Veeva Nitro and AWS SageMaker for Life Sciences Data Scientists
There is a rise in industry-specific data analytics solutions because building up and maintaining a custom data warehouse is difficult.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
There is a rise in industry-specific data analytics solutions because building up and maintaining custom data warehouses is difficult. It requires extensive development and operational efforts to define the appropriate industry-specific data model for the business intelligence tools, follow all the shape changes over time (new tables, new columns, new relationships) and design the ETL processes for a wide variety of data sources. It is just hard to build a solution on top of a generic data warehouse where you can get great platform capabilities but you still have to start with a CREATE DATABASE SQL command.
This is the reason why Veeva decided to build Nitro, the data science and analytics platform. It is designed to accelerate time-to-value by getting data quickly from Veeva Commercial Cloud (CRM, Vault, Align, Network) and other common life sciences platforms (e.g. Salesforce Marketing Cloud) into Nitro using predefined intelligent connectors.
Veeva Nitro Architecture
Nitro is built on top of AWS Redshift and Veeva has added a lot of industry-specific capabilities to AWS's popular data warehouse platform.
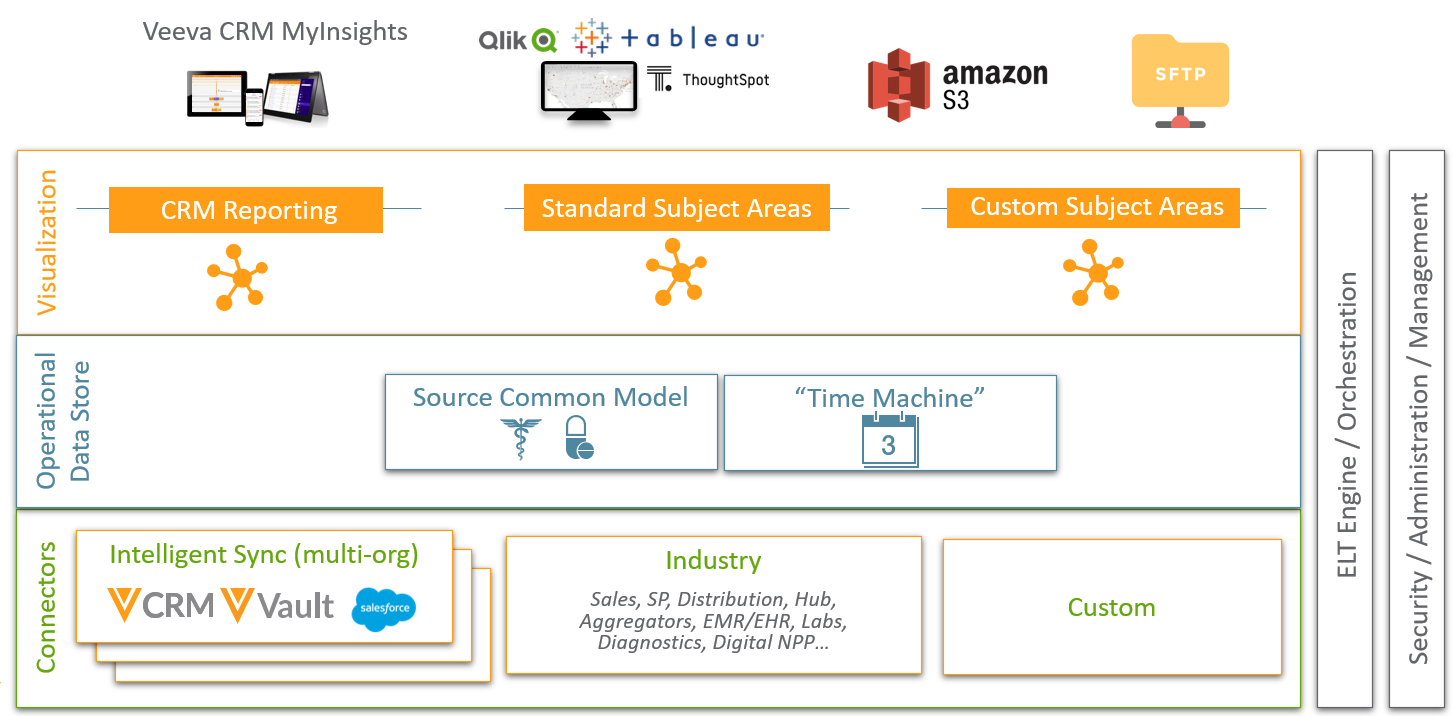
At the bottom of the diagram, we can find various connectors that can bring data into Nitro. Some connectors like Veeva CRM, Vault, Align, Network, and Salesforce Marketing Cloud are dubbed as Intelligent Sync because the connector can automatically detect data model changes in the source side (e.g. newly added objects or fields) and can update the ETL processes accordingly. Other connectors are designed to support industry-standard data providers such as Symphony, ValueCentric, McKesson, etc., and are relying on Nitro SFTP servers. Custom connectors can also be built for custom schemas and objects using the same SFTP-based approach as the industry connectors.
In addition to inbound connectors, Veeva Nitro also supports outbound connectors which can be used to export and transfer data to external systems like an SFTP server or AWS S3. And Veeva has just recently launched PushToCRM which can load data from Nitro into Veeva CRM.
Nitro also comes with prebuilt database schemas for Operational Data Store storing raw data from the sources and for analytics purposes it has a Dimensional Data Store (DDS) which is using a star schema architecture and contains fact tables surrounded by dimensions.
As for analytics, reporting and data sciences purposes Nitro offers a JDBC connector (similar to the standard AWS Redshift connector) and the aforementioned outbound connectors in order to extract and share data with other 3rd party tools. The most popular tools like Tableau, Qlik, Power BI can be plugged into Nitro using their standard DWH connectors based on JDBC. Others, like AWS SageMaker, can use AWS S3 for data exchange. And on top of this, Nitro has also the capability to sync the data to the Veeva CRM iPad application where Veeva's own MyInsights data visualization tool can present the most relevant data sets to the sales reps.
Veeva Nitro and AWS SageMaker: A Solution for Pharma Data Scientists
In order to demonstrate how easy and elegant to work with Veeva Nitro and AWS SageMaker together, we will go through a use case to identify what are the most reasonable time slots for a particular day of the week to send Approved Emails to the doctors and nurses to get the highest chance that the emails will actually be opened and clicked.
These Approved Email activity stats are collected in Veeva CRM and thanks to the Nitro CRM Intelligent Sync connector can be easily pulled into the Nitro database.
Then the first step will be to define an outbound connector for Nitro to extract the records from the Nitro schema and store them in files inside an AWS S3 bucket.
The Nitro configuration can be executed through Nitro Admin Console (NAC).
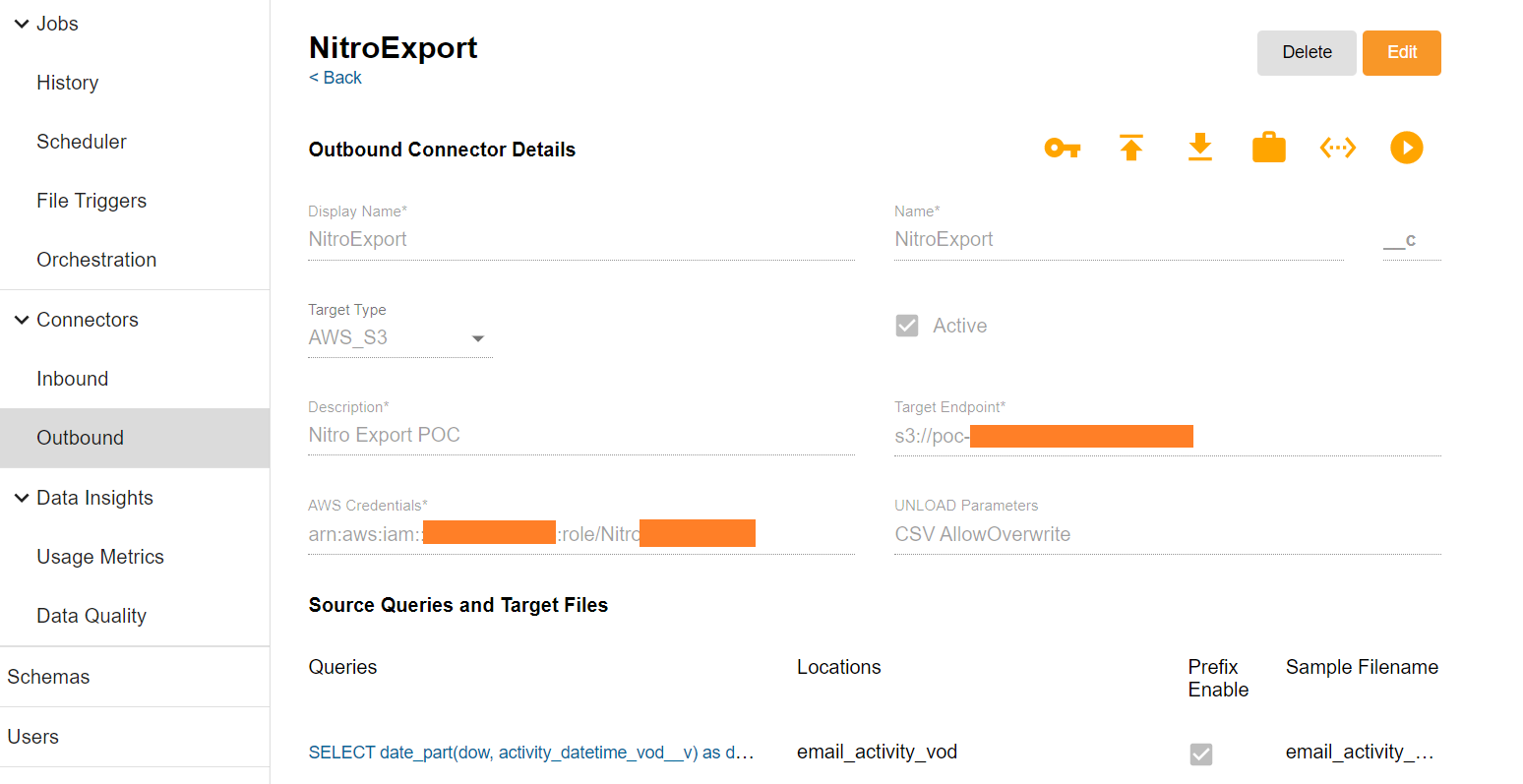
This connector requires defining the target type (AWS S3), the target S3 endpoint, and the AWS credentials. Then we need to define a SQL query what data we want to extract into the files in the target S3 bucket.
xxxxxxxxxx
SELECT
date_part(dow, activity_datetime_vod__v) as day_of_week,
case
when date_part(hr, activity_datetime_vod__v) >= '0' AND date_part(hr, activity_datetime_vod__v) < '3' then 0
when date_part(hr, activity_datetime_vod__v) >= '3' AND date_part(hr, activity_datetime_vod__v) < '6' then 1
when date_part(hr, activity_datetime_vod__v) >= '6' AND date_part(hr, activity_datetime_vod__v) < '9' then 2
when date_part(hr, activity_datetime_vod__v) >= '9' AND date_part(hr, activity_datetime_vod__v) < '12' then 3
when date_part(hr, activity_datetime_vod__v) >= '12' AND date_part(hr, activity_datetime_vod__v) < '15' then 5
when date_part(hr, activity_datetime_vod__v) >= '15' AND date_part(hr, activity_datetime_vod__v) < '18' then 6
when date_part(hr, activity_datetime_vod__v) >= '18' AND date_part(hr, activity_datetime_vod__v) < '21' then 7
when date_part(hr, activity_datetime_vod__v) >= '21' AND date_part(hr, activity_datetime_vod__v) < '24' then 8
end timeslot,
activity_datetime_vod__v,
case
when event_type_vod__v = 'Opened_vod' then true
when event_type_vod__v = 'Clicked_vod' then true
else false
end opened
FROM
vspa_ods__v.email_activity_vod_ods__v
WHERE
activity_datetime_vod__v >= '2020-01-01'
In our case, the records get transformed via the SQL query to better suit the SageMaker AutoML model. We aggregate Opened and Clicked status into one (Opened = true) and also create 3-hour timeslots based on the activity times. In addition, we also extract the day of week values from the activity time field (Monday=1, Tuesday=2, etc.).
Below are the data files on AWS S3:
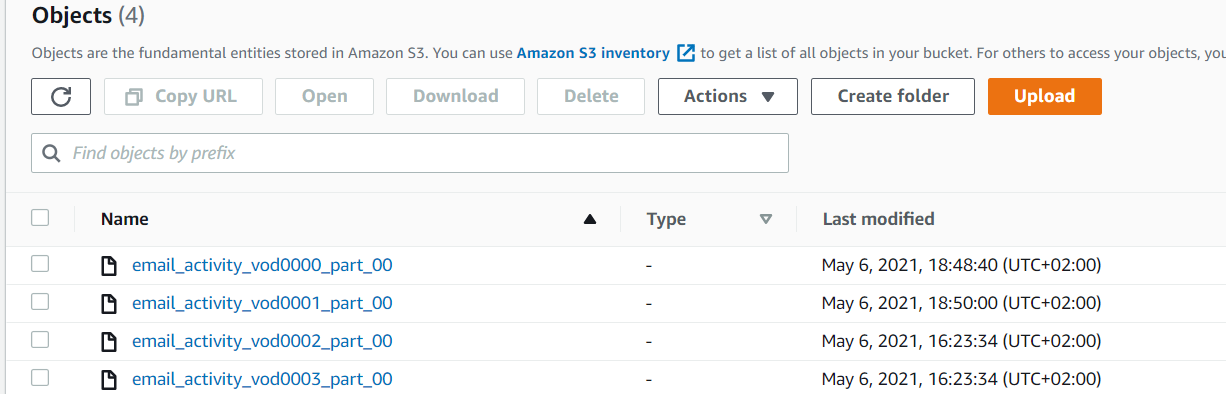
and the content looks like this:
x
4,7,2021-01-28 18:36:06,t
3,5,2021-01-27 13:54:47,t
3,5,2021-01-27 14:28:32,t
3,7,2021-01-20 20:01:22,t
...
where the values in the first row mean:
4is Thursday7means it was sent in timeslot 7 (i.e. between 18:00 and 21:00)2021-01-28 18:36:06means the actual timestamp when the email was senttmeans true, i.e., it was opened.
Now, that we have the entire dataset extracted from Nitro and loaded onto ASW S3, we can start using AWS SageMaker to create predictions about when the emails are likely to be opened.
Amazon SageMaker Autopilot is designed to automatically create the best classification and regression machine learning models, while still allowing control and visibility of how the model works. Essentially it means automatically finding an algorithm that can extract patterns from an existing data set, and build a predictive model that will work well with new data.
In our example, we are using AWS SageMaker Studio that is based on JupyterLab to execute our Python ML code. We are utilizing the standard Python3 (Data Science) kernel from AWS. First, we import all the required packages and then using the AWS S3 copy command to inject data from the AWS S3 bucket where our Nitro extracts are stored in SageMaker.
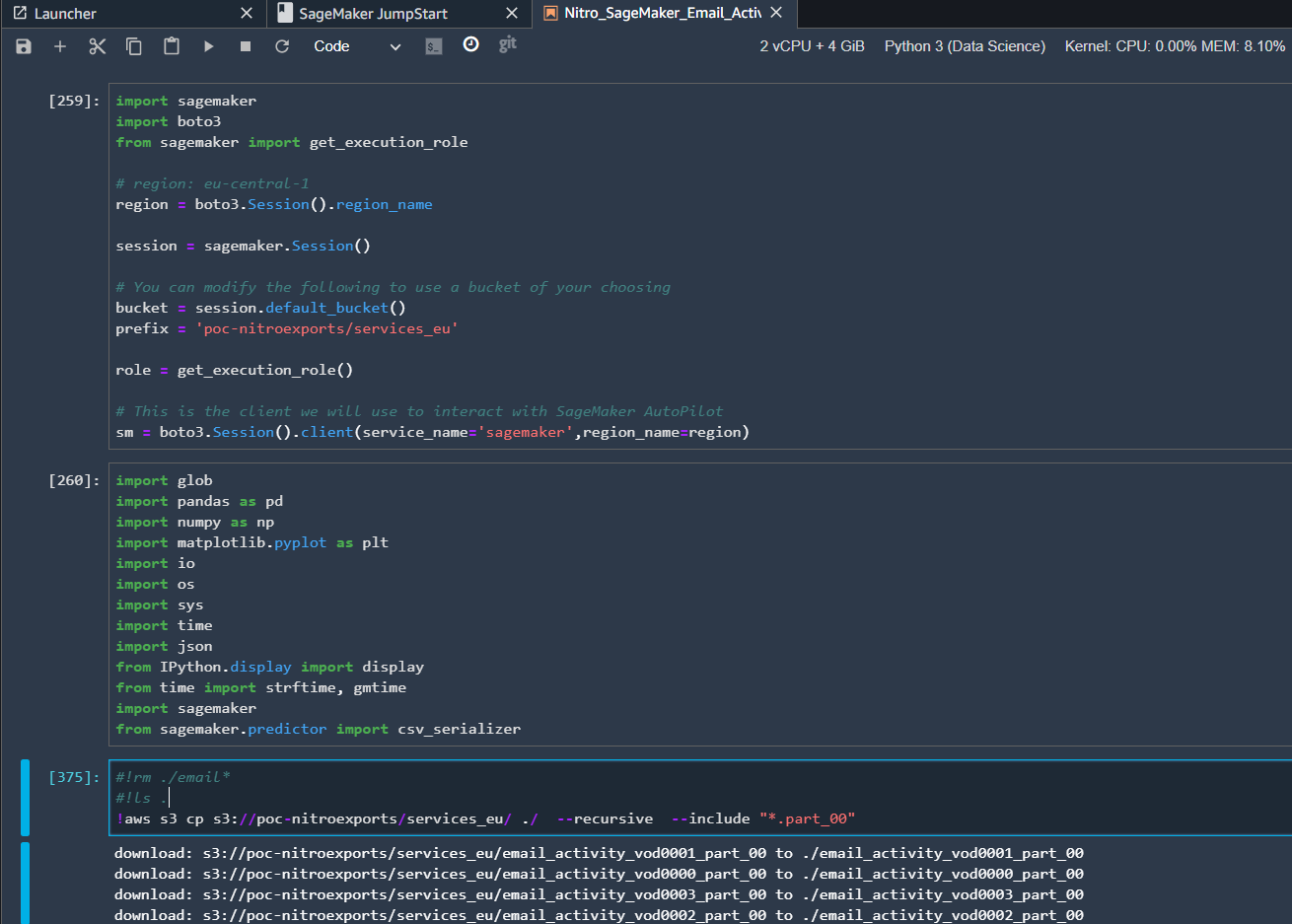
Once that is done, we are using Pandas framework to wrangle the data and label the columns as expected by SageMaker Python framework.
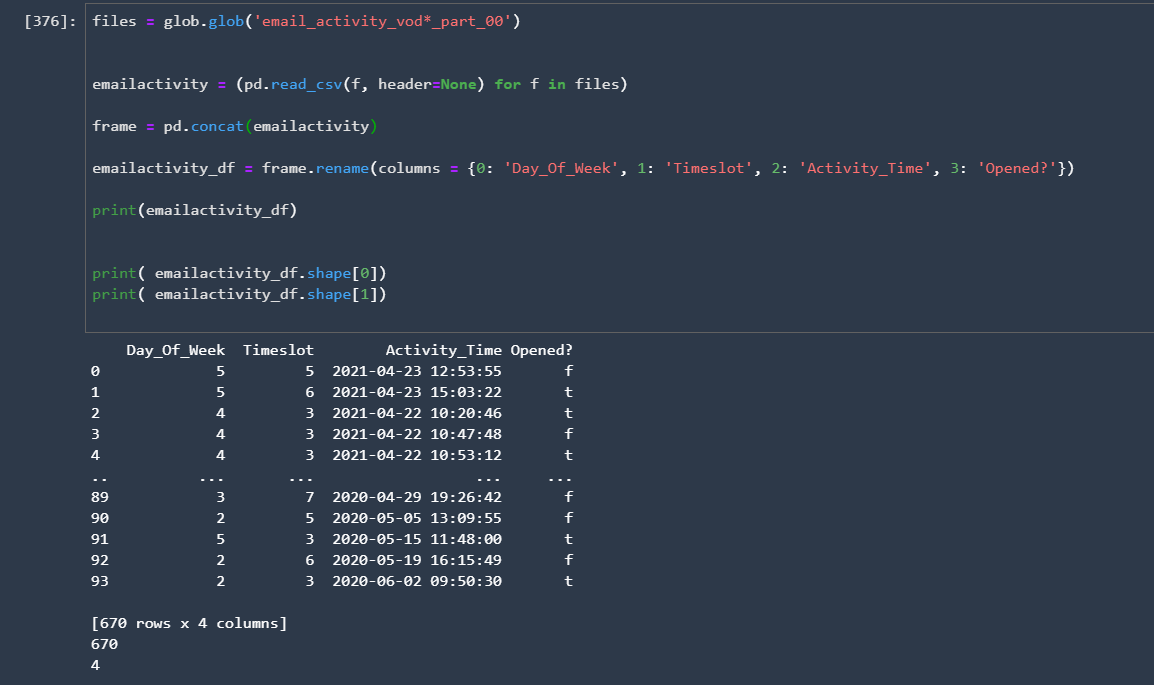
After that, we split our input data into training and test data sets (80% for training, the rest is for testing).
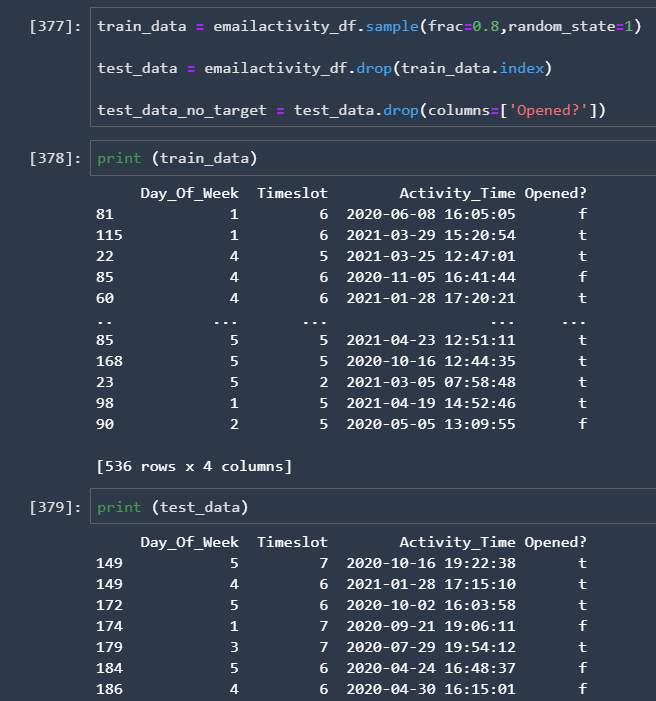
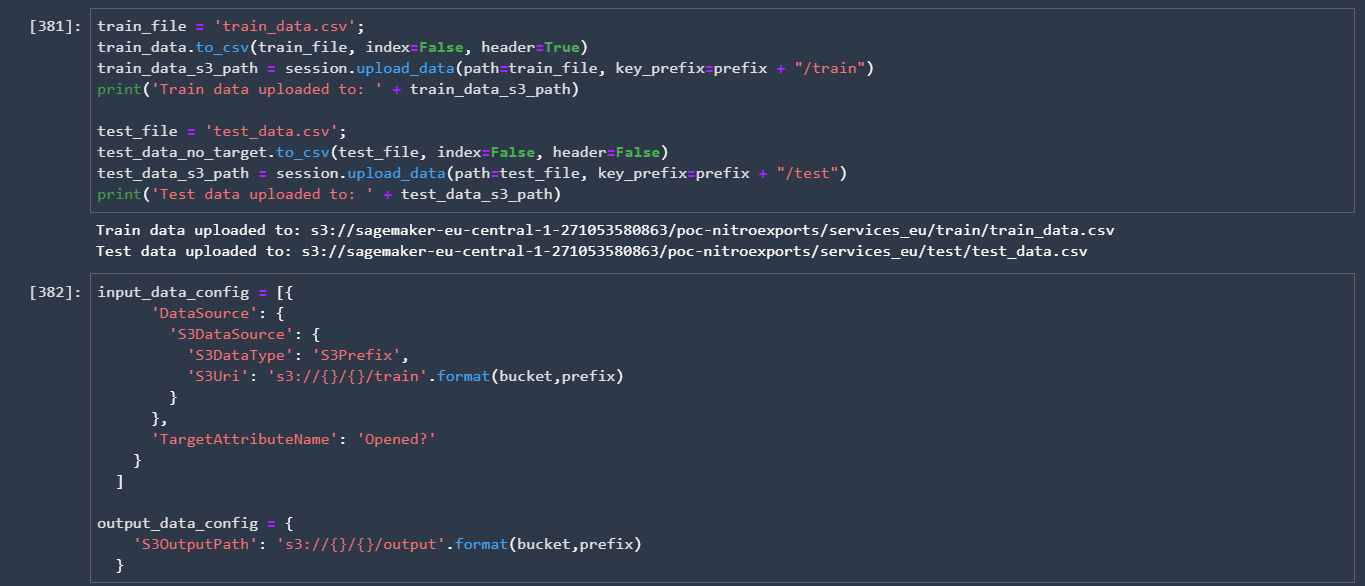
Then we uploaded the training and test data sets onto SageMaker S3 bucket and also defined the config parameters for SageMaker AutoML:
The next step is that we execute the Create AutoML Python method to create our job:
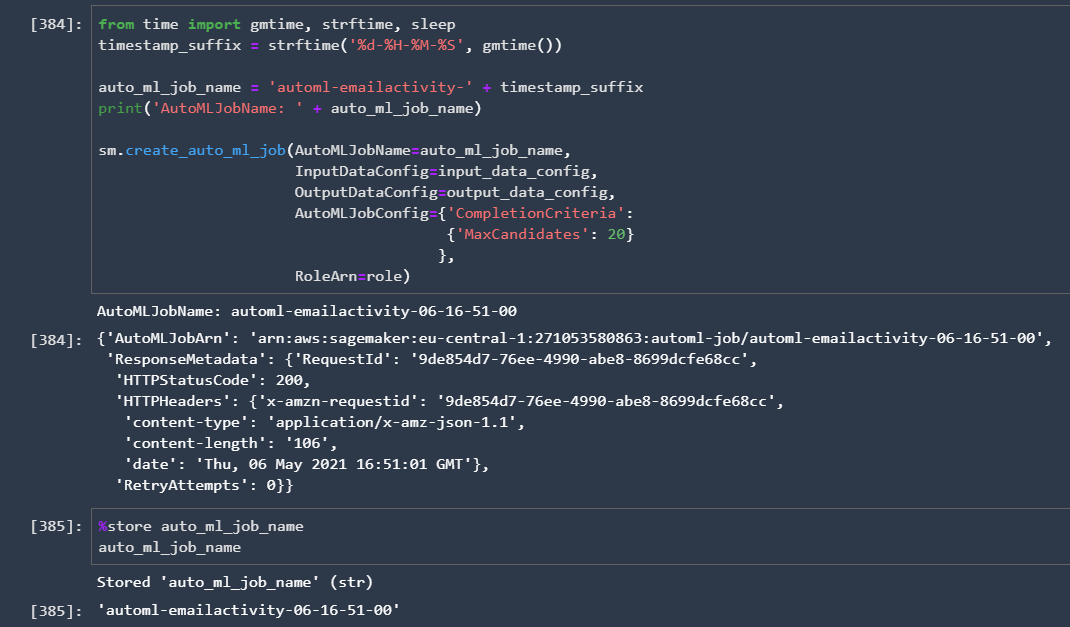
We can then monitor from SageMaker Studio how the AutoML job is created:
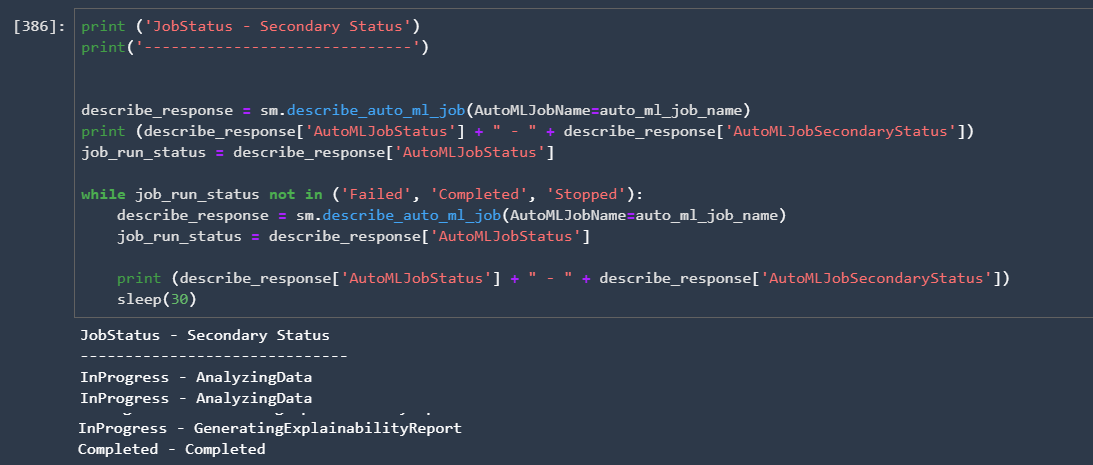
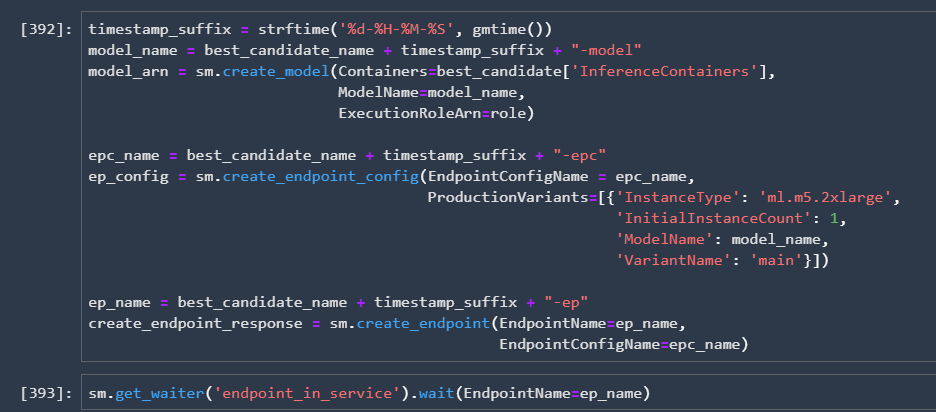
Finally, we can identify the best candidate from the prediction models that AutoML worked out and then we create an endpoint for our predictions that can be invoked from the code or the model can also be used for batch predictions:
We can check the model accuracy by testing the model against the stripped-down version of the test data where we dropped the target label from the data set:
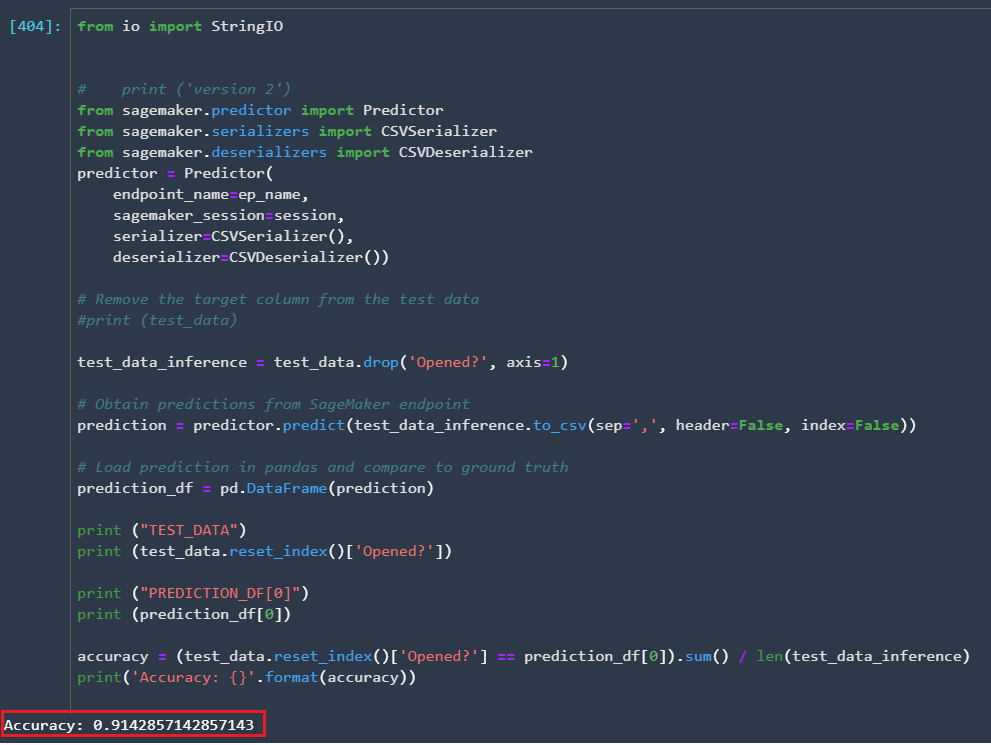
In our test scenario, the accuracy is 0.914 which is a pretty decent model to start with.
Note: the SageMaker screenshots are simplified for the article; the original Jupyter Notebook Python code is stored in GitHub.
Conclusion
This example illustrates how Veeva Nitro, a life science industry-specific data warehouse can be used in conjunction with AWS SageMaker in order to collect Veeva CRM data in an automated, intelligent way, augment it inside the data analytics platform if needed, and then extract it for the AWS data scientist platform in order to come up with valuable insights for the field sales reps so they can know when they should send their approved emails to the healthcare professionals and achieve the highest open rate. Many other use cases can be similarly built on top of these platforms to help pharma companies' digitalization efforts.
Opinions expressed by DZone contributors are their own.
Comments