What Is Sharding?
Sharding is a technique of splitting some arbitrary set of entities into smaller parts known as shards. It is used to achieve better consistency and reduce contention in our systems.
Join the DZone community and get the full member experience.
Join For FreeSharding is a technique of splitting some arbitrary set of entities into smaller parts known as shards. It is used to achieve better consistency and reduce contention in our systems.
In this article, I will tell you a few more things about sharding which despite its significance, also has some cons, and there are certain problems you may encounter if you decide to use it. What are they? I’ll explain that below.
Before we dive in though, let's start with a recap of scalability and distributed systems.
Disclaimer: This article is focused on sharding as a concept in general, not on database sharding of any type.
What Do We Know About Scalability?
First things first: I’m pretty sure you know what scalability is, but let’s have a brief look at the definition just to be safe. Scalability is the ability, surprise, of a system or application to scale. It is probably one of the most crucial non-business features of every modern-day piece of code. After all, we all want our systems to be able to handle increasing traffic and not just crash the first chance they can.
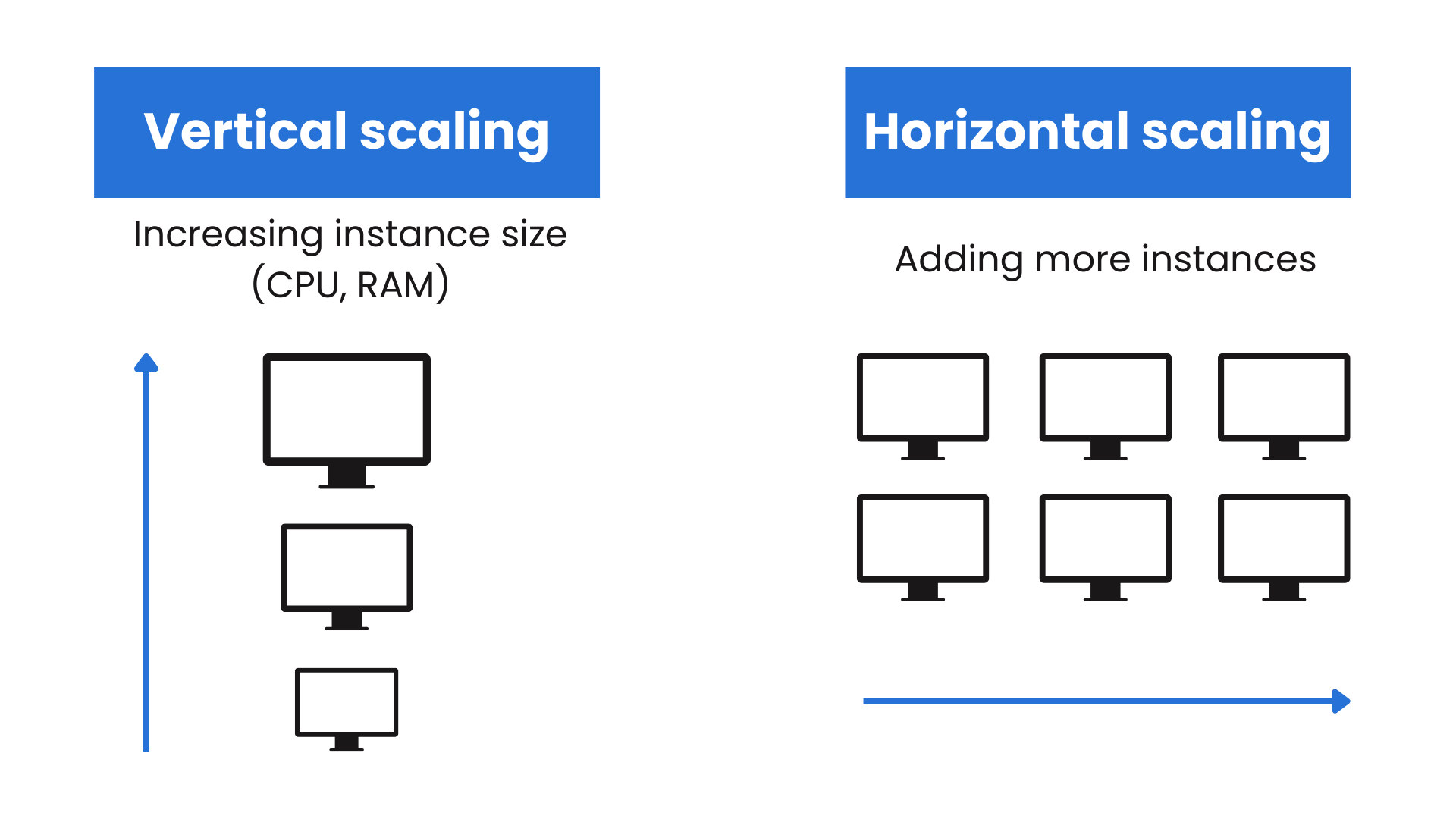
So when we’re looking at scaling, there are two ways to handle that task — Horizontal and Vertical. I will dive deeper into this matter someday in a separate article, but for now, you can find an illustration and a quick recap below.
Horizontal scaling is focused on adding more nodes to the systems while vertical scaling is about adding more resources to a single machine that is responsible for hosting our application.
What Is a Distributed System?
Distributed systems are all systems that are spread across more than one node and connected over a network of any type. Work in such a system is split across all nodes existing inside the system. The nodes coordinate their efforts to be more efficient than a single-node environment.
The biggest advantage of distributed systems is the ability to scale horizontally by adding more and more nodes to the cluster (of course, such scaling has its limitations, you can read about them here). Additionally, such systems greatly reduce (or at least they should) problems with a single point of failure, helping to increase resilience and fault tolerance of the system.
Despite such advantages, distributed systems bring us to a whole new level of problems, especially since they significantly increase the complexity of software — occurring issues are more complex and errors become harder to recreate, we can start to notice that bandwidth of the internet connection is important, the network is not as reliable as we might expect, and that for sure the network is not secure.
What Is Sharding?
Let’s start with a quick look at the dictionary definition of the word “shard”: a small part of a whole. By extension, we can expect sharding to be related with a splitting of some arbitrary whole into smaller parts. In a nutshell, it is exactly what sharding as a concept is about.
If you’re willing to go into more detail, sharding is about using some unique identifier known as a shard key to equally split some arbitrary set of entities like domain entities from DDD, actors in case of Akka, or data in a database into smaller parts known as shards. After sharding is done, we end up with each particular entity existing only in one shard and a particular shard existing only within one location.
What’s more, sharding can be viewed as a very specific type of partitioning, namely — horizontal partitioning. The main difference is that sharding explicitly imposes the necessity to split data into multiple physical machines while partitioning does not.
As a side note, I want to add that if you decide to use sharding, you should aim to have at most ten times more shards than nodes. A higher number of shards per node can indicate some flaws in design.
Having discussed a quick technical definition of sharding, we can now move on to explaining when to use it.
When to Use Sharding
Despite being a useful and powerful tool, sharding can also be a massive investment of time and as such, it should be carefully planned and considered.
Some of the essential factors that should drive the usage of sharding are:
- Need for better consistency guarantees without performance decrease
- Lots of contention inside the system
- Lack of other possibilities to scale
Pros of Sharding
The biggest pros of sharding is that it can isolate contention to a level of single shard. Sharding can also decrease the amount of distributed operations in our systems. Because each entity exists in only one place of the system, we effectively have to distribute only operations that involve entities on many shards.
Both reduction of contention and distributed operations can greatly increase the performance of our system as contention and cross-talk are two main factors that limit scalability.
Cons of Sharding
The main issue with sharding is that it is a complex technique and requires a lot of thinking and planning to be implemented correctly. What’s more, because each shard is present in only one location, there can be times when one of the shards is unavailable due to some failure – which effectively reduces the availability of the system.
Last but not least, contention is not eliminated entirely. It is isolated to a level of a single shard and a portion of it is moved to another region of our codebase, for example, coordinator — a technical entity responsible for routing messages to the proper shard.
Types of Sharding
Looking at the types of shard keys, we can differentiate two types of sharding:
- Hash/Algorithmic — when we are using single or multiple fields as an input to hash a function or an algorithm whose output will be further used as our shard key.
- Range-based — when we are using single or multiple fields along some predefined config key to route this entity to the appropriate shard.
Hash vs Range-Based Sharding
The biggest pro of hash-based sharding is that it greatly increases the chances of having evenly distributed shards. In comparison, when using range-based sharding, we can quite easily end up with hotspots.
Unfortunately, range-based sharding works best with large cardinality, low frequency, and non-monotonic shard keys — and achieving all three traits can be problematic.
On the other hand, if you are using hash-based sharding and decide to change the sharding algorithm or modify the number of shards, it can be a huge task. It will require redistribution of all the entities currently present in shards.
Another drawback of hash-based sharding is that closely related entities are more likely to be distributed on many shards instead of being put into a single one.
What Is a Shard Key?
It is a term used to describe a value or a field that is used to distribute entities into shards. It should allow for even distribution of entities across shards and, in a perfect scenario, also put closely related entities near one another — preferably on a single shard.
A poor shard key can result in hotspots — shards that are considerably heavier than others, poorly distributed entities — lots of distributed requests for data located on many different shards to return matching results.
How To Choose a Good Shard Key?
Choosing a good shard key is one of the most critical problems when using sharding — a poor shard key can outweigh all the potential benefits that sharding offers.
Below, I listed the most important factors that we should take into consideration when choosing a Shard Key:
- Cardinality — will help with shard distribution. It will also enforce the number of possible shards inside the system. In general, we should aim to use shard keys with high cardinality as it will allow us to create more shards.
- Frequency — plays an important role in evenly distributing our entities in shards as a low-frequency shard key can more easily generate hotspots.
- Value randomization — we should aim to have good randomization of shard key values as monotonic growth can increase the chances for the occurrence of hotspots.
Remember that only a good combination of all three parameters can guarantee the proper distribution of entities in our systems because any of these parameters on its own is not enough.
Conclusion
Sharding is a very powerful concept that can greatly increase our systems’ ability to scale while maintaining good, consistent guarantees. Unfortunately, it can also negatively impact the availability of our systems.
Additionally, while designing a system to support sharding, we should remember about selecting the right shard keys as they are crucial in how a sharded system will behave. Thank you for your time.
Sharding FAQ
What is sharding
Sharding is about using some unique identifier known as a shard key to equally split some arbitrary set of entities into smaller parts known as shards.
What types of sharding exists
We can differentiate Hash/Algorithmic and Range-based sharding
What Is a Shard Key
It is a term used to describe a value or a field that is used to distribute entities into shards
Opinions expressed by DZone contributors are their own.
Comments