a basic type of semi-supervised learning and should be applied carefully. The reinforcing effect on the model can potentially amplify initial biases or errors if not properly managed.
Other examples of similar methods include:
- Co-training
- Multi-view training
- Noisy student
The general process for these methods typically follows these stages:
- A model is first trained on a small set of labeled data.
- The model generates pseudo-labels by predicting labels for a larger set of unlabeled data.
- The most confident labels (with minimal entropy) are chosen to enrich the training dataset.
- The model is retrained using the enriched dataset from step 3.
This iterative process aims to leverage the model's growing confidence to improve its performance on both labeled and unlabeled data.
Label Consistency and Regularization
This approach is based on the idea that the prediction should not change the class if we apply simple augmentation to the sample. Simple augmentation refers to minor modifications of the input data, such as slight rotations, crops, or color changes for images.
The model is then trained on unlabeled data to ensure that predictions between a sample and its augmented version are consistent. This concept is similar to ideas from self-supervised learning approaches based on consistency constraints.
Examples of techniques using this approach include:
- Pi-Model
- Temporal Ensembling
- Mean Teacher
- FixMatch algorithm
- Virtual Adversarial Training (VAT)
The main steps in this approach are:
- Take an unlabeled sample.
- Create a few different views (augmentations) of the chosen sample.
- Apply a classifier and ensure that the predictions for these views are roughly similar.
This method leverages the assumption that small changes to the input should not dramatically alter the model's prediction, thus encouraging the model to learn more robust and generalizable features from the unlabeled data.
Unlike the Confidence and Entropy approach, which focuses on maximizing prediction confidence, Label Consistency and Regularization emphasizes the stability of predictions across similar inputs. This can help prevent overfitting to specific data points and encourage the model to learn more meaningful representations.
Generative Models
Generative models in semi-supervised learning utilize a similar method to transfer learning in supervised learning, where features learned on one task can be transferred to other downstream tasks.
However, there's a key difference: generative models are able to learn the data distribution p(x), generate samples from this distribution, and ultimately enhance supervised learning by improving the modeling of p(y|x) for a given sample x with a given target label y. This approach is particularly useful in semi-supervised learning because it can leverage large amounts of unlabeled data to learn the underlying data distribution, which can then inform the supervised learning task.
The most popular types of generative models used to enhance Semi-Supervised Learning are:
- GANs (Generative Adversarial Networks)
- VAEs (Variational Autoencoders)
The procedure typically follows these steps:
- Construct both generative and supervised parts of the loss function.
- Train generative and supervised models simultaneously using the combined loss function.
- Use the trained supervised model for the target task.
In this process, the generative model learns from both labeled and unlabeled data, helping to capture the underlying structure of the data space. This learned structure can then inform the supervised model, potentially improving its performance, especially when labeled data is scarce.
Graph-Based Semi-Supervised Learning
Graph-based semi-supervised learning methods employ a graph data structure to represent both labeled and unlabeled data as nodes. This approach is particularly effective in capturing complex relationships between data points, making it useful when the data has inherent structural or relational properties.
In this method, labels are propagated through the graph. The number of paths from an unlabeled node to labeled nodes aids in determining its label. This approach leverages the assumption that similar data points (connected by edges in the graph) are likely to have similar labels.
The procedure typically follows these steps:
- Construct a graph with nodes representing data points (both labeled and unlabeled).
- Connect nodes by edges, often based on similarity measures between data points (e.g., k-nearest neighbors or Gaussian kernel).
- Use graph algorithms (such as Label Propagation or Graph Neural Networks) to spread labels from labeled nodes to unlabeled nodes.
- Assign labels to unlabeled nodes based on the propagated information.
- Optionally repeat the process to refine labels on unlabeled nodes.
This method is particularly advantageous when dealing with data that has a natural graph structure (e.g., social networks, citation networks) or when the relationship between data points is crucial for classification. However, performance can be sensitive to the choice of graph construction method and similarity measure. Common algorithms in this approach include Label Propagation, Label Spreading, and more recently, Graph Neural Networks.
Examples in Research
Semi-supervised learning has led to significant advances across various domains, including speech recognition, web content classification, and text document analysis. These advancements have not only improved performance in tasks with limited labeled data but have also introduced novel approaches to leveraging unlabeled data effectively.
Below, I present a selection of papers that, in my view, represent some of the most impactful and interesting contributions to the field of semi-supervised learning. These works have shaped our understanding of the subject and continue to influence current research and applications.
Temporal Ensembling for Semi-Supervised Learning (2017): Laine and Aila
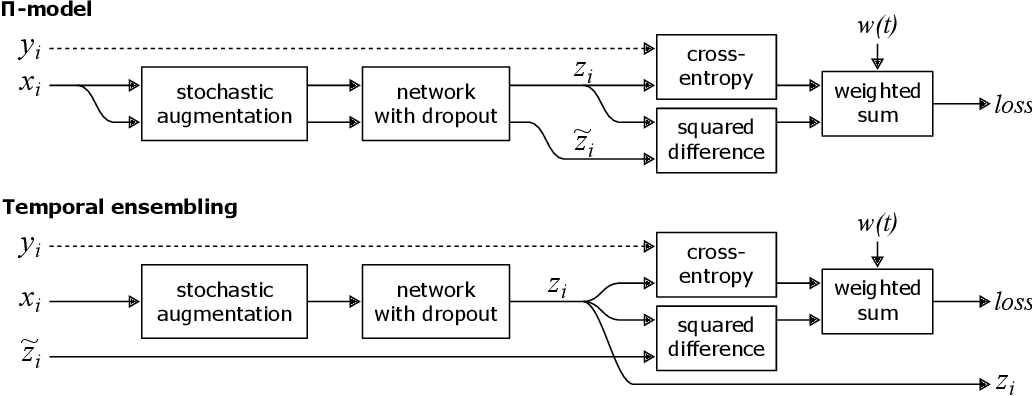
This paper introduced the concept of consistency regularization, a cornerstone of many subsequent semi-supervised learning methods. The authors first proposed the Pi-Model, which applies stochastic augmentations to each unlabeled input twice and encourages consistent predictions for both versions. This approach leverages the idea that a model should produce similar outputs for perturbed versions of the same input.
Building upon the Pi-Model, the authors then introduced Temporal Ensembling. This method addresses a key limitation of the Pi-Model by reducing the noise in the consistency targets. Instead of comparing predictions from two concurrent passes, Temporal Ensembling maintains an exponential moving average (EMA) of past predictions for each unlabeled example. This EMA serves as a more stable target for the consistency loss, effectively ensembling the model's predictions over time.
The Temporal Ensembling approach significantly improved upon the Pi-Model, demonstrating better performance and faster convergence. This work had a substantial impact on the field, laying the foundation for numerous consistency-based methods in SSL and showing how leveraging a model's own predictions could lead to improved learning from unlabeled data.
Virtual Adversarial Training (2018): Miyato et al.
Virtual Adversarial Training (VAT) cleverly adapted the concept of adversarial attacks to semi-supervised learning. The idea originated from the well-known phenomenon of adversarial examples in image classification, where small, imperceptible perturbations to an input image could dramatically change a model's prediction. Researchers discovered these perturbations by using backpropagation to maximize the change in the model's output but with respect to the input rather than the model weights.
VAT's key innovation was to apply this adversarial perturbation concept to unlabeled data in a semi-supervised setting. Instead of using backpropagation to find perturbations that change the model's prediction, VAT uses it to find perturbations that would most significantly alter the model's predicted distribution. The model is then trained to resist these perturbations, encouraging consistent predictions even under small, adversarial changes to the input.
This method tackled the problem of improving model robustness and generalization in SSL. VAT's impact was significant, showing how adversarial techniques could be effectively used in SSL and opening up new avenues for research at the intersection of adversarial robustness and semi-supervised learning. It demonstrated that principles from adversarial machine learning could be repurposed to extract more information from unlabeled data, leading to improved semi-supervised learning performance.
Mean Teacher (2017): Tarvainen and Valpola
The Mean Teacher method introduced a simple yet effective approach to creating high-quality consistency targets in SSL. Its key innovation was the use of an exponential moving average of model weights to create a “teacher” model, which provides targets for the "student" model. This addressed the problem of stabilizing training and improving performance in SSL.
While both Mean Teacher and Temporal Ensembling use EMA, they apply it differently:
- Temporal Ensembling applies EMA to the predictions for each data point over different epochs. This creates stable targets but updates slowly, especially for large datasets where each example is seen infrequently.
- Mean Teacher, on the other hand, applies EMA to the model weights themselves. This creates a teacher model that's an ensemble of recent student models. The teacher can then generate consistency targets for any input, including unseen augmentations, allowing for more frequent updates.
This subtle difference allows Mean Teacher to adapt more quickly to new data and provide more consistent targets, especially early in training and for larger datasets. It also enables the use of different augmentations for the student and teacher models, potentially capturing a broader range of invariances.
Mean Teacher demonstrated that simple averaging techniques could lead to significant improvements in SSL performance. It inspired further research into teacher-student models in SSL and showed how the ideas from Temporal Ensembling could be extended and improved upon.
Unsupervised Data Augmentation (2020): Xie et al.
Unsupervised Data Augmentation (UDA) leveraged advanced data augmentation techniques for consistency regularization in SSL. The key innovation was the use of state-of-the-art data augmentation methods, particularly in NLP tasks where such techniques were less explored.
By “advanced data augmentation,” the authors refer to more sophisticated transformations that go beyond simple perturbations:
- For image tasks: UDA uses RandAugment, which automatically searches for optimal augmentation policies. This includes combinations of color adjustments, geometric transformations, and various filters.
- For text tasks: UDA introduces methods like back-translation and word replacing using TF-IDF. Back-translation involves translating a sentence to another language and then back to the original, creating a paraphrased version. TF-IDF-based word replacement swaps words with synonyms while preserving the sentence's overall meaning.
These advanced augmentations create more diverse and semantically meaningful variations of the input data, helping the model learn more robust representations. UDA addressed the problem of improving SSL performance across various domains, with a particular focus on text classification tasks. Its impact was significant, demonstrating the power of task-specific data augmentation in SSL and achieving state-of-the-art results in several benchmarks with limited labeled data.
The success of UDA highlighted the importance of carefully designed data augmentation strategies in semi-supervised learning, especially for domains where traditional augmentation techniques were limited.
FixMatch (2020): Sohn et al.
FixMatch represents a significant simplification in semi-supervised learning techniques while achieving state-of-the-art performance. The key innovation lies in its elegant combination of two main ideas:
- Consistency regularization: FixMatch uses strong and weak augmentations on unlabeled data. The model's prediction on weakly augmented data must match its prediction on strongly augmented data.
- Pseudo-Labeling: It only retains pseudo-labels from weakly augmented unlabeled data when the model's prediction is highly confident (above a set threshold).
What sets FixMatch apart is its use of extremely strong augmentations (like RandAugment) for the consistency regularization component, coupled with a simple threshold-based pseudo-labeling mechanism. This approach allows the model to generate reliable pseudo-labels from weakly augmented images and learn robust representations from strongly augmented ones.
FixMatch demonstrated remarkable performance with extremely limited labeled data, sometimes using as few as 10 labeled examples per class. Its success showed that a well-designed, straightforward SSL algorithm could outperform more complex methods, setting a new benchmark in the field and influencing subsequent research in low-label regimes.
Noisy Student (2020): Xie et al.
Noisy Student introduced an iterative self-training approach with noise injection for SSL, marking a significant milestone in the field. The key innovation was the use of a large EfficientNet model as a student, trained on the noisy predictions of a teacher model, with the process repeated iteratively.
What sets Noisy Student apart is its groundbreaking performance:
- Surpassing supervised learning: Notably, it was the first SSL method to outperform purely supervised learning even when a large amount of labeled data was available. This breakthrough challenged the conventional wisdom that SSL was only beneficial in low-labeled data regimes.
- Scale and effectiveness: The method demonstrated that by leveraging a large amount of unlabeled data (300M unlabeled images), it could improve upon state-of-the-art supervised models trained on all 1.28M labeled ImageNet images.
- Noise injection: The "noisy" aspect involves applying data augmentation, dropout, and stochastic depth to the student during training, which helps in learning more robust features.
Noisy Student pushed the boundaries of performance on challenging, large-scale datasets like ImageNet. It showed that SSL techniques could be beneficial even in scenarios with abundant labeled data, expanding the potential applications of SSL. The method also inspired further research into scalable SSL techniques and their application to improve state-of-the-art models in various domains.
Noisy Student's success in outperforming supervised learning with substantial labeled data available marked a paradigm shift in how researchers and practitioners view the potential of semi-supervised learning techniques.
Semi-Supervised Learning With Deep Generative Models (2014): Kingma et al.
This seminal paper introduced a novel approach to semi-supervised learning using variational autoencoders (VAEs). The key innovation lies in how it combines generative and discriminative learning within a single framework.
Central to this method is the combined loss function, which has two main components:
- Generative component: This part of the loss ensures that the model learns to reconstruct input data effectively, capturing the underlying data distribution p(x).
- Discriminative component: This part focuses on the classification task, optimizing for accurate predictions on labeled data.
The combined loss function allows the model to simultaneously learn from both labeled and unlabeled data. For labeled data, both components are used. For unlabeled data, only the generative component is active, but it indirectly improves the discriminative performance by learning better representations.
This approach addressed the problem of leveraging unlabeled data to improve classification performance, especially when labeled data is scarce. It opened up new directions for using deep generative models in SSL. The method also demonstrated how generative models could improve discriminative tasks, bridging the gap between unsupervised and supervised learning and inspired a wealth of subsequent research at the intersection of generative modeling and semi-supervised learning.
This work laid the foundation for many future developments in SSL, showing how deep generative models could be effectively utilized to extract useful information from unlabeled data for classification tasks.
Examples of Application
Semi-supervised learning has led to significant advances across various domains, demonstrating its versatility and effectiveness in handling large amounts of unlabeled data. Here are some notable applications:
1. Speech Recognition
In 2021, Meta (formerly Facebook) used self-training with SSL on a base model trained with 100 hours of labeled audio and 500 hours of unlabeled data. This approach reduced the word error rate by 33.9%, showcasing SSL's potential in improving speech recognition systems.
2. Web Content Classification
Search engines like Google employ SSL to classify web content and improve search relevance. This application is crucial for handling the vast and constantly growing volume of web pages, enabling more accurate and efficient content categorization.
3. Text Document Classification
SSL has proven effective in building text classifiers. For instance, the SALnet text classifier developed by Yonsei University utilizes deep learning neural networks like LSTM for tasks such as sentiment analysis. This demonstrates SSL's capability in managing large, unlabeled datasets in natural language processing tasks.
4. Medical Image Analysis
In 2023, researchers at Stanford University utilized SSL techniques to enhance the accuracy of brain tumor segmentation in MRI scans. By leveraging a small set of labeled images alongside a larger pool of unlabeled data, they achieved a 15% improvement in tumor detection accuracy compared to fully supervised methods. This application highlights SSL's potential in medical imaging, where labeled data is often scarce and expensive to obtain, but unlabeled data is abundant.
Conclusion
Semi-supervised learning (SSL) has established itself as a crucial machine learning technique, effectively bridging the gap between the abundance of unlabeled data and the scarcity of labeled data. By ingeniously combining supervised and unsupervised learning approaches, SSL offers a pragmatic and efficient solution to the perennial challenge of data labeling. This article has delved into various SSL methodologies, from the foundational consistent regularization techniques like Temporal Ensembling to cutting-edge approaches such as FixMatch and Noisy Student.
The versatility of SSL is prominently displayed in its successful implementation across a wide spectrum of domains, including speech recognition, web content classification, and text document analysis. In an era where data generation far outpaces our ability to label it, SSL emerges as a pivotal development in Machine Learning, empowering researchers and practitioners to harness the potential of vast unlabeled datasets.
As we look to the future, SSL is poised to assume an even more significant role in the AI and machine learning landscape. While challenges persist, such as enhancing performance with extremely limited labeled data and adapting SSL techniques to more intricate real-world scenarios, the field's rapid advancements suggest a trajectory of continued innovation. These developments may lead to groundbreaking approaches in model training and data interpretation
The core principles of SSL are likely to influence and intersect with other burgeoning areas of machine learning, including few-shot learning and self-supervised learning. This cross-pollination of ideas promises to further expand SSL's impact and potentially reshape our understanding of learning from limited labeled data.
SSL represents not just a set of techniques, but a paradigm shift in how we approach the fundamental problem of learning from data. As it continues to evolve, SSL may well be the key to unlocking the full potential of the vast, largely unlabeled data resources that characterize our digital age.
Opinions expressed by DZone contributors are their own.
Comments