A Deep Dive Into the Call Chain Relationship Between Presto, Hive, and Alluxio
Understanding how Presto+Hive+Alluxio work together and the flow from SQL query to low-level file system operations is key to tuning performance.
Join the DZone community and get the full member experience.
Join For FreeAlluxio is commonly used with Presto and Hive to accelerate queries. Understanding how Presto+Hive+Alluxio work together and the flow from SQL query to low-level file system operations is key to tuning performance. This post will dive into the relationship between Presto, Hive, and Alluxio. We will walk you through how a SQL query executes in Presto and Hive and where Alluxio fits in.
1. An Overview of the SQL Lifecycle
Before discussing how to integrate with Presto and Alluxio, we need to know about the SQL lifecycle since Alluxio acts on one of the stages in the SQL lifecycle.
Generally, SQL is submitted from a SQL client to a SQL engine (e.g., Hive, Presto, Impala, Spark), where the SQL client is often provided by the SQL engine. We will discuss the SQL lifecycle in Hive and Presto here.
1.1 Hive SQL Lifecycle
Hive has three main components:
- Hive Client.
- Hive Server.
- Hive Metastore.
Hive Client is for submitting SQL to Hive Server.
Hive Metastore is used for storing the metadata of tables in the data warehouse. Noting the fact that tables are stored in the data warehouse, which is an abstract entity. The architecture that combines Hive and Hadoop (YARN + MapReduce + HDFS) is just one of the implementations of the data warehouse. In such an implementation, HDFS stores underlying data, while Hive Metastore is used for managing the metadata of tables. No matter which implementation users adopt, they always use tables to manage business data and interact with tables in SQL.
The table is a data structure built on original files. Therefore, if we want to interact with tables, we need to know about the data structure of the specific table and how the table maps to the files. Hive Metastore does this thing for us. It stores the table’s metadata, such as:
- How many columns are there in the table?
- What are the column names and column types in the table?
- Where to store the underlying data files for the table?
- What is the format to store the data files for the table?
- How many partitions are there in the table?
- How many rows are there in total in this table? (statistics-related information)
You may find that some of them are described in the DDL statement, and some of them are stored behind it. This is the way Hive deals with a DDL statement. Also, this is why Hive Server knows how to query a table.
Hive Server accept SQL request from Hive Client, and It is responsible for parsing and executing SQL. Once SQL is received in the Hive Server, it will be parsed and converted to CST (Concrete Syntax Tree), which is used for checking basic syntax and further building the AST (Abstract Syntax Tree). If you want a deeper understanding of the difference between CST and AST, you can read this article Abstract vs. Concrete Syntax Trees — Eli Bendersky’s website. Based on the AST, Hive Server will go ahead and build a Logical Execution Plan, which includes all the operators that will be executed to complete the SQL querying. So far, the only thing missing in the Logical Execution Plan is physical information, such as the data files LOCATION of the table to be queried. The Hive Server sends requests to the Hive Metastore for the required physical information and then builds a Physical Execution Plan.
Finally, the Hive Server executes the Physical Execution Plan to complete the SQL submitted from the Hive Client. If the submitted SQL includes computing logic (for example, there is a GROUP BY statement that would be converted to an Aggregate Operator, or there is a JOIN statement that would be converted to a HashJoin Operator), Hive Server will create a MapReduce task given the Physical Execution Plan, and submit it to Hadoop, and wait for the result. If the submitted SQL is without computing logic (for example, SELECT * FROM my_database.my_table) Hive Server will scan the table directly according to the LOCATION provided by Hive Metastore.
1.2 Presto SQL Lifecycle
Presto has three main components:
- Presto Client
- Presto Coordinator
- Presto Worker
Presto Client is for submitting Presto SQL to the Presto Coordinator. This is similar to Hive Client.
Presto Coordinator receives Presto SQL that comes from the Presto Client and parses the SQL to build CST, AST, Logical Execution Plan, and Physical Execution Plan sequentially. Similar to Hive Server, Presto requests Hive Metastore to get physical table metadata and build a Physical Execution Plan based on a Logical Execution Plan. Finally, the Presto Coordinator splits the Physical Execution Plan into tasks and schedules the Presto Worker to execute them.
The Presto Worker receives tasks from the Presto Coordinator and is responsible for executing a specified operator defined in the Physical Execution Plan. A Physical Execution Plan is a Directed Acyclic Graph, and Presto Workers interact with each other according to the Plan. It is worth noting that the TableScan Operator is related to scanning the underlying data of a specific table, so Presto Worker only interacts with Alluxio during the time it executes the TableScan Operator.
2. When and How Does Presto Load the Alluxio Client JAR?
Presto SQL locates tables by catalog name, schema name, and table name. For example, the following SQL is going to scan the table whose catalog name, schema name, and table name are hive, tpcds, and store_sales, respectively.
SELECT * FROM hive.tpcds.store_sales
For each Presto node, there must be a file hive.properites in <PRESTO_HOME>/etc/catalog to configure the catalog hive. As hive.properties has set connector-name=hive-hadoop2, Presto Worker will connect to the catalog hive with connector hive-hadoop2. During the time a Presto Worker needs to execute the TableScan Operator, it loads the classes located in <PRESTO_HOME>/plugin/hive-hadoop2 with a PluginClassLoader whose parent classloader is AppClassLoader. Those classes are used in the hive-hadoop2 connector. This is why we need to put the alluxio-client.jar into <PRESTO_HOME>/plugin/hive-hadoop2 directory.
3. How Does Presto Know the Exact Filesystem Class To Use According To Different LOCATION Schemas?
Noting the fact the Hive table is able to store underlying data in different storages by specifying different LOCATION schemas (e.g., hdfs://, s3://, oss://, cos://, alluxio://). For example, a typical LOCATION property of a Hive table would be:
hdfs://namenode:8020/user/warehouse/my_db/my_table
Where data is stored in HDFS, and the following LOCATION property indicates that data is stored in S3:
s3://mybacket/my_db/my_table
Also, Alluxio can be regarded as an underlying storage for a Hive table:
alluxio://master:19998/my_db/my_table (this is for Alluxio 2.x)
alluxio:/my_db/my_table (this is for Alluxio 300~)
Presto uses different FileSystem implementations for different schema. The Presto Coordinator gets the LOCATION URI by requesting the thrift API of Hive Metastore, and then building the Physical Execution Plan and sending tasks to Presto Workers to complete the plan. When Presto Worker begins to execute the TableScan operator in the Physical Execution Plan, it needs to read the underlying file of the table by requesting the LOCATION URI. In order to access the underlying storage correctly, the Presto Worker needs to load the corresponding FileSystem class and use its object. But how does the Presto Worker know which FileSytem class should be loaded?
At this time, the Presto Worker is going to load all the JARs in the <PRESTO_HOME>/plugin/hive-hadoop2, and then load all the implementations of different interfaces by scanning META/services/<INTERFACE_NAME> in different JARs with Java SPI. In terms of the FileSystem interface, Presto Worker would construct a map to store a mapping from LOCATION schema to its implementation class full name (This map locates at org.apache.hadoop.fs.FileSystem.SERVICE_FILE_SYSTEMS in com.facebook.presto.hadoop:hadoop-apache). For example, after constructing the map, the Presto Worker would have the following key-value mapping:
"alluxio" --> {Class@26776} "class alluxio.hadoop.FileSystem"
"ftp" -> {Class@26261} "class org.apache.hadoop.fs.ftp.FTPFileSystem"
"hdfs" -> {Class@26285} "class org.apache.hadoop.hdfs.DistributedFileSystem"
...
As we can see, based on the map above, the Presto Worker is able to initialize the object of the class alluxio.hadoop.FileSystem to process the LOCATION with alluxio:// schema.
4. How Does Presto Trigger Alluxio’s Position Read Operation?
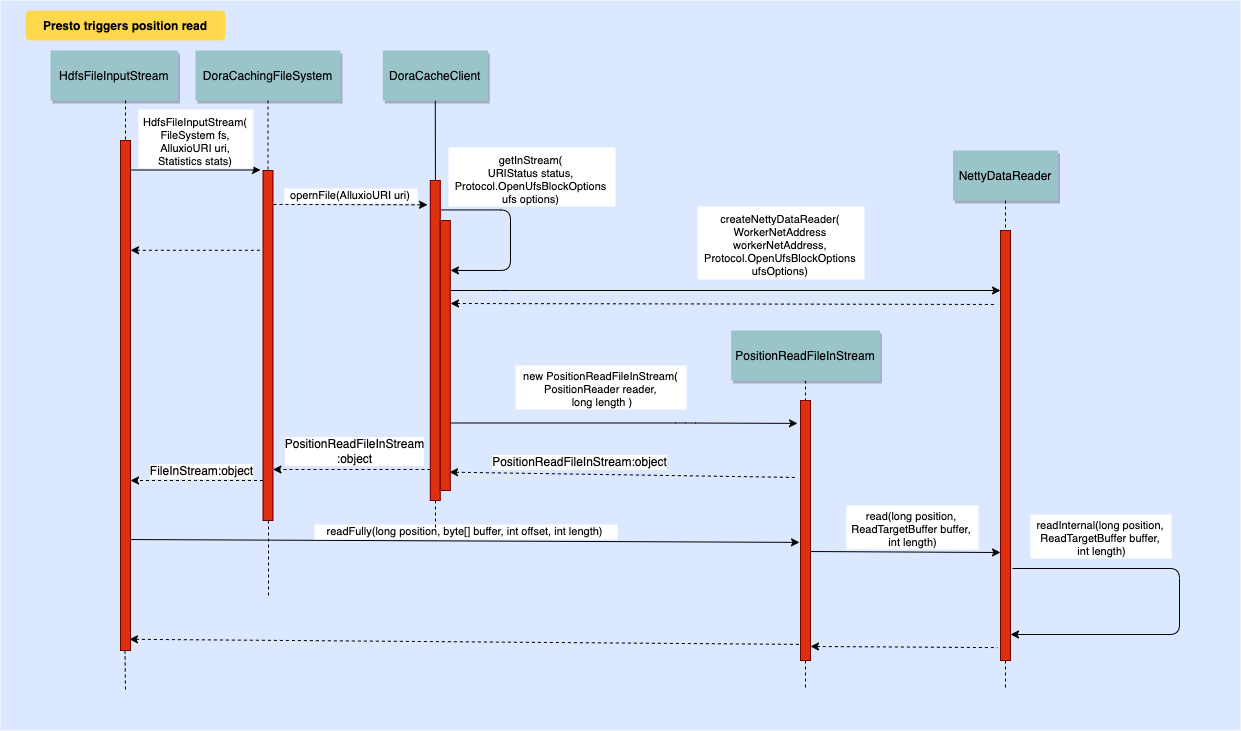
For each read operation on Parquet or ORC files, Presto will utilize the corresponding HDFS-compatible file system to open the file. When Alluxio is enabled, Presto will use DoraCachingFileSystem to handle all file-level operations. This results in Presto getting an instance of PositionReadFileInStream, which extends HdfsFileInputStream, as the input stream of the data file. Notably, when reading columnar formats like Parquet and ORC, Presto leverages position reads over sequence reads to minimize reading unnecessary data for optimal performance. The position read optimizations are implemented in PositionReadFileInStream, which creates a Netty remote data reader that reads through a Netty channel.
So when Presto’s data reader performs a read via HdfsFileInputStream, it invokes readFully with a given position and length. PositionReadFileInStream then calls the NettyDataReader to construct the request and communicate with remote Alluxio workers in a loop (the readInternal function) to retrieve the full data required by Presto.
5. Summary
This post has explored how Presto, Hive, and Alluxio interact to execute SQL queries on data lakes. Here are the key takeaways:
- Hive Metastore provides table metadata
- Presto and Hive have similar SQL query lifecycles
- Alluxio JARs and filesystems plug into Presto
- Table locations dictate Presto’s filesystem choice
- Presto leverages Alluxio’s optimized position reads
Published at DZone with permission of Jiaming Mai. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments