WireMock: The Ridiculously Easy Way (For Spring Microservices)
Creating WireMock stubs requires extra effort; @GenerateWireMockStub for Spring REST controllers makes the creation of WireMock stubs for tests safe and effortless.
Join the DZone community and get the full member experience.
Join For FreeUsing WireMock for integration testing of Spring-based (micro)services can be hugely valuable. However, usually, it requires significant effort to write and maintain the stubs needed for WireMock to take a real service’s place in tests.
What if generating WireMock stubs was as easy as adding @GenerateWireMockStub to your controller? Like this:
@GenerateWireMockStub
@RestController
class MyController {
@GetMapping("/resource")
fun getData() = MyServerResponse(id = "someId", message = "message")
}What if that meant that you then just instantiate your producer’s controller stub in consumer-side tests…
val myControllerStub = MyControllerStub()Stub the response…
myControllerStub.getData(MyServerResponse("id", "message"))And verify calls to it with no extra effort?
myControllerStub.verifyGetData()Surely, it couldn’t be that easy?!
Before I explain the framework that does this, let’s first look at the various approaches to creating WireMock stubs.
The Standard Approach
While working on a number of projects, I observed that the writing of WireMock stubs most commonly happens on the consumer side. What I mean by this is that the project that consumes the API contains the stub setup code required to run tests.
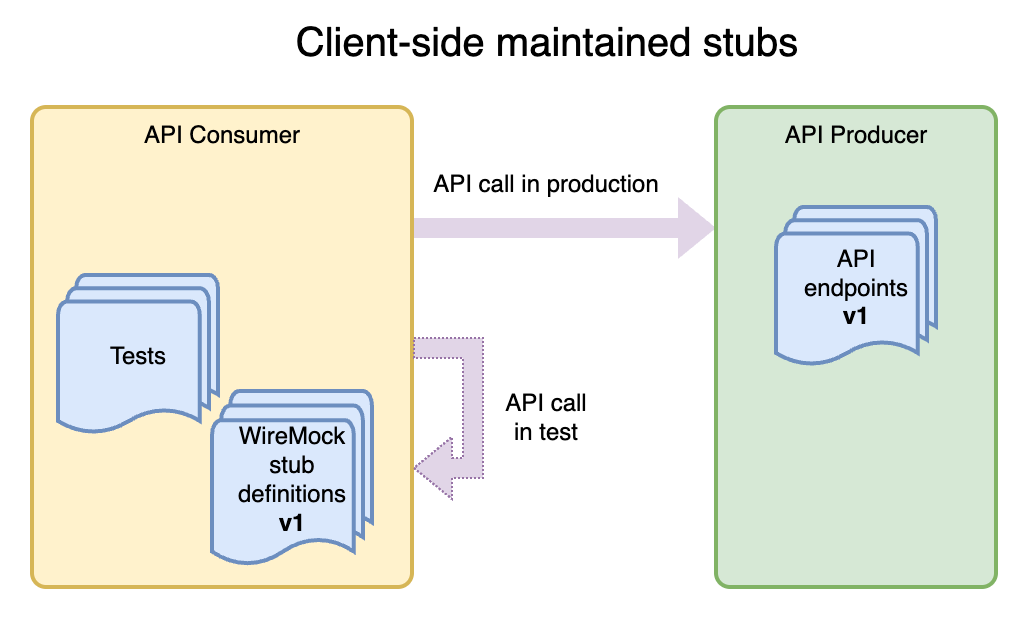
The benefit of it is that it's easy to implement. There is nothing else the consuming project needs to do. Just import the stubs into the WireMock server in tests, and the job is done.
However, there are also some significant downsides to this approach.
For example, what if the API changes? What if the resource mapping changes? In most cases, the tests for the service will still pass, and the project may get deployed only to fail to actually use the API — hopefully during the build’s automated integration or end-to-end tests. Limited visibility of the API can lead to incomplete stub definitions as well.

Another downside of this approach is the duplicated maintenance effort — in the worst-case scenario. Each client ends up updating the same stub definitions.
Leakage of the API-specific information, in particular, sensitive information from the producer to the consumer, leads to the consumers being aware of the API characteristics they shouldn’t be. For example, the endpoint mappings or, sometimes even worse — API security keys.
Maintaining stubs on the client side can also lead to increased test setup complexity.
The Less Common Approach
A more sophisticated approach that addresses some of the above disadvantages is to make the producer of the API responsible for providing the stubs.
So, how does it work when the stubs live on the producer side?
In a poly-repo environment, where each microservice has its own repository, this means the producer generates an artifact containing the stubs and publishes it to a common repository (e.g., Nexus) so that the clients can import it and use it. In a mono-repo, the dependencies on the stubs may not require the artifacts to be published in this way, but this will depend on how your project is set up.

- The stub source code is written manually and subsequently published to a repository as a JAR file
- The client imports the JAR as a dependency and downloads it from the repository
- Depending on what is in the Jar, the test loads the stub directly to WireMock or instantiates the dynamic stub (see next section for details) and uses it to set up WireMock stubs and verify the calls
This approach improves the accuracy of the stubs and removes the duplicated effort problem since there is only one set of stubs maintained. There is no issue with visibility either since the stubs are written while having full access to the API definition, which ensures better understanding. The consistency is ensured by the consumers always loading the latest version of the published stubs every time the tests are executed.
However, preparing stubs manually on the producer's side can also have its own shortcomings. It tends to be quite laborious and time-consuming. As any handwritten code intended to be used by 3rd parties, it should be tested, which adds even more effort to the development and maintenance.
Another problem that may occur is a consistency issue. Different developers may write the stubs in different ways, which may mean different ways of using the stubs. This slows development down when developers maintaining different services need to first learn how the stubs have been written, in the worst-case scenario, uniquely for each service.
Also, when writing stubs on the consumer's side, all that is required to prepare are stubs for the specific parts of the API that the consumer actually uses. But providing them on the producer's side means preparing all of them for the entire API as soon as the API is ready, which is great for the client but not so great for the provider.
Overall, writing stubs on the provider side has several advantages over the client-side approach. For example, if the stub-publishing and API-testing are well integrated into the CI pipeline, it can serve as a simpler version of Consumer Driven Contracts, but it is also important to consider the possible implications like the requirement for the producer to keep the stubs in sync with the API.
Dynamic Stubbing
Some developers may define stubs statically in the form of JSON. This is additional maintenance. Alternatively, you can create helper classes that introduce a layer of abstraction — an interface that determines what stubbing is possible. Usually, they are written in one of the higher-level languages like Java/Kotlin.
Such stub helpers enable the clients to set up stubs within the constraints set out by the author. Usually, it means using various values of various types. Hence I call them dynamic stubs for short.
An example of such a dynamic stub could be a function with a signature along the lines of:
fun get(url: String, response: String }One could expect that such a method could be called like this:
get(url = "/someResource", response = "{ \"key\" = \"value\" }")And a potential implementation using the WireMock Java library:
fun get(url: String, response: String) {
stubFor(get(urlPathEqualTo(url))
.willReturn(aResponse().withBody(response)))
}Such dynamic stubs provide a foundation for the solution described below.
Auto-Generating Dynamic WireMock Stubs
I have been working predominantly in the Java/Kotlin Spring environment, which relies on the SpringMVC library to support HTTP endpoints. The newer versions of the library provide the @RestController annotation to mark classes as REST endpoint providers. It's these endpoints that I tend to stub most often using the above-described dynamic approach.
I came to the realization that the dynamic stubs should provide only as much functionality as set out by the definition of the endpoints. For example, if a controller defines a GET endpoint with a query parameter and a resource name, the code enabling you to dynamically stub the endpoint should only allow the client to set the value of the parameter, the HTTP status code, and the body of the response. There is no point in stubbing a POST method on that endpoint if the API doesn't provide it.
With that in mind, I believed there was an opportunity to automate the generation of the dynamic stubs by analyzing the definitions of the endpoints described in the controllers.
Obviously, nothing is ever easy.
A proof of concept showed how little I knew about the build tool that I have been using for years (Gradle), the SpringMVC library, and Java annotation processing.
But nevertheless, in spite of the steep learning curve, I managed to achieve the following:
- parse the smallest meaningful subset of the relevant annotations (e.g., a single basic resource)
- design and build a data model of the dynamic stubs
- generate the source code of the dynamic stubs (in Java)
- and make Gradle build an artifact containing only the generated code and publish it
(I also tested the published artifact by importing it into another project)
In the end, here is what was achieved:

- The annotation processor iterates through all relevant annotations and generates the dynamic stub source code.
- Gradle compiles and packages the generated source into a JAR file and publishes it to an artifact repository (e.g., Nexus)
- The client imports the JAR as a dependency and downloads it from the repository
- The test instantiates the generated stubs and uses them to set up WireMock stubs and verify the calls made to WireMock
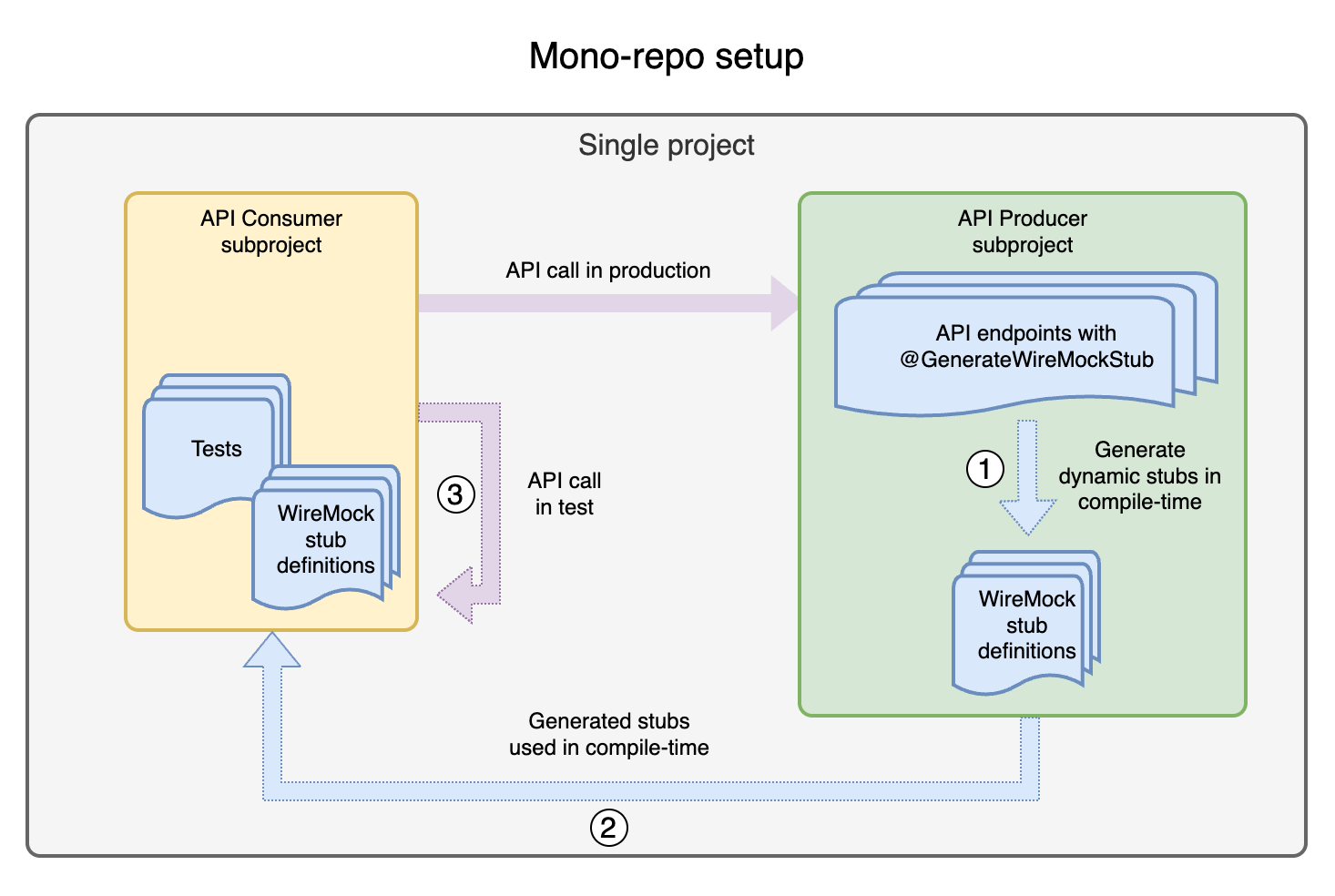
With a mono-repo, the situation is slightly simpler since there is no need to package the generated code and upload it to a repository. The compiled stubs become available to the depending subprojects immediately.
These end-to-end scenarios proved that it could work.
The Final Product
I developed a library with a custom annotation @GenerateWireMockStub that can be applied to a class annotated with @RestController. The annotation processor included in the library generates the Java code for dynamic stub creation in tests. The stubs can then be published to a repository or, in the case of a mono-repo, used directly by the project(s).
For example, by adding the following dependencies (Kotlin project):
kapt 'io.github.lsd-consulting:spring-wiremock-stub-generator:2.0.3'
compileOnly 'io.github.lsd-consulting:spring-wiremock-stub-generator:2.0.3'
compileOnly 'com.github.tomakehurst:wiremock:2.27.2'and annotating a controller having a basic GET mapping with @GenerateWireMockStub:
@GenerateWireMockStub
@RestController
class MyController {
@GetMapping("/resource")
fun getData() = MyServerResponse(id = "someId", message = "message")
}will result in generating a stub class with the following methods:
public class MyControllerStub {
public void getData(MyServerResponse response)
...
}
public void getData(int httpStatus, String errorResponse) {
...
}
public void verifyGetData() {
...
}
public void verifyGetData(final int times) {
...
}
public void verifyGetDataNoInteraction() {
...
}
}The first two methods set up stubs in WireMock, whereas the other methods verify the calls depending on the expected number of calls — either once or the given number of times, or no interaction at all.
That stub class can be used in a test like this:
//Create the stub for the producer’s controller
val myControllerStub = MyControllerStub()
//Stub the controller method with the response
myControllerStub.getData(MyServerResponse("id", "message"))
callConsumerThatTriggersCallToProducer()
myControllerStub.verifyGetData()The framework now supports most HTTP methods, with a variety of ways to verify interactions.
@GenerateWireMockStub makes maintaining these dynamic stubs effortless. It increases accuracy and consistency, making maintenance easier and enabling your build to easily catch breaking changes to APIs before your code hits production.
More details can be found on the project’s website.
A full example of how the library can be used in a multi-project setup and in a mono-repo:
Limitations
The library’s limitations mostly come from the WireMock limitations. More specifically, multi-value and optional request parameters are not quite supported by WireMock. The library uses some workarounds to handle those. For more details, please check out the project’s README.
Note
The client must have access to the API classes used by the controller. Usually, it is achieved by exposing them in separate API modules that are published for consumers to use.
Acknowledgments
I would like to express my sincere gratitude to the reviewers who provided invaluable feedback and suggestions to improve the quality of this article and the library. Their input was critical in ensuring the article’s quality.
A special thank you to Antony Marcano for his feedback and repeated reviews, and direct contributions to this article. This was crucial in ensuring that the article provides clear and concise documentation for the spring-wiremock-stub-generator library.
I would like to extend my heartfelt thanks to Nick McDowall and Nauman Leghari for their time, effort, and expertise in reviewing the article and providing insightful feedback to improve its documentation and readability.
Finally, I would also like to thank Ollie Kennedy for his careful review of the initial pull request and his suggestions for improving the codebase.
Opinions expressed by DZone contributors are their own.
Comments