What Is, Why We Need, and How to Do Data Synchronization
In this article, take a look at data synchronization and see what it is, why you need it, and how to do it.
Join the DZone community and get the full member experience.
Join For FreePresent-day organizations have complex business requirements. The data can be in several locations. System migrations happen frequently due to technology changes. Integration happens with several platforms that are nowadays referred to as hybrid platforms. This article briefly describes the deployment types, why they have been implemented in such a way, their limitations, and how to overcome them using data synchronization with the help of WSO2 Streaming Integrator.
What Is Data Synchronization?
In simple terms, data synchronization is about synchronizing all data instances used by devices or applications by maintaining consistency and accuracy. Any change that happens to a particular data instance is reflected in the other data instances in near real time. In addition, data synchronization results in cost-efficiency, high performance, data security, data consistency, and accuracy for an organization.
Why Do We Need Data Synchronization?
Hybrid Integration: Data can be on-premise as well as on a wide variety of cloud services such as AWS, Microsoft Azure and Google Cloud platforms. This is done due to the need to offload several operations to the cloud services. The process may involve enriching, filtering, transforming, and aggregating data before transferring it to the cloud services and vice versa, without interrupting or slowing down the business process. All this needs to take place in real-time while maintaining the accuracy and consistency of the data.
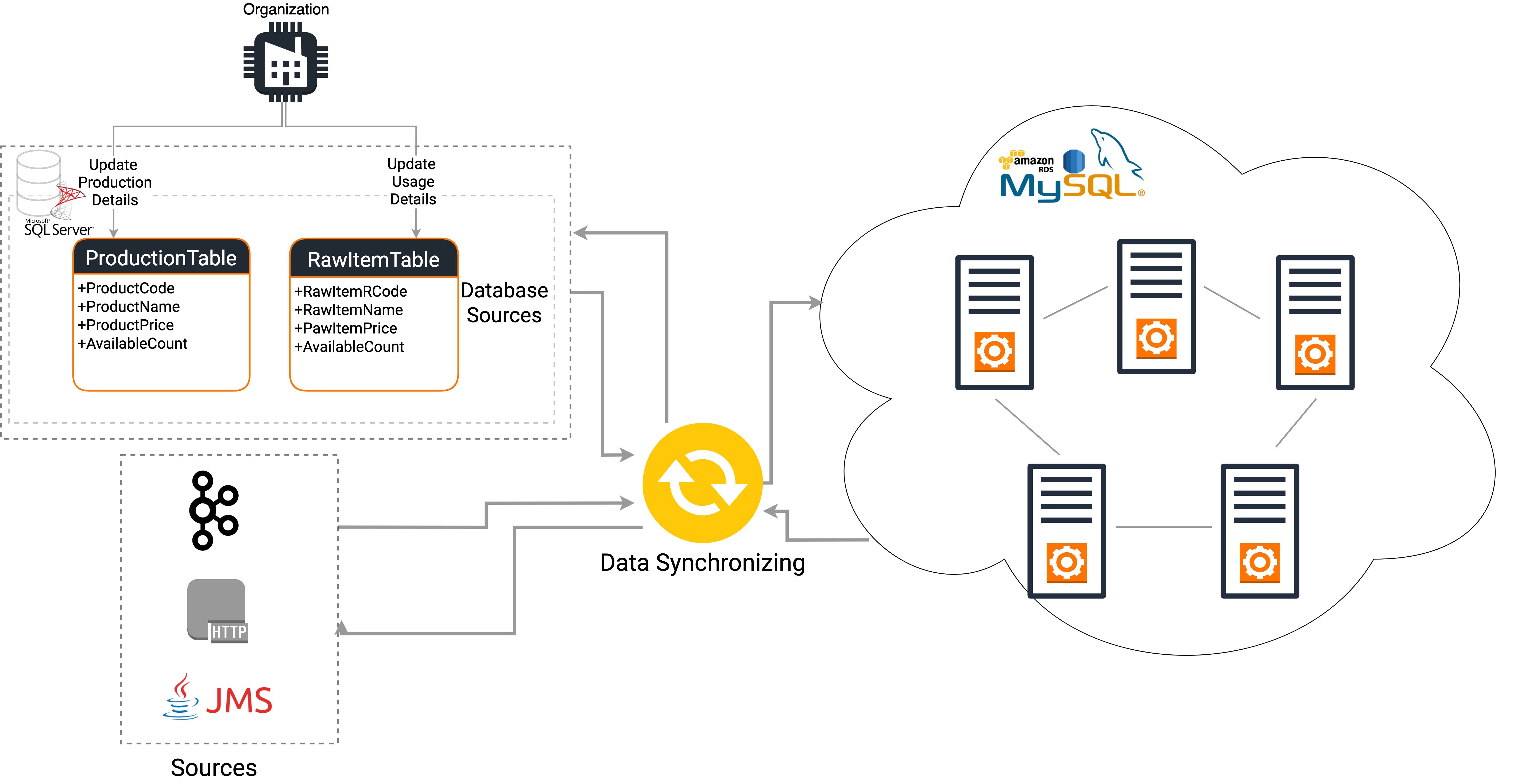
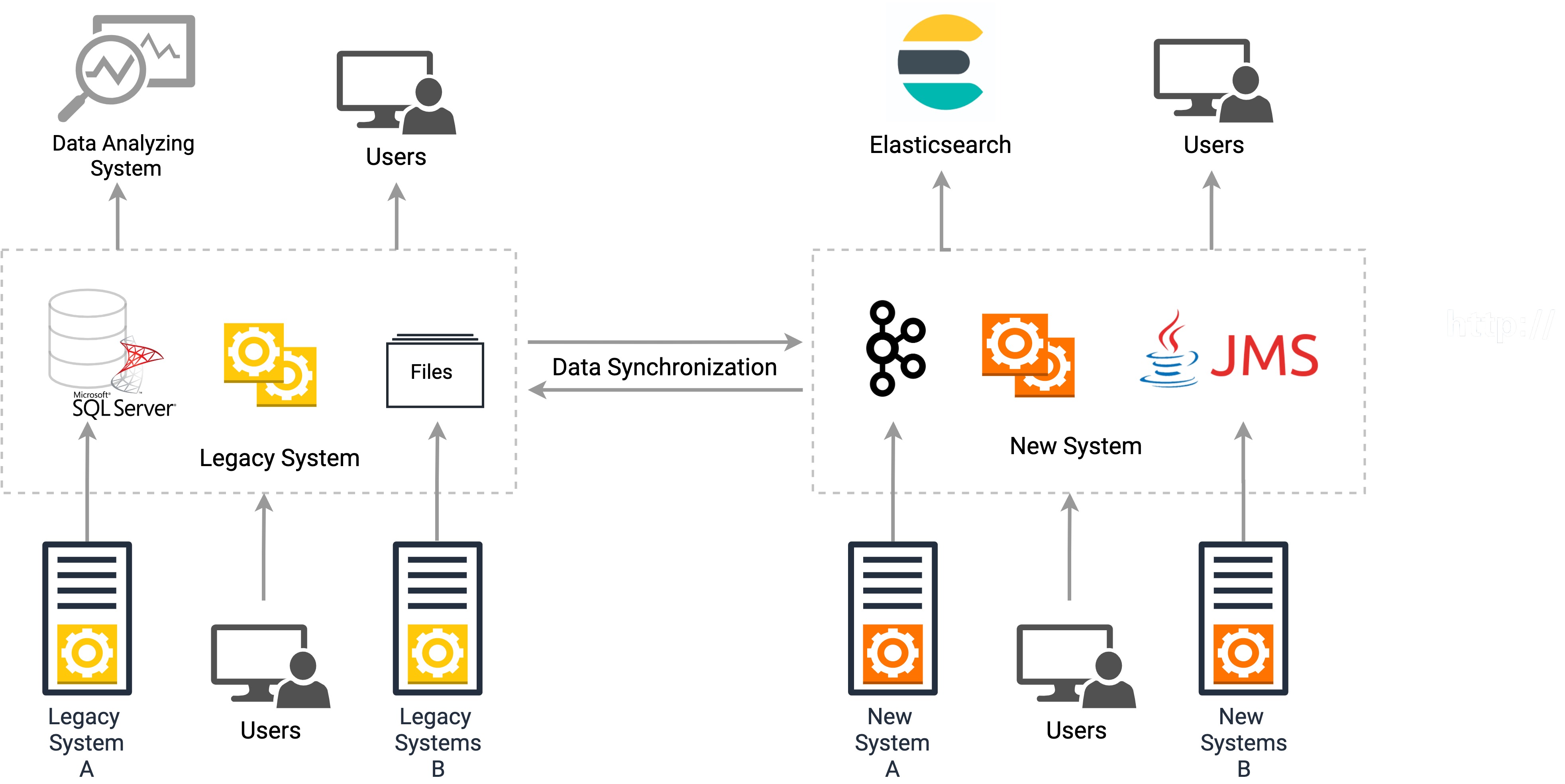
System Migrations: Another requirement of data synchronization is the intermediate state of a system migration (e.g., blue green migration) or in other words, when an organization has a legacy system running alongside with the new system. The legacy system dumps the data to a database or a file system, and there are other legacy systems that read and analyze this data. The new systems publish data via technologies such as Kafka, JMS, gRPC and HTTP, and the latest systems read and analyze this data. However, in order to ensure the consistency and accuracy of data for both legacy and new systems that read the data, a data synchronization mechanism should be available between the two systems.
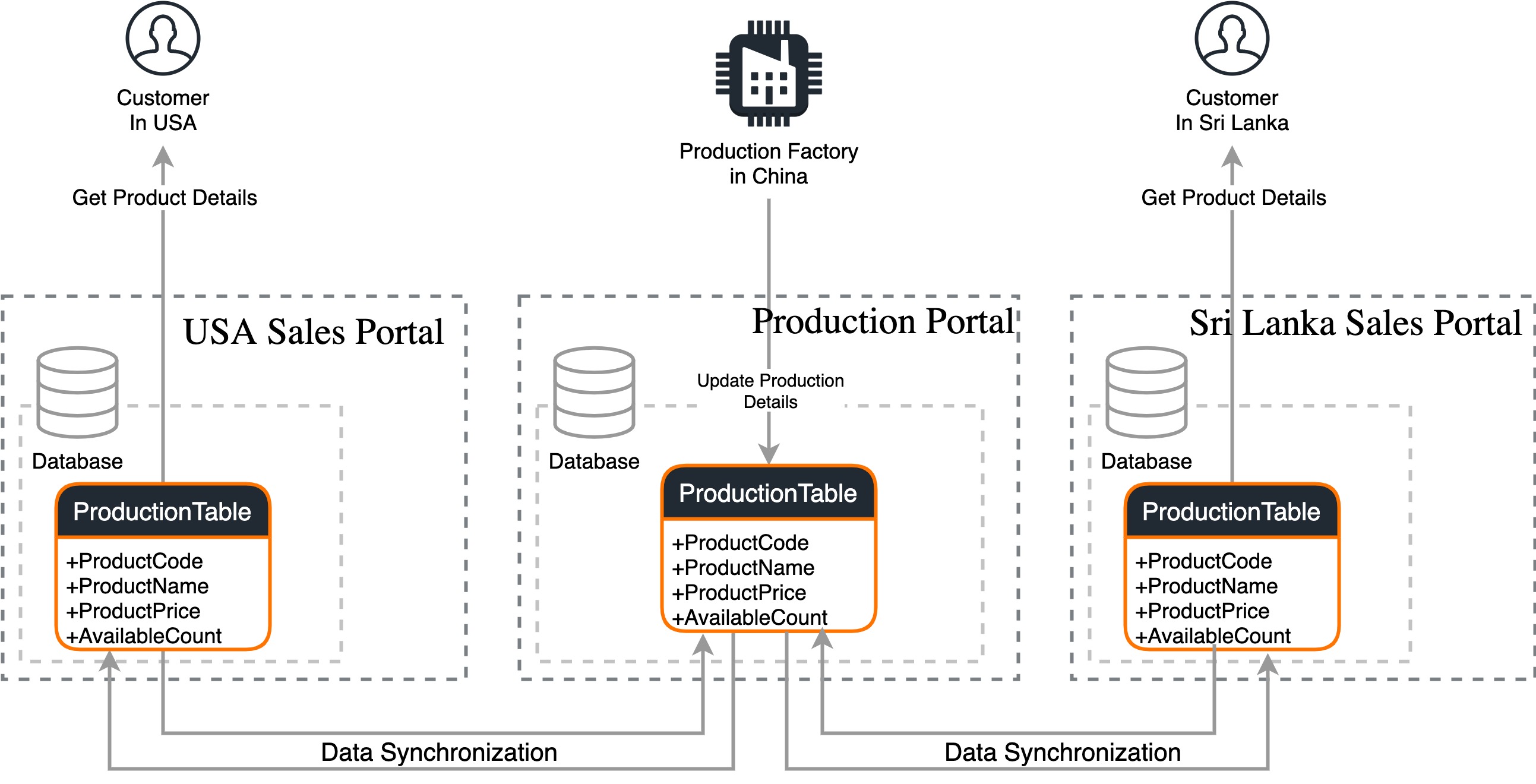
Business is now distributed globally: Organizations tend to have data distributed geographically for multiple purposes. These include running the business internationally, maintaining low latency, reducing network usage cost, and achieving high availability. When an update happens in a given system of a different region, it has to be also reflected in systems that are located in other regions. For an example, when a new product becomes available, that particular information should be available in all the regions even though the region-wise data instances are different.
Ease of maintenance: An organization may have ten departments, and these departments have their own databases for the ease of maintenance. When the production department outputs a new product, the sales department may need to enrich this data with the discounts that are given by the marketing department’s systems, and then store it in their own database. However, both sales and marketing departments need product details that are published by the production department. Therefore, all three data instances should be in sync.
Security: Organizations need to differentiate the data that can be accessed by different parties due to security issues. A production department may want to provide the data to be accessed by the customers. Also, there will be reads (viewing available products) and writes (placing orders) to the data, which the organization expects to keep separately due to security concerns.
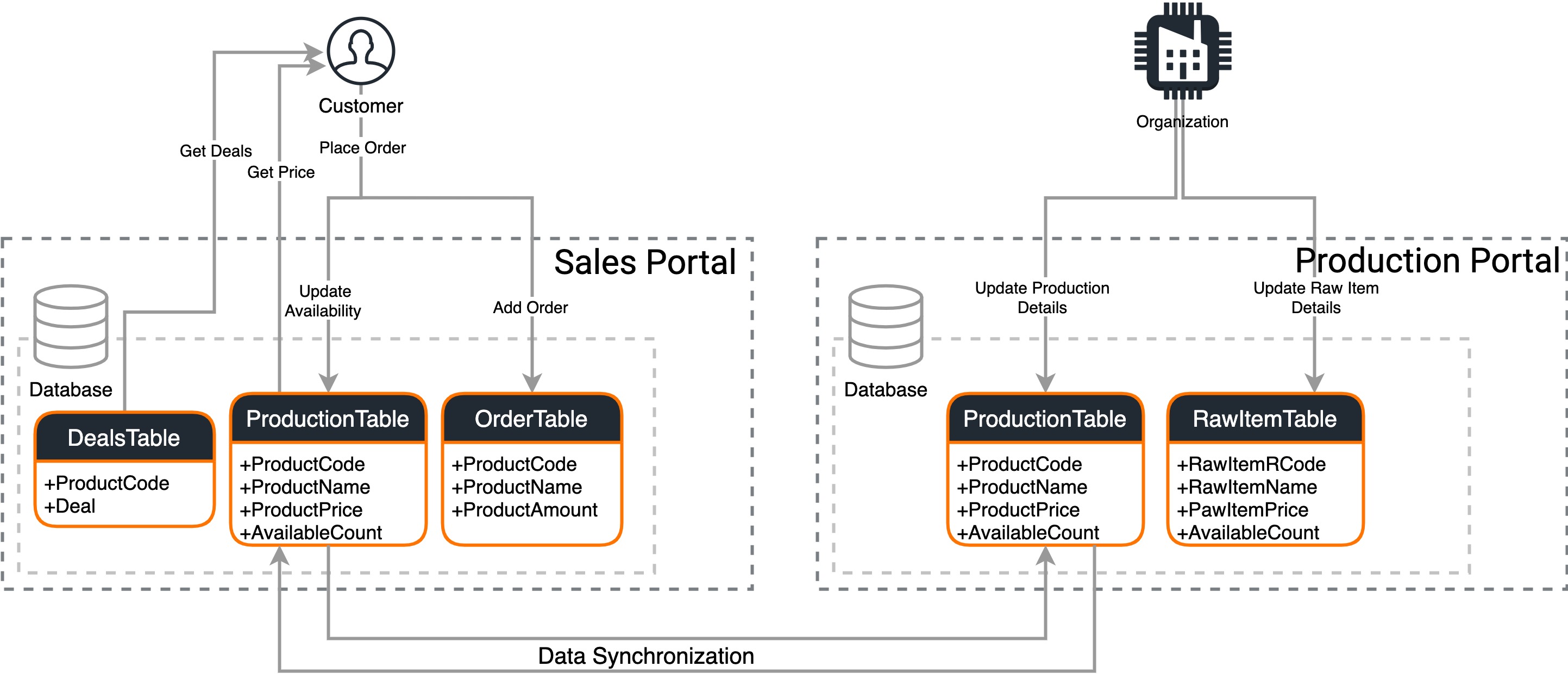
When a new product is manufactured, the customer portal should get updated. Similarly, when a customer places an order, the production portal should get updated even though these transactions are reflected in the respective portal databases, data synchronization ensures that it is updated in other databases as well.
How to Do Data Synchronization?
Some of the techniques used to retrieve the data for the synchronization are as follows.
Change log capturing: Changes can be added to a log, and then the log reader can read its events and send them to a relevant system or source.
Distributed transactions: This involves spanning a transaction to be executed in multiple data sources.
Querying the data by timestamps: A table can use a select query with a where clause that has a timestamp and send the result set to a relevant system or source.
Capturing data changes using table triggers: The database itself sends the change events to a relevant system or source.
Listening to a particular directory or file: The system checks for a file update, reads the new lines, and sends the update to a relevant system or source.
Challenges in Data Synchronization and How WSO2 Streaming Integrator (SI) Has Tackled It
- Today most of the companies operated with the data in realtime
Order processing system is an example for this. There are streams of data going through the systems in real time. This requires data synchronization to happen in real time as well.
WSO2 Streaming Integrator is powered by Siddhi IO, which is an in house stream processing engine that is designed to process complex events in real time.
- The availability of a variety of data formats
As organizations evolve with time, data synchronization has to be done between the systems with different data definitions. The synchronization mechanism should be able to convert the data accordingly.
WSO2 Streaming Integrator achieves this via the usage of various data mappers (JSON, Text, Binary, etc.) available in Siddhi. Siddhi queries can also transform data to any given definition by adding or removing attributes to the data.
- Performance
Data synchronization involves a high frequency of data extracting, transforming, and loading. Proper capacity planning has to be done to avoid any impact on the system in peak durations.
As elaborated in my recently published article Streaming ETL with WSO2 Streaming Integrator, the product was able to process a file with 6,140,031 Lines (size: 124M), and copy the data to a database (AWS RDS instance with oracle-ee 12.1.0.2.v15) in 1.422 minutes (85373ms) using an m4.xlarge instance.
- Accuracy and data quality
When data is transferred from a system to another, there can be many complications due to malformed data. Those have to be looked into and monitored closely.
Siddhi fault stream has been implemented to gracefully handle failover scenarios that occur during runtime.
- Security
Data synchronization process has to connect into different systems with various security protocols.
When implementing the sources and sinks, the security measurements have been taken. For an example, you can can enable basic auth and enable key-stores, etc., using parameters in siddhi-io-http when it is connecting to endpoints.
- Development
It should be possible for a person who is not familiar with the product or the language to develop a data synchronization solution.
A developer needs to write several siddhi queries in order to synchronize data using WSO2 Streaming Integrator. However, even a developer with limited knowledge of Siddhi is able to use the Design View of WSO2 Streaming Integrator Tooling, which you can download from here.
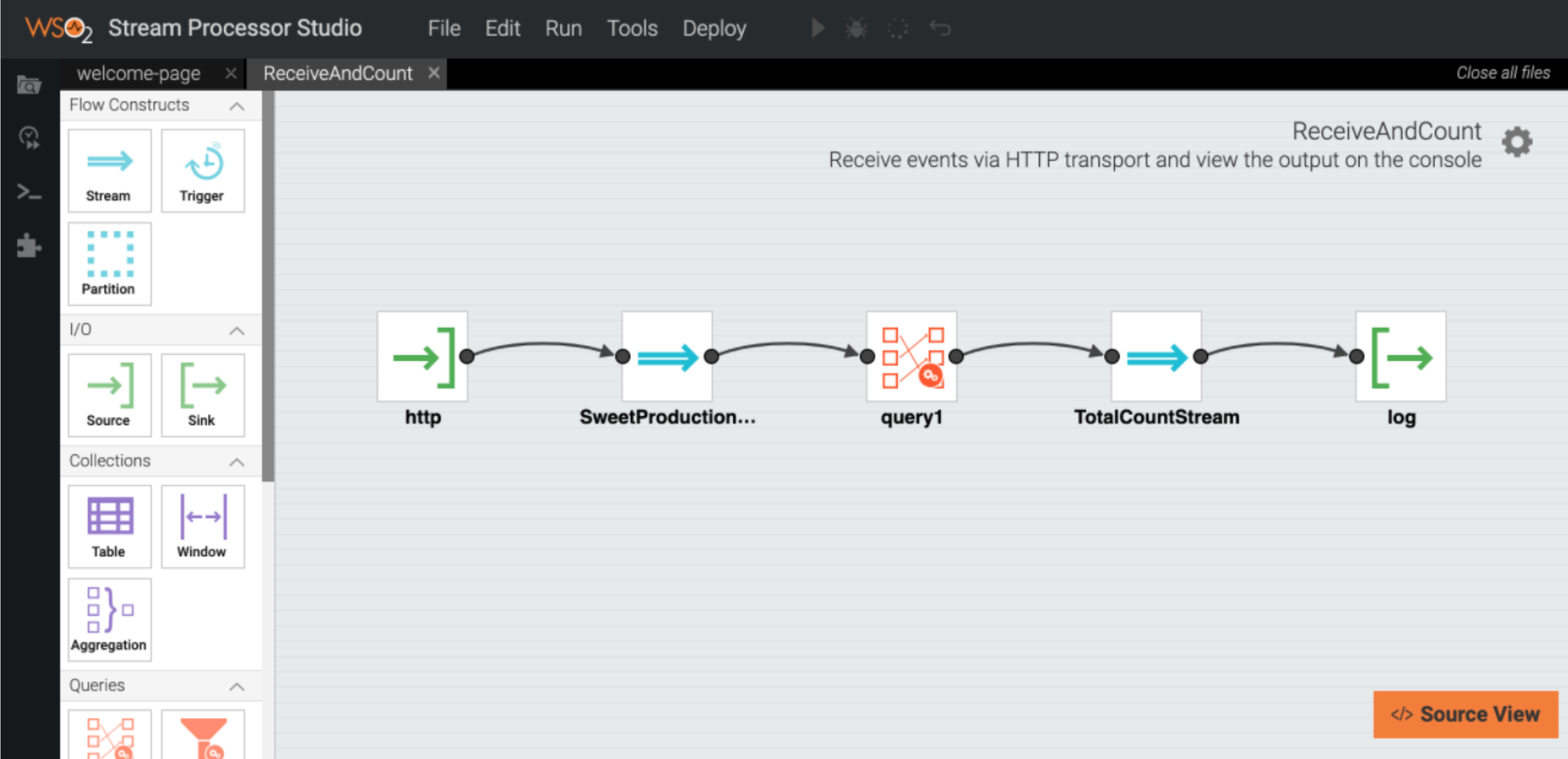
- Deployment
A solution should be implemented seamlessly regardless of the geographical area, limited resources, etc .
Regardless where your data is being held, the WSO2 SI can be deployed in K8s, Docker (for example, check my blog post Deploying WSO2 Streaming Integrator on AWS ECS in Minimum HA Mode) or in VMs, and operate seamlessly
- Monitoring
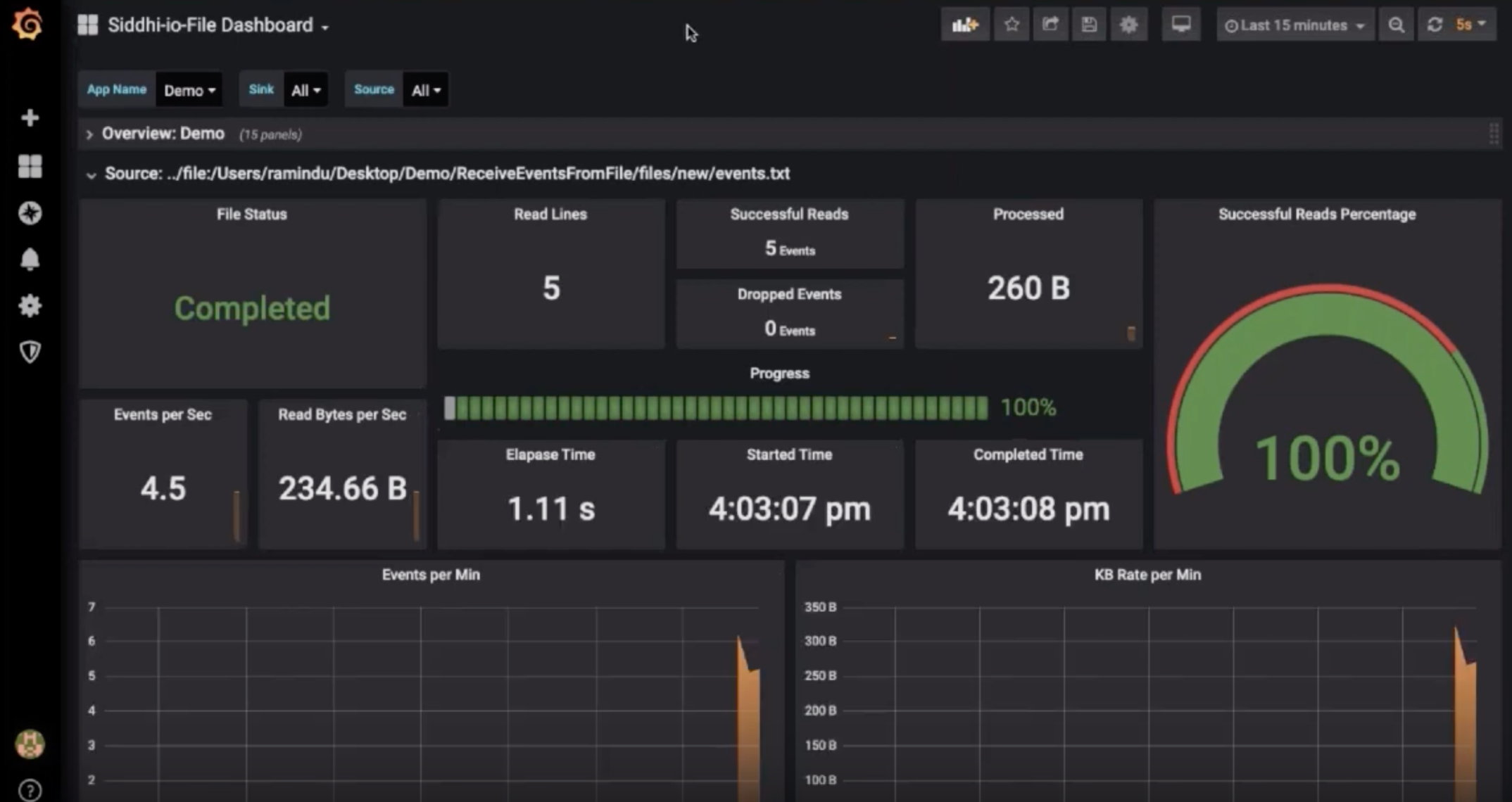
When the data synchronization happens, one or more parties may need to track the progress of the process (e.g., check the latency and throughput) and be informed when it is completed.
WSO2 SI publishes statistics from its sinks and sources to Prometheus allowing them to be later visualized via Grafana dashboards.
Let's see how WSO2 Streaming Integrator caters to the data synchronization requirements using a simple scenario which is mentioned in our second use case (System Migrations).
Data Synchronization Using WSO2 Streaming Integrator
Let's eliminate all the publishing and receiving parties from the deployment and simplify the last diagram, and see how the data synchronization can be done.

In order to keep both systems in synchronization, the changes happening in the database and file systems should be transferred to the Kafka server and via HTTP to the new systems. When the new system receives events via Kafka and HTTP, those have to be added to the databases and file systems that are used by the legacy system. We also need to take the data formats used by the two systems into consideration when syncing the data.
Synchronize Data Using Static Sources
According to our use case, this covers how to synchronize data from the legacy system to the new system.
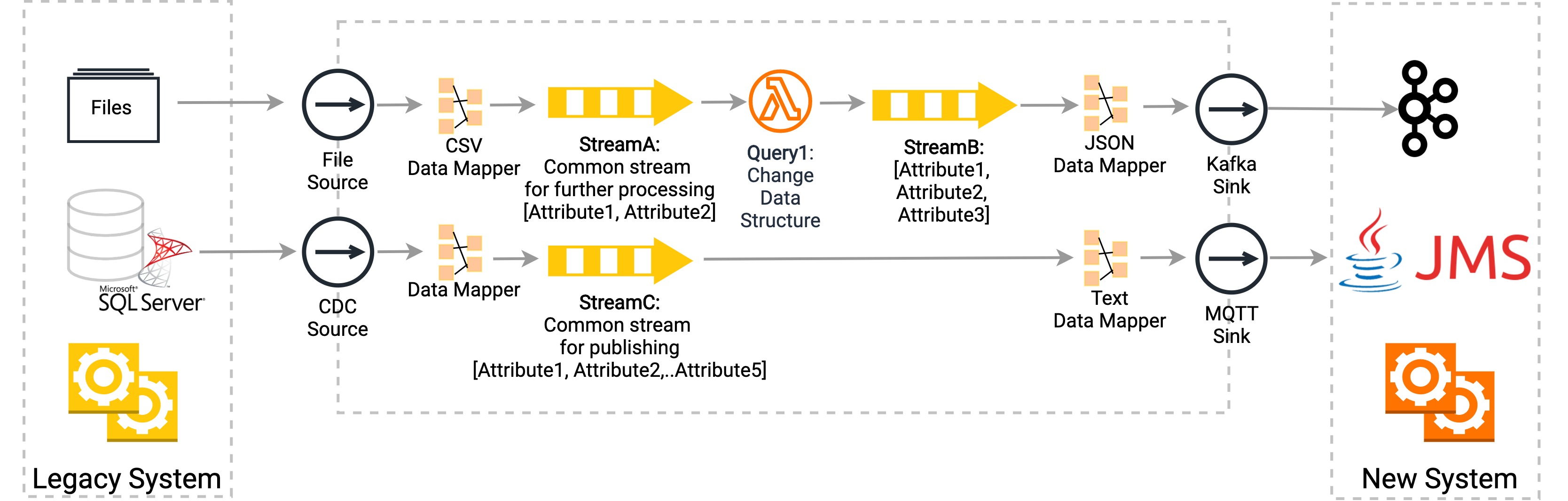
Synchronizing Data in Log File
Let's assume the event definition that is received by Kafka (which has three attributes) differs from the event received by the file (which only has two attributes).
The siddhi-io-file source is used with the line mode by enabling tailing, so that each and every update of a file can be captured and sent to the Streaming Integrator for further processing. Due to the change of event definition used by the Kafka consumer at the other end, Query1 does what is necessary to change the event to adhere to the event definition (maybe by adding a timestamp) before sending it via the siddhi-io-kafka sink.
Synchronizing Data in Database
The siddhi-io-cdc extension’s source can be used with `listening` mode to get the latest changes in near real time (`pooling` mode can be used with a user given interval if needed for the databases that do not support the listening mode). Since the data format has not changed in the new system, the same data can be sent without any changes via siddhi-io-jms sink.
Synchronize Data Using Streaming Sources
When addressing our use case, this covers how to synchronize data from the new system to the legacy system.
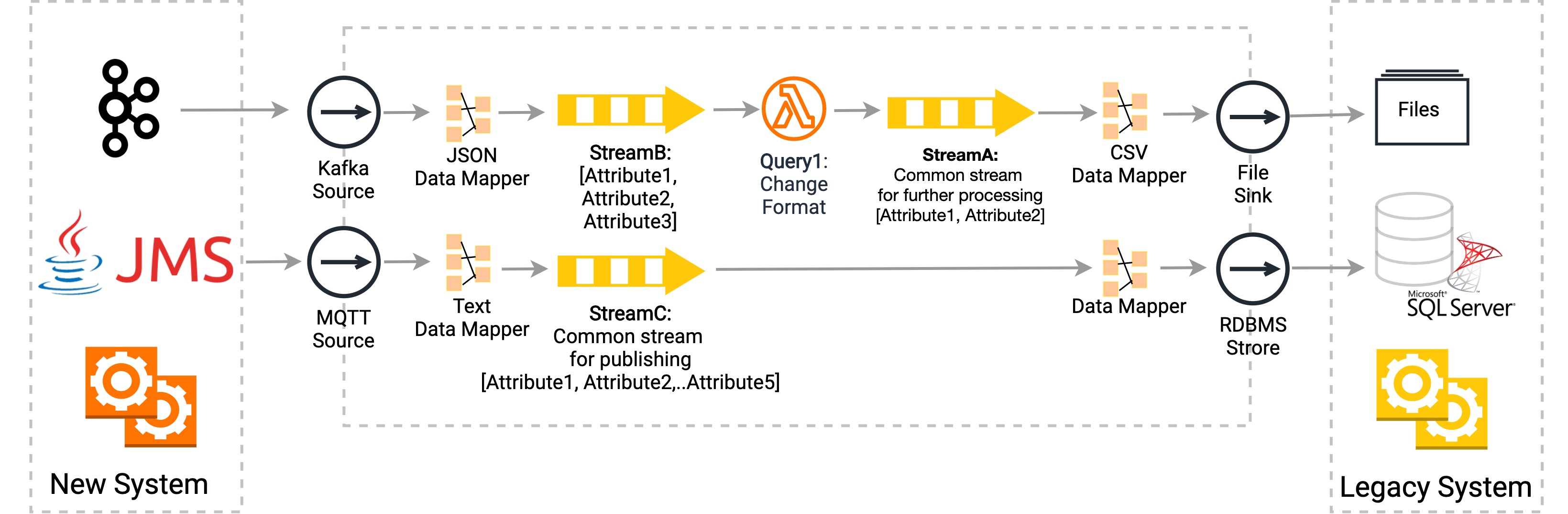
Synchronizing Data Published via Kafka
As mentioned above the event definition that received by Kafka (has three attributes) differs from the event received by the file (which only has two attributes).
A siddhi-io-kafka source listens to the same topic which in turn listens to the new system, and converts the event to the event definition format that adheres to the legacy system’s file events. Query1 does what is necessary to change the event to adhere to the event definition (maybe by removing the timestamp) and appends the output to the particular file via siddhi-io-file sink. This file is then read by the legacy system.
Synchronizing Data Published via JMS
A siddhi-io-jms source listens to the same topic which in turn listens to the new system, converts the event to a data definition format that adheres to the legacy system’s database format, and stores the output in the database via siddhi-store-rdbms.
The same way, WSO2 Streaming Integrator can receive events via HTTP, TCP, gRPC, RabbitMQ, IBM MQ, Thrift and Binary protocols using WSO2Events, Databases, Files, Web-sockets, Amazon S3, Google Cloud Storage(GCS), etc., regardless of whether the type of the source is streaming or static, and then use the relevant sinks (either streaming or static) to synchronize the received data.
Summary
This article discusses the need for data synchronizing due to the increasing use of hybrid platforms, systems being globally distributed, security, and ease of maintenance. Then it explains how to perform data synchronization via WSO2 Streaming Integrator while overcoming its challenges.
Opinions expressed by DZone contributors are their own.
Comments