How OpenAI’s Downtime Incident Teaches Us to Build More Resilient Systems
OpenAI's downtime incident reveals critical lessons in building resilient systems, improving testing, and preventing future failures in distributed environments.
Join the DZone community and get the full member experience.
Join For FreeOn December 11, 2024, OpenAI services experienced significant downtime due to an issue stemming from a new telemetry service deployment. This incident impacted API, ChatGPT, and Sora services, resulting in service disruptions that lasted for several hours. As a company that aims to provide accurate and efficient AI solutions, OpenAI has shared a detailed post-mortem report to transparently discuss what went wrong and how they plan to prevent similar occurrences in the future.
In this article, I will describe the technical aspects of the incident, break down the root causes, and explore key lessons that developers and organizations managing distributed systems can take away from this event.
The Incident Timeline
Here’s a snapshot of how the events unfolded on December 11, 2024:
| Time (PST) | Event |
|---|---|
| 3:16 PM |
Minor customer impact began; service degradation observed |
| 3:27 PM | Engineers began redirecting traffic from impacted clusters |
| 3:40 PM | Maximum customer impact recorded; major outages across all services |
| 4:36 PM | First Kubernetes cluster began recovering |
| 5:36 PM | Substantial recovery for API services began |
| 5:45 PM | Substantial recovery for ChatGPT observed |
| 7:38 PM | All services fully recovered across all clusters |
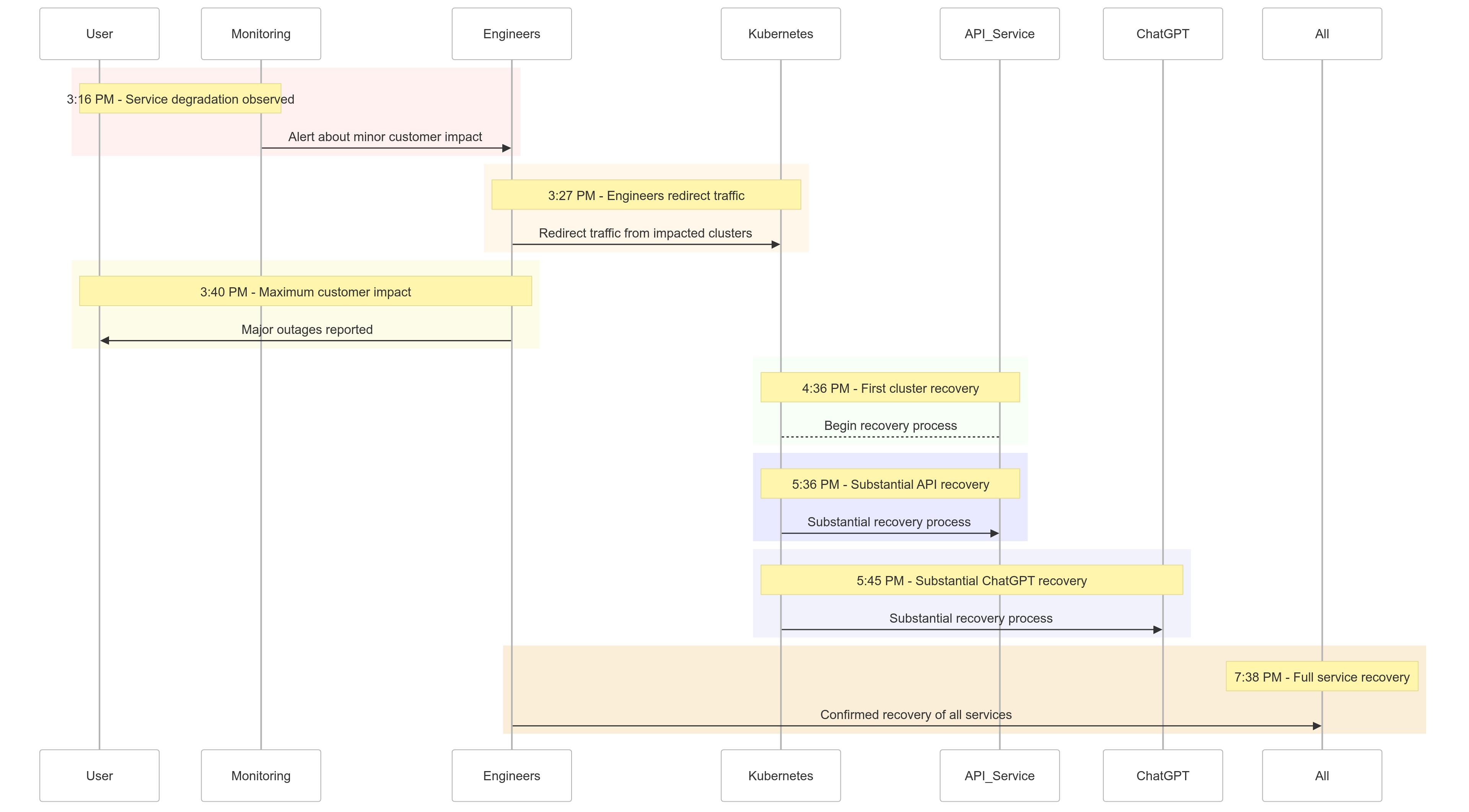
Figure 1: OpenAI Incident Timeline - Service Degradation to Full Recovery.
Root Cause Analysis
The root of the incident lay in a new telemetry service deployed at 3:12 PM PST to improve the observability of Kubernetes control planes. This service inadvertently overwhelmed Kubernetes API servers across multiple clusters, leading to cascading failures.
Breaking It Down
Telemetry Service Deployment
The telemetry service was designed to collect detailed Kubernetes control plane metrics, but its configuration unintentionally triggered resource-intensive Kubernetes API operations across thousands of nodes simultaneously.
Overloaded Control Plane
The Kubernetes control plane, responsible for cluster administration, became overwhelmed. While the data plane (handling user requests) remained partially functional, it depended on the control plane for DNS resolution. As cached DNS records expired, services relying on real-time DNS resolution began failing.
Insufficient Testing
The deployment was tested in a staging environment, but the staging clusters did not mirror the scale of production clusters. As a result, the API server load issue went undetected during testing.
How the Issue Was Mitigated
When the incident began, OpenAI engineers quickly identified the root cause but faced challenges implementing a fix because the overloaded Kubernetes control plane prevented access to the API servers. A multi-pronged approach was adopted:
- Scaling Down Cluster Size: Reducing the number of nodes in each cluster lowered the API server load.
- Blocking Network Access to Kubernetes Admin APIs: Prevented additional API requests, allowing servers to recover.
- Scaling Up Kubernetes API Servers: Provisioning additional resources helped clear pending requests.
These measures enabled engineers to regain access to the control planes and remove the problematic telemetry service, restoring service functionality.
Lessons Learned
This incident highlights the criticality of robust testing, monitoring, and fail-safe mechanisms in distributed systems. Here’s what OpenAI learned (and implemented) from the outage:
1. Robust Phased Rollouts
All infrastructure changes will now follow phased rollouts with continuous monitoring. This ensures issues are detected early and mitigated before scaling to the entire fleet.
2. Fault Injection Testing
By simulating failures (e.g., disabling the control plane or rolling out bad changes), OpenAI will verify that their systems can recover automatically and detect issues before impacting customers.
3. Emergency Control Plane Access
A “break-glass” mechanism will ensure engineers can access Kubernetes API servers even under heavy load.
4. Decoupling Control and Data Planes
To reduce dependencies, OpenAI will decouple the Kubernetes data plane (handling workloads) from the control plane (responsible for orchestration), ensuring that critical services can continue running even during control plane outages.
5. Faster Recovery Mechanisms
New caching and rate-limiting strategies will improve cluster startup times, ensuring quicker recovery during failures.
Sample Code: Phased Rollout Example
Here’s an example of implementing a phased rollout for Kubernetes using Helm and Prometheus for observability.
Helm deployment with phased rollouts:
# Deploy the telemetry service to 10% of clusters
helm upgrade --install telemetry-service ./telemetry-chart \
--set replicaCount=10 \
--set deploymentStrategy=phased-rolloutPrometheus query for monitoring API server load:
# PromQL Query to monitor Kubernetes API server load
sum(rate(apiserver_request_duration_seconds_sum[1m])) by (cluster) /
sum(rate(apiserver_request_duration_seconds_count[1m])) by (cluster)This query helps track response times for API server requests, ensuring early detection of load spikes.
Fault Injection Example
Using chaos-mesh, OpenAI could simulate outages in the Kubernetes control plane.
# Inject fault into Kubernetes API server to simulate downtime
kubectl create -f api-server-fault.yamlapi-server-fault.yaml:
apiVersion: chaos-mesh.org/v1alpha1
kind: PodChaos
metadata:
name: api-server-fault
spec:
action: pod-kill
mode: one
selector:
namespaces:
- kube-system
labelSelectors:
app: kube-apiserverThis configuration intentionally kills an API server pod to verify system resilience.
What This Means for You
This incident underscores the importance of designing resilient systems and adopting rigorous testing methodologies. Whether you manage distributed systems at scale or are implementing Kubernetes for your workloads, here are some takeaways:
- Simulate Failures Regularly: Use chaos engineering tools like Chaos Mesh to test system robustness under real-world conditions.
- Monitor at Multiple Levels: Ensure your observability stack tracks both service-level metrics and cluster health metrics.
- Decouple Critical Dependencies: Reduce reliance on single points of failure, such as DNS-based service discovery.
Conclusion
While no system is immune to failures, incidents like this remind us of the value of transparency, swift remediation, and continuous learning. OpenAI’s proactive approach to sharing this post-mortem provides a blueprint for other organizations to improve their operational practices and reliability.
By prioritizing robust phased rollouts, fault injection testing, and resilient system design, OpenAI is setting a strong example of how to handle and learn from large-scale outages.
For teams that manage distributed systems, this incident is a great case study of how to approach risk management and minimize downtime for core business processes.
Let’s use this as an opportunity to build better, more resilient systems together.
Opinions expressed by DZone contributors are their own.
Comments