What's Wrong With Small Objects in Java?
There are reasons you should not use numerous small objects in Java.
Join the DZone community and get the full member experience.
Join For FreeData encapsulation is one of the fundamental properties of object-oriented programming. An object is the most natural representation of several pieces of data that logically "go together." A class and, thus, its instances can contain as many or as few data fields as needed. If a class has a large number of data fields, it may be difficult to read, maintain, etc. But did you ever consider possible implications of writing a Java class with very few data fields and then creating a large number of its instances? If not, read on.
In Java, objects in memory don't come for free. That is, in addition to the "payload" (the data fields that you declare in the respective class and its superclasses), every object uses some extra memory. There are several reasons for that, and it turns out that the extra memory amount is not small. Here is a diagram illustrating the object structure in the HotSpot JVM that comes with the Oracle JDK (this object has data fields Object foo; int bar and so on):
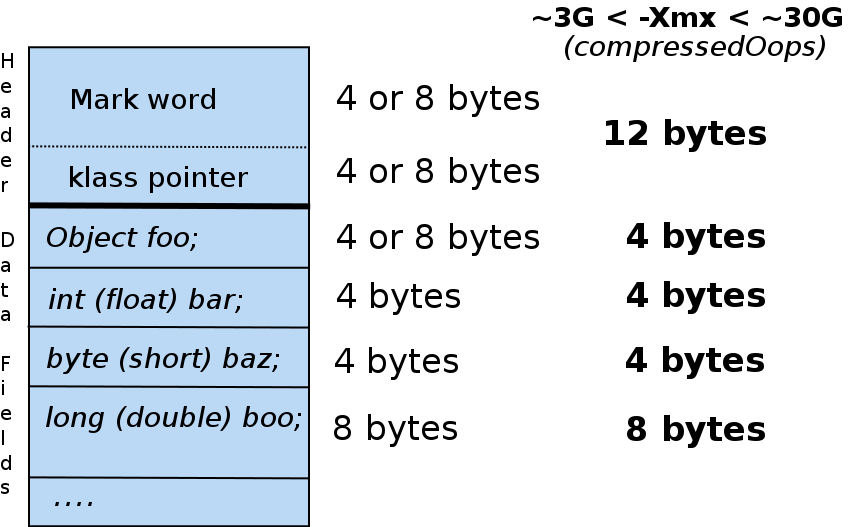
As you can see, each object has a header, which contains a pointer to the object's class plus some extra bytes called mark word. The class pointer is needed so that (a) virtual methods can be dispatched at runtime and (b) the garbage collector, when scanning the heap, could determine the location of pointers to other objects within the given object. The mark word is used by the garbage collector to store some bookkeeping information and also by the synchronization mechanism (recall that in Java any object can be used as an argument in the synchronized block). The size of each of the header parts can vary between 4 and 8 bytes depending on the maximum heap size. What is worth remembering is that in the most common case (-Xmx below 32GB), object header size is 12 bytes, and with bigger -Xmx it's 16 bytes.
However, that's not all. Another source of per-object overhead is object alignment (padding), which I described, among other things, in my previous article. In short, it means that in absence of special JVM flags, each object in memory starts at an address proportional to 8, as illustrated below:

Consequently, every object has an effective size proportional to 8 bytes. As a result, in the worst case, an object with just the minimum 4-byte payload (such as an instance of java.lang.Integer) takes 16 bytes, and an object with 8-byte payload (java.lang.Long) takes 24 bytes! This is a 3.4x memory overhead, and it's very real. In fact, it's not uncommon to see unoptimized Java applications where 20..40 percent of memory is wasted due to this per-object overhead. Furthermore, small objects that are numerous and live for long enough don't just waste memory: they put pressure on the garbage collector since it has to scan and move around many more objects on each iteration.
How to address this problem? Unfortunately, there is no silver bullet here. You will need to understand which objects cause significant overhead and then look for a specific solution to each problem. Below, we outline several most common situations and possible ways to address them.
Boxed Numbers
The article mentioned above is devoted to this subject. When objects representing numbers take up a lot of memory, the general solution is simply not to use them. There are not many good reasons why a data field in some class should be, for example, an Integer instead of a plain int. One legitimate case is when we need to be able to signal that the field is "uninitialized" or "undefined" using null. However, if instances of Integer start to occupy a lot of memory, almost any other way to implement this functionality would be more economical. You can use a separate boolean flag or a bit vector when there are several such fields, etc.
Another common reason for using boxed numbers is when you need data structures such as hashmaps or lists containing numbers. However, instead of, for example, a java.util.HashMap<Integer, String>, you can use a specialized third-party Int2ObjectHashMap<String> and so on. See the article above for more details.
Wrappers
An instance of a wrapper class encapsulates or "wraps" another object. This is usually done to provide access to the data contained in the latter with some restrictions or side effects (e.g. log every modification to the object's contents). An example wrapper class is java.util.Collections.UnmodifiableList, which is a non-public class returned by the Collections.unmodifiableList(List) method. Most wrapper classes have very few or no fields in addition to the one that points to the wrapped object, and in many cases, applications use just a few of the wrapper's methods. Thus, if in your app instances of some wrapper class take a big share of memory, it may be worth changing the code to reference wrapped objects directly and provide the wrapper functionality in a different way.
Collection Implementation Classes
One of my older articles explains the internal structure of several popular JDK collection classes. In particular, the internals of java.util.HashMap implementations are depicted (note that this also pertains to java.util.HashSet and java.util.LinkedHashMap that encapsulate and extend HashMap, respectively). In all these collections, adding a key-value pair results in the allocation of an instance of java.util.HashMap$Node class (called $Entry in JDK 7 and earlier). A Node object serves two purposes: it stores the hashcode of the key to speed up key lookup, and it supports collision chains in the form of a linked list (or binary search tree starting from JDK 8). This, in general, improves the time of get() and put() operations. Unfortunately, these objects, taking 32 bytes each, may also cause a lot of waste when the application relies on hash maps or hash sets heavily. To eliminate this kind of waste, consider switching to an alternative open hashmap implementation, that doesn't use internal "node" objects, for example, Object2ObjectOpenHashMap from the fastutil library.
A Class Only Referenced From One Other Class
Consider the following example:
class Foo {
Bar bar;
...
}
class Bar { // 8 bytes payload, 16 bytes overhead per object
int x, y;
...
}If class Bar is only referenced by class Foo, and instances of Bar use up a lot of memory. It may be worth considering "lifting" the data fields and methods of Bar into Foo. Of course, as a result, the code of Foo will become longer and possibly less readable/maintainable, but memory savings may justify it.
Objects That Can Be Represented as a Plain-Number Table
This is especially relevant for small fixed-size arrays, but it can also be applied to classes that have only or mostly numeric data fields. It works best when, at runtime, these objects are only added but never deleted. Consider the following code:
class Event {
byte[] encodedData = new byte[8]; // Overhead per array: 12b header, 4b array size
Message msg;
...
}
class Message { // Overhead per instance: 12b header, 4b padding
int time, value;
...
}To avoid keeping one byte[] array and one Message instance per Event object, we can convert this into something like:
class Event {
int eventIdx; // Index in table below where our data is stored
EventTable table;
byte[] getEncodedData() {
byte[] result = new byte[8];
System.arraycopy(table.encodedData, eventIdx*8, result, 0, 8);
return result;
}
Message getMessage() {
int[] data = table.eventData;
return new Message(data[eventIdx*2], data[eventIdx*2 + 1]);
}
}
class EventTable {
byte[] encodedData = new byte[...];
int[] eventData = new int[...];
...
}As you can see, now, instead of storing two small objects per each Event, we store just the reference to the table with all the data and an event index and create temporary Message and byte[] objects on demand. If the application keeps tens of millions of events in memory, this change would result in huge memory savings. In addition, you can expect a big improvement in GC performance, since the GC time is proportional to the number of objects to scan and move around.
Detecting Small Objects that Waste Memory
How can you find out whether your app wastes memory due to small objects? From experience, the best way is to generate a heap dump of the app and then use a tool to analyze it.
A heap dump is essentially a full snapshot of the running JVM's heap. It can be either taken at an arbitrary moment by invoking the jmap utility, or the JVM can be configured to produce it automatically if it fails with OutOfMemoryError. If you Google "JVM heap dump," you will immediately see a bunch of relevant articles on this subject.
A heap dump is a binary file of about the size of your JVM's heap, so it can only be read and analyzed with special tools. There is a number of such tools available, both open source and commercial. The most popular open-source tool is Eclipse MAT; there is also VisualVM and some less-powerful, lesser-known tools. The commercial tools include the general-purpose Java profilers: JProfiler and YourKit, as well as one tool built specifically for heap dump analysis called JXRay.
Unlike most other tools, JXRay analyzes a heap dump right away for a large number of common problems, such as duplicate strings and other objects, suboptimal data structures, and "fixed per-object overhead," which is what we discussed above. The tool generates a report with all the collected information in the HTML format. The advantage of this approach is that you can view the results of analysis anywhere, at any time later, and share it with others easily. It also means that you can run the tool on any machine, including big and powerful yet "headless" machines in a data center.
Once you get a report from JXRay, open it in your favorite browser and expand the relevant section. You may see something like this:
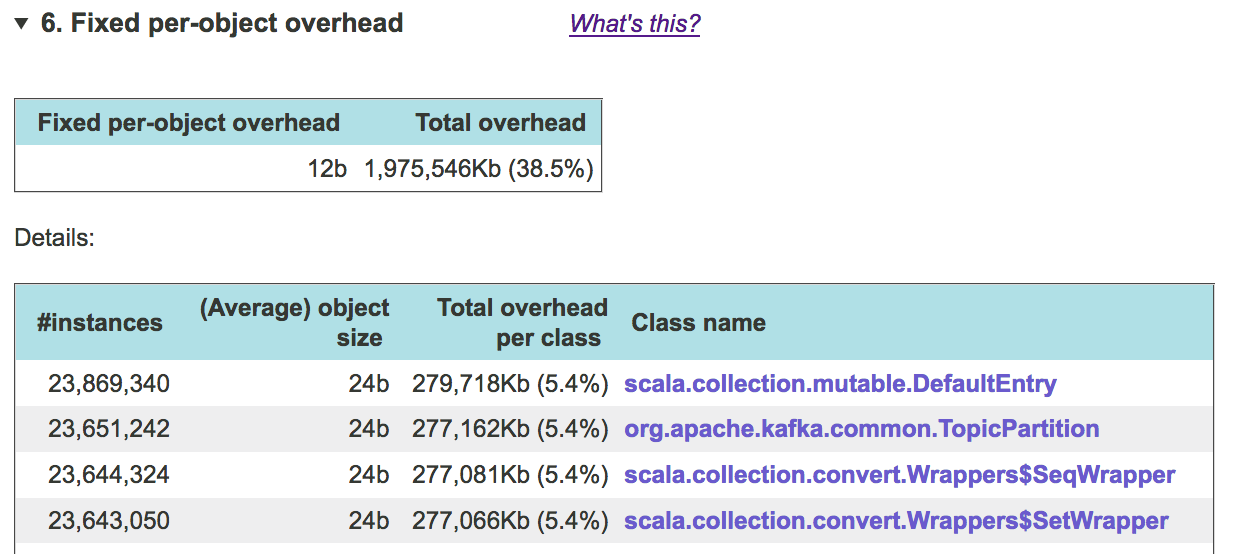
So, in this dump, a whopping 38.5 percent of the used heap is wasted due to object headers and alignment. The table above lists all classes whose instances contribute significantly to this overhead. To see where these objects come from (what objects reference them, all the way up to GC roots), go to the "where memory goes, by class" section of the report, expand it, and click on the relevant line in the table. Here is an example for one of the above classes, TopicPartition :
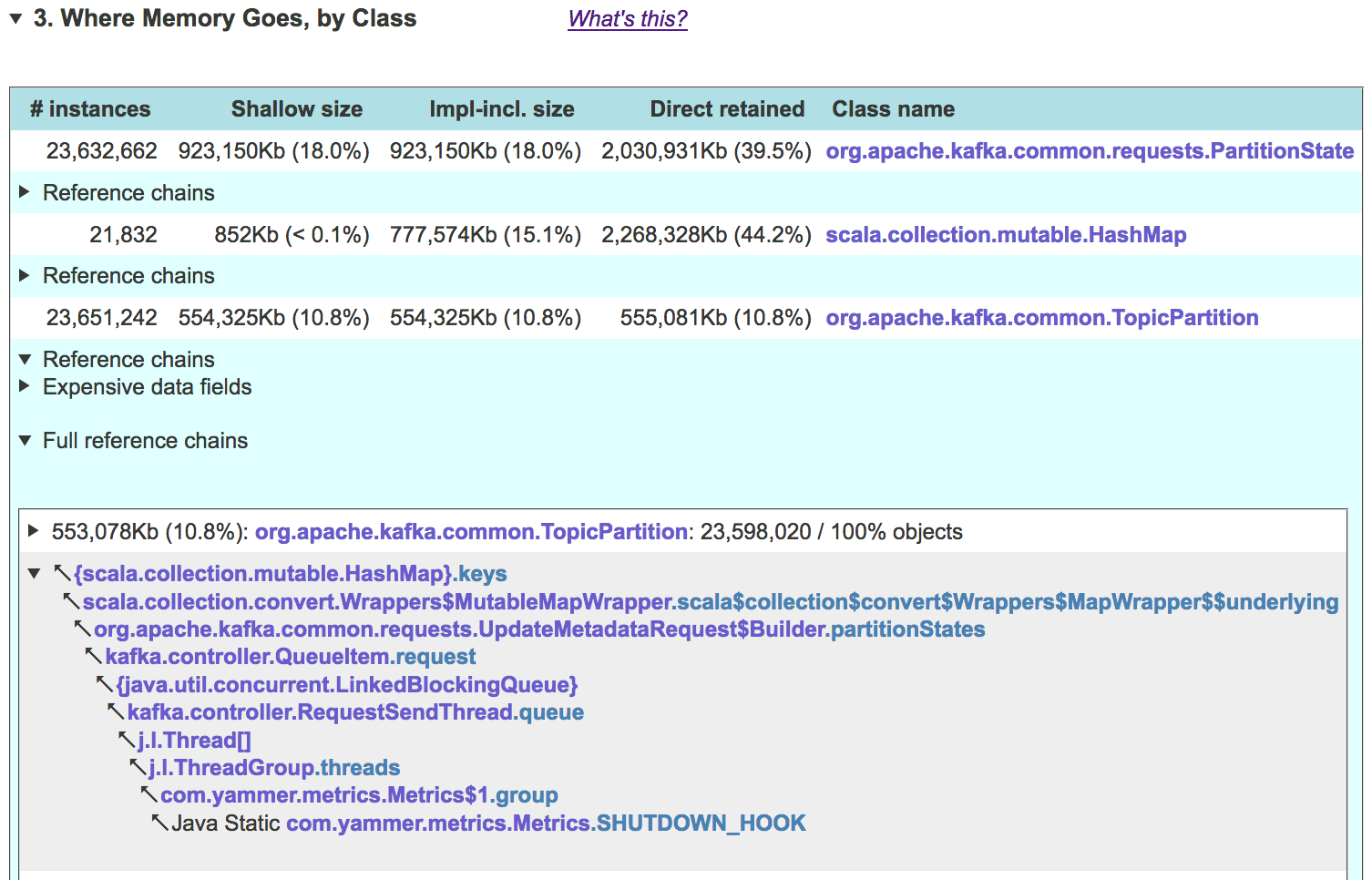
From here, we can get a good idea of what data structures manage the problematic objects.
To summarize, numerous small objects can become a burden in a Java app because their fixed per-object overhead, imposed by the JVM itself, is comparable to their "payload." As a result, a lot of memory may be wasted, and high GC pressure can be observed. The best way to measure the impact of such objects is to obtain a heap dump and use a tool like JXRay to analyze it. If you find that small objects are a problem, it may or may not be easy to get rid of them. One category of small objects that's relatively easy to eliminate is Java boxed numbers. Other kinds of small objects require case-by-case consideration, and potentially some non-trivial changes to your code.
Opinions expressed by DZone contributors are their own.
Comments