SYCL is a Khronos standard that brings support for fully heterogeneous data parallelism to C++. SYCL is a key solution to one aspect of a larger problem: How do we enable programming in the face of an explosion of hardware diversity that is coming?
Today, SYCL solves these problems in a way that lets us target hardware from many vendors, with many architectures, usefully. SYCL supports heterogeneous programming in C++. To get started, we really only need to understand queues and how to submit to queues.
Jump Into an SYCL Program
We look at SYCL Academy Code Exercise #8 and see that it sets up a queue, memory, and executes a kernel on a device. The net result of this code is to perform r[i] = a[i] + b[i]; for all elements of the arrays. See the example code below:
#include <CL/sycl.hpp>
// The heart of the SYCL Academy Code Exercise #8 is shown
// here with added comments
//set up a queue to a device that supports USM
auto usmQueue = sycl::queue{usm_selector{}, asyncHandler};
// add these lines (not on github) if you want to know
// precisely which accelerator our program is using
std::cout << "Device: " <<
usmQueue.get_device().get_info<sycl::info::device::name>() << std::endl;
// allocate three arrays that are on the device
auto devicePtrA = sycl::malloc_device<float>(dataSize, usmQueue);
auto devicePtrB = sycl::malloc_device<float>(dataSize, usmQueue);
auto devicePtrR = sycl::malloc_device<float>(dataSize, usmQueue);
// copy our local array into the device memory
usmQueue.memcpy(devicePtrA, a, sizeof(float) * dataSize).wait();
usmQueue.memcpy(devicePtrB, b, sizeof(float) * dataSize).wait();
// submit a kernel that adds two numbers and returns the sum
// the parallel_for asks that the kernel be applied to all array elements
usmQueue.parallel_for<vector_add>(
sycl::range{dataSize},
[=](sycl::id<1> idx) {
// these two lines run on the accelerator
auto globalId = idx[0];
devicePtrR[globalId] = devicePtrA[globalId] + devicePtrB[globalId];
}).wait();
// copy the device memory back
usmQueue.memcpy(r, devicePtrR, sizeof(float) * dataSize).wait();
// be kind and free up the memory we allocated
sycl::free(devicePtrA, usmQueue);
sycl::free(devicePtrB, usmQueue);
sycl::free(devicePtrR, usmQueue);
Code Line |
Description |
Line 1 |
Includes the SYCL definitions. For clarity in our example, we have not used a “using namespace sycl;” which you will commonly see in SYCL programs. |
Line 6 |
Establishes a queue connected to a device that supports USM. We’ll come back to explaining queues construction options after we walk through this code. |
Lines 10-11 |
Not in the original program. Add them in order to print out a brief explanation of which device was selected at runtime. For instance, on DevCloud, it printed: Device: Intel(R) UHD Graphics P630 [0x3e96] On other nodes, it may tell me that I was using an FPGA emulator, a CPU, or a different GPU — all without changing my code. |
Lines 14-16 |
Allocates memory on the device. If we had declared this memory shared with the CPU, we could eliminate lines 19-20 and 33. Doing it this way shows the control we can have when we want it. |
Lines 19-20 |
Copies our local array to device memory (allocated on lines 14-16). |
Lines 24-30 |
Submits work to the device. The parallel_for specifies that we want to apply the kernel a certain number (dataSize) of times. The lambda specifies the actual work to be done in each kernel. The kernel is written to work on its assigned item by using the unique index that is provided to it. |
Line 30 |
Causes the program to not proceed until the kernel has fully executed. Without this wait, the program would proceed as soon as the submission was made. We need to wait for results to be fully computed before we do the copy back on line 33. |
Line 33 |
Copies the results back. There are ways to write the program where this would be done for us, but this program is showing that we can also have complete control. |
Lines 34-36 |
Tidies things up by freeing the device memory we allocated in lines 14-16. |
In the full program (on GitHub), there is also code before and after to initialize the arrays and check the results.
What Is an SYCL Queue?
When an SYCL queue is constructed, it creates a connection to a single device. Our options for device selection include (a) accepting a default that the runtime picks for us, (b) asking for a certain class of devices (like a GPU, or a CPU, or an FPGA), or (c) taking full control, examine all devices available, and score them using any system we choose to program.
// use the default selector
queue q1{}; // default_selector
queue q2{default_selector()};
// use a CPU
queue q3{cpu_selector()};
// use a GPU
queue q4{gpu_selector()};
// use complex selection described in a function we write
// in the example – usm_selector{} is a custom selector
// which only grabs a device that supports USM
queue q5{my_custom_selector(a, b, c)};
Constructing an SYCL queue to connect us to a device can be done to whatever level of precision we desire.
What Is a Submit to a Queue?
Once we have constructed a queue, we can submit work to it. In our example, we used a parallel_for to request that the kernel be applied across all (dataSize) objects. The actual kernel was specified using a lambda function, which is a common way to specify kernels because it is very readable when it remains inline like this:
The order in which kernels are executed is left to the runtime provided it does not violate any known dependencies (e.g., data needs to be written before it is read). There is an option to ask for an in-order queue if that programming style suits our needs better.
What About Memory?
Memory is an interesting topic in more complex systems. Simple CPU-only systems generally have one memory accessible by the entire CPU. We say that all the memory is visible to all the CPU processing cores. Caches may be local to a given core, or collection of cores, on a CPU, but they will maintain a consistent view of memory. We refer to these as being “cache coherent.”
In a heterogeneous machine, the visibility of memory and the coherency of caches may be more interesting. GPUs generally have a local memory that is not directly usable by the CPU, and the GPU may or may not be able to access some of the CPU memory. As we add more GPUs or other accelerators, the situation can become even more complex.
That is why SYCL supports rich methods to utilize memory configurations of all kinds. C++ programmers will feel completely at home with Unified Shared Memory (USM), which we used in the example previously discussed. USM allows for memory to be accessed by the CPU and accelerators just like normal memory. In the example, we added a twist of having the USM memory local to the device — to illustrate our ability to control more precisely when we wish to do so. You can read more about that in other tutorials or the book.
Since not all devices can support USM, or there may be special memories that are local to devices, SYCL also supports buffer-based models. It is good to know that SYCL is versatile in this respect, and all the tutorials and the SYCL book cover these options in detail.

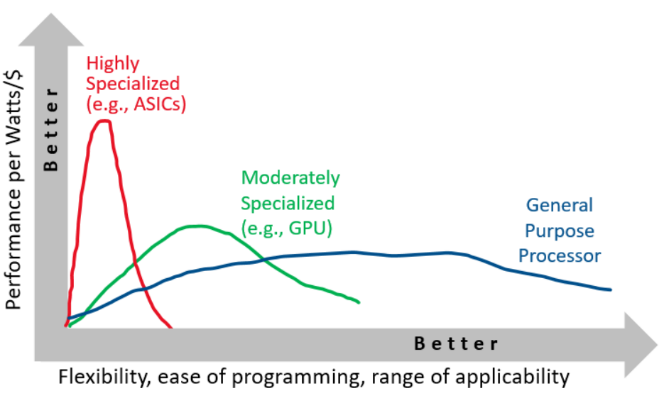 Heterogeneous computing has become the norm because specialized devices can offer better performance per watt, but it is more challenging to use because the benefits are more tailored and less general.
Heterogeneous computing has become the norm because specialized devices can offer better performance per watt, but it is more challenging to use because the benefits are more tailored and less general.
{{ parent.title || parent.header.title}}
{{ parent.tldr }}
{{ parent.linkDescription }}
{{ parent.urlSource.name }}