Introduction to Snowflake for Beginners
Snowflake is evolving to provide transactional and analytical capabilities in a single platform. Learn more about its capabilities.
Join the DZone community and get the full member experience.
Join For FreeSnowflake's evolution over the last few years is simply amazing. It is currently a data platform with a great ecosystem both in terms of partners and a wide variety of components like snowgrid, snowpark, or streamlit, but in this article, we are not going to focus on its role as a modern cloud-based data warehouse. It revolutionizes the traditional concept of data warehousing; it offers a more agile and scalable platform that separates storage, computing, and services, allowing each component to scale independently. This means you can store unlimited data, ramp up or down your computing resources based on your querying needs, and only pay for what you use.
Currently, we can say that Snowflake is mainly an Online Analytical Processing (OLAP) type solution, but as we see further on, it is evolving to provide transactional and analytical capabilities in a single platform. Below is a high-level architecture diagram showing the layers that are part of Snowflake.
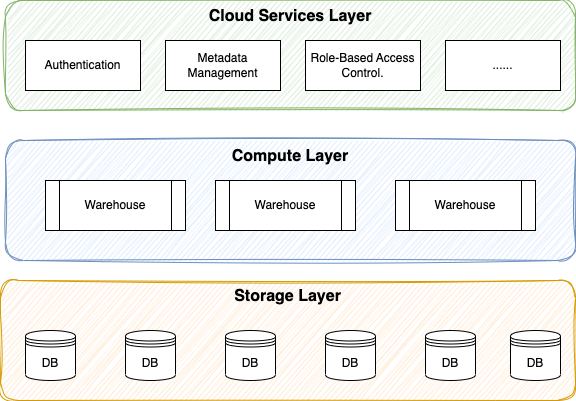
- Cloud Services Layer: It coordinates and handles tasks that are not specific to querying or storing data. It includes several tasks, such as authenticating user sessions, role-based access control, or ensuring transactional consistency.
- Compute Layer: This layer is where the actual data processing happens. It comprises one or multiple virtual warehouses, which are essentially clusters of compute resources. Each virtual warehouse can scale up or down independently and can be started or stopped to optimize costs.
- Storage Layer: This layer is responsible for the storage of structured and semi-structured data. It is stored in cloud storage in a columnar format.
Optimized for Analytical Queries
Snowflake is designed for big data analytics. It can handle complex queries on large datasets efficiently due to its columnar storage and massively parallel processing (MPP) architecture. Analytical queries typically work with a subset of columns and operations to aggregate, transform, and analyze vast volumes of data to provide insights, trends, or patterns.
These are some of the common operations used in analytical queries:
- Aggregations: Functions like
SUM(),AVG(),COUNT(), andMAX()are usually used to summarize data. - Range scans: Scan wide ranges of data (e.g.
WHERE sale_date BETWEEN '2022-01-01' AND '2022-12-31') - Group by: Grouping data using
GROUP BYclauses in combination with aggregation functions to provide summaries by some attribute. - Ordering and windows function: Use ordering (
ORDER BY) and window functions (e.g.,ROW_NUMBER(),LAG(),LEAD()) to calculate running totals, ranks, and other advanced analytics.
Let's see it in an example to help us understand it:

Columnar Storage, the Foundation of Performance
Columnar storage, as opposed to row-based storage, manages data using columns (product_id, name, sale_date, etc.) as logical units that are used to store the information in memory. Each logical unit always stores the same data type, which means that the adjacent data in memory all have the same type of data.
This strategy provides a number of performance benefits:
- Data access efficiency: Aggregation queries, like those calculating sums or averages, often require data from only a few columns rather than the entire row. In columnar storage, data is stored column by column. This means that when executing an aggregation on a specific column, the database system can read only the data for that column, skipping over all other unrelated columns. This selective reading can significantly reduce I/O operations and speed up query performance.
- Compression: Data within a column tends to be more homogeneous (i.e., of the same type and often with similar values) compared to data within a row. This homogeneity makes column data more amenable to compression techniques. For example, if a column storing a month of transaction dates mostly has the same few dates, you can represent those repeated dates once with a count instead of storing them repeatedly. Effective compression reduces storage costs and can also boost performance by reducing the amount of data read from storage.
- Better CPU cache utilization: Since columnar databases read contiguous memory blocks from a single column, they can better utilize CPU caches. The data loaded into the cache is more likely to be used in the subsequent operations, leading to fewer cache misses. On the other hand, in row-based systems, if only a few columns from a wide row are needed, much of the cached data might go unused.
- Eliminating irrelevant data quickly: Many columnar databases use metadata about blocks of columnar data, like min and max values. This metadata can quickly determine if a block contains relevant data or can be skipped entirely. For instance, if a query is filtering for pricing over 200, and the maximum value in a block is 110, the entire block can be ignored.
In the following diagram, we explain in a simple way how columnar storage could work to help you understand why it is efficient in analytical queries. But it does not mean that Snowflake implements this logic.

In this example, the values of each column can be stored in the same order: the first value of the product_id corresponds to the first value in the sales_Data and to the first in the amount; the second to the second to the second, and so on. Therefore when you filter by date, you can quickly get the offsets assigned for the start and end of the timestamp range and also give the offset of the corresponding values in the amount and perform the necessary calculations.
Unistore Unifying Analytical and Transactional Data
Snowflake is evolving its platform by applying a modern approach to provide transactional and analytical data operations together in a single platform. The new feature is called Unistore and enables running transactional by offering fast single-row operations.
Therefore, Snowflake joins a small group of cloud-based databases that offer this type of capability, such as SingleStore or MySQL Heatwave. This feature is still in private preview and has limited access, so we will have to verify the latency times. It should be considered that there are other features of transactional and relational databases, such as referential integrity that are not supported.
Row Storage, Transactional Performance
Typically, databases are oriented to work at the row level, and queries or operations use row-based storage or row-oriented storage. It is a method in which data is stored by rows. It is especially effective for transactional online transaction processing (OLTP) and workloads that frequently involve single-row queries or operations.

Some of the benefits of using this type of storage are listed below:
- Fewer columns in OLTP queries: Transactional queries, like those from web applications or operational systems, often involve a limited number of columns but require complete rows. In such scenarios, reading a full row from row-based storage is more efficient than assembling a row from multiple columns in columnar storage.
- Optimized for transactional workloads: OLTP systems often have a high number of small, frequent read and write operations. When updating or inserting a new row in row-based storage, the database writes the whole row at once. This contrasts with columnar systems where an insert or update might involve writing data across various column files.
- Locking and concurrency: Row-based databases are often optimized for row-level locking. This means that when a row is being updated, the database can lock just that specific row, allowing other operations to proceed concurrently on other rows. This level of granularity in locking is beneficial for high-concurrency transactional systems.
Snowflake Platform Layers
Cloud Services
The Cloud Services layer plays a crucial role in managing and optimizing the overall functionality of the data warehouse and acts as the "brain" that orchestrates processes and resources to deliver a seamless, secure, and scalable data analysis and management experience. It's responsible for handling a wide range of tasks, from authentication and infrastructure management to metadata maintenance and query optimization.
It is probably the most unknown layer, which means it is a user-friendly layer that goes unnoticed precisely because of its efficiency and simplicity. This layer offers several key features:
- Query processing: It receives SQL queries, parses them, and optimizes them for efficient execution, distributing the workload across its compute resources.
- Metadata management: It maintains metadata for the data stored that includes information about table structures, data types, and compression methods, as well as query history and performance metrics.
- Access control and security management: It handles user authentication, authorization, and role-based access control. It ensures that users can only access the data and perform the actions their roles permit.
- Transaction management: Handle the main features of transaction processing, including concurrency control and ensuring the ACID (Atomicity, Consistency, Isolation, Durability) properties of transactions. That, in conjunction with storage layer features (durability, consistency, or data versioning), is crucial for maintaining data integrity and consistency.
- Infrastructure management: It dynamically allocates and scales computational resources, the Virtual Warehouses, automatically scaling them up or down based on the workload.
- Data sharing and collaboration: It facilitates secure data sharing across different Snowflake accounts, sharing subsets of data without copying or moving the data, enabling real-time and seamless collaboration.
- Performance and usage monitoring: It provides tools and dashboards for monitoring the performance and usage of the Snowflake environment. Although, in my opinion, this is one of Snowflake's capabilities that can be improved.
- Integrations and API support: It provides support for various integrations and APIs, allowing users, applications, and tools to interact with the Snowflake platform. For example, it allows the management of all resources (compute, user management, monitoring, or security) following an as-code approach.
Compute Layer
This layer is composed of virtual warehouses that are essentially compute clusters and are responsible for executing SQL queries on the data stored in Snowflake. It supports creating multiple virtual warehouses to handle and distribute your workloads. This enables us to create dedicated and sized resources for each scenario or actor. For example, if you have different squads accessing data concurrently on top of the applications and BI tools, we can create and assign their own warehouse, ensuring that heavy querying by some of them doesn't affect another's performance.

- Isolation: Each cluster is a component isolated from the rest and, therefore, is not affected by the load state of other clusters.
- Independent scaling: It supports scale-up and scale-out independently for each cluster. If you need more performance for larger queries or more users, you can increase the size of your warehouse or add more nodes using multi-clustering capabilities.
- Independent elasticity: It supports automatic scale-out, although vertical scaling is not automated and, therefore requires us to perform manual or automatic actions.
- On-the-fly resizing: Scaling a virtual warehouse in Snowflake can be done on the fly without any downtime. This allows for elasticity, where you can adapt to varying workloads as needed.
- Multi-cluster warehouses: For even higher levels of concurrency, it enables scale-out automatically from one cluster to multiple compute clusters to accommodate many simultaneous users or queries.
Storage Layer
It is responsible for storing and managing data efficiently and contributes to having an effective and scalable platform. It offers several key features:
- Types of data: Snowflake supports structured and semi-structured data, including JSON, Avro, XML, Parquet formats, or Iceberg tables.
- Elastic and Scalable Storage: The storage layer automatically scales to accommodate data growth without manual intervention, so we do not need to worry about storage limits or provisioning additional storage space.
- Optimized data storage format: it stores data in an optimized columnar format or in row format in the case of Unistore tables, which can be indexed like traditional OLTP engines. Optimizing storage for each data use case.
- Data clustering and micro-partitions: Snowflake automatically organizes data into micro-partitions, which are internally optimized and compressed to improve query performance in terms of time and compute resources.
- Time travel and fail-safe features: It provides the capacity to access historical data up to a certain point in the past at table level. This allows us to revert to previous data states within a specified time window, providing data protection and ensuring data integrity or performing historical data analysis. The fail-safe feature offers additional protection by maintaining the data for a set period for disaster recovery.
- Data sharing: Snowflake enables secure and easy sharing of data between different Snowflake accounts. This feature allows organizations to share live, ready-to-query data with partners and customers without moving or copying data, ensuring data governance and security.
- Security and compliance: It provides several security features, including encryption of data at rest and in transit, role-based access control, and compliance with various industry standards and regulations.
- Cost-effective storage: We pay only for the storage they use, with Snowflake compressing and storing data in a cost-efficient manner.
Conclusions
In this series of articles, we will explore the various ways in which Snowflake can be used to address a wide range of data challenges. We will start with the basics of SQL and how to use it to query data in Snowflake. We will then move on to more advanced topics such as data modeling, query optimization, and machine learning.
Before embarking on any project, it is crucial to understand its underlying architecture, capabilities, and limitations. Failure to understand the nuances of products and platforms can lead to inefficiencies, performance bottlenecks, excessive costs, and potential security vulnerabilities.
This is precisely the purpose of this first article, to understand Snowflake's architecture and fundamental features.
Opinions expressed by DZone contributors are their own.
Comments