Using Datafold to Enhance DBT for Data Observability
We’ll look at how Datafold and dbt work in tandem to bring observability and repeatability into your data quality process.
Join the DZone community and get the full member experience.
Join For FreeModern businesses depend on data to make strategic decisions, but today’s enterprises are seeing an exponential increase in the amount of data available to them. Churning through all this data to get meaningful business insights means there’s very little room for data discrepancies. How do we put in place a robust data quality assurance process?
Fortunately for today’s DataOps engineers, tools like Datafold and dbt (Data Build Tool) are simplifying the challenge of ensuring data quality. In this post, we’ll look at how these two tools work in tandem to bring observability and repeatability into your data quality process.
But first, let’s set the context for our data problem.
Manual Data Quality Is No Longer Manageable
Typically, an organization’s data comes from a multitude of sources and in a variety of forms. This data needs to be cleaned, processed, and then transformed into a usable format. These activities are usually handled by ETL (extract, transform, load) or ELT (extract, load, transform) pipelines built around the data. For small datasets, data analysts would manually check the data for discrepancies. With increasingly larger volumes of data, however, data quality checks require automation.
In the past, data engineering was left out of the standardization and process innovation enjoyed by application development. There was no version control for data models or data pipelines, no CI/CD or documentation, and no automated regression testing strategies. In other words, ensuring quality without effective tools was next to impossible.
DataOps sorely needed automated, repeatable, and reliable processes that would bring some predictability into data operations. The ideal tools would automatically profile source data and show its dependencies. DataOps engineers needed to see how a change in the data itself—its structure or the transformation code—would affect the data downstream.
With the recent emergence of stronger and better DataOps tools, we got dbt and Datafold.
Introducing dbt
With the increased power of modern data warehouse engines, ELT processes are being preferred over ETL. ELT depends more on the transformation capabilities of the data warehouse after data has been ingested by it, rather than on independent transformation logic pre-ingestion.
dbt brings sanity to these transformation jobs. It helps represent the transformation logic in its proprietary language, which is very similar to SQL. dbt then compiles that logic to the SQL format of the target data warehouse and runs it there. dbt supports all modern data warehouses, including Google BigQuery, Snowflake, and AWS Redshift.
dbt can help data engineers create reusable SQL code modules that can be accessed from other SQL scripts. This helps code modularization and improves code maintainability. dbt accomplishes this by pairing SQL with a powerful templating framework called Jinja.
Perhaps the strongest feature of dbt is its ability to show the changes that would happen to the data by the transformation logic. dbt does this by representing the transformation jobs as SELECT statements, taking care of other boilerplate activities like generating DDL commands and ensuring version control. It also provides a mechanism to add documentation to the data models.
Another feature of dbt is its ability to facilitate automated testing using custom metrics and scripts to ensure the integrity of the SQL. It can handle testing requirements ranging from simple non-null value assertions to business logic-based assertions.
dbt also helps engineers to better understand raw data sources. It can inform about the freshness of the data, add documentation and metadata to data sources, and keep track of models that depend on various data sources. It maintains snapshots of data at various points, helping data engineers to recreate historical checkpoints of values.
dbt can be accessed via a command-line utility that can be installed on the development machine or through the dbt cloud, which comes with a web-based IDE.
Datafold
Datafold is a data observability platform that proactively helps reduce data quality incidents and data outages. To do this, it combines a few core functionalities.
Datafold’s flagship feature is Data Diff: automated data regression testing integrated seamlessly into the development process. The one-click regression functionality executes a predefined sequence of tests on specific datasets and adds the test report to the code review process. Data Diff compares the new version of the data resulting from a change in code to its original version. It can track schema changes as well as value changes.
The table and column-level lineage tracking feature shows where a particular piece of data comes from—and how it relates to an upstream source or a downstream destination. Data lineage is incredibly helpful for debugging data issues, as it can quickly surface why a piece of data is not what it’s supposed to be. For example, a report may be showing unexpected data for a particular field. Using the column-level lineage for the field, DataOps can check the field’s source and original value, and how that field was transformed through various upstream steps in the data pipeline.
Datafold’s Data Catalog provides a one-stop shop for engineers to explore all the registered organizational datasets. It goes a long way in helping analysts find the right data asset and understand it. Data Catalog profiles data and creates usable metadata about it. This kind of profiling brings immediate visibility to how complete or fresh a dataset might be. In addition, Data Catalog can pull in metadata tags from other sources (like dbt, or even a data warehouse like Snowflake).
Datafold can help monitor data discrepancies by creating custom alerts based on SQL queries. This feature helps data engineers stay proactive so they can preempt and prevent quality incidents or outages. These alerts are powered by ML models to adapt to seasonality, and they can be configured to ensure that only the correct people receive the correct alerts when needed. With alerts in place, data consumers can know early when they might have unavailable or inaccurate data.
Observing data and ensuring its quality is just one part of the challenge. Executing the actual transformation jobs reliably to build the insights is the other part. This is where dbt can help.
How Do Datafold and dbt Work Together?
Now that we’ve covered the basics of both dbt and Datafold, let’s see how they work together.
dbt and Datafold address two different problems in the ELT space. dbt helps formalize the transformation jobs and enables standard software engineering practices like documentation, version control, and continuous integration. Datafold, on the other hand, is focused on reducing data quality incidents by automated regression testing, visualizing data lineage, and providing data alerts.
One area where both dbt and Datafold overlap is in data cataloging. Both dbt and Datafold can capture metadata about the data sources. Datafold goes one step further and can even synchronize metadata from dbt. How dbt and Datafold can work together to solve data quality issues depends on the specific data lifecycle scenario. Let’s consider a typical workflow with dbt.
A Typical dbt Workflow
dbt provides a CLI and a cloud-based IDE. The broad sequence of steps to use dbt is very similar in both cases. The process starts with creating a project in dbt and then connecting to the target data warehouse. Once connected, the project can be initialized using a built-in template. The SQL code to run transformations is stored as .sql files in a directory called models. A YAML file contains the configurations for running the transformations. Data engineers can create more models in the dbt project by adding SELECT statements and saving them as .sql files. dbt takes care of generating DDL statements for the models.
Once the models are developed, they can be committed to a Git repository from the web IDE. In line with the modern software development workflow, once a commit is made to a branch, a pull request is created to initiate deploying the model to production. This pull request can be reviewed by peer developers and then merged into the production pipeline. To define tests and documentation, developers can add tests and documentation to the YAML configuration file. dbt then generates the documentation and lineage by scanning all the entries in the dbt project.
Naturally, the next question is this: How does Datafold fit into this process? Datafold integrates with the continuous integration (CI) configuration of dbt projects in order to help prevent data quality incidents. When integrated with dbt, Datafold synchronizes the metadata information from the .yml files and the .sql files. It builds a complete profile of the data sources based on this information and by connecting directly to the data warehouses. Datafold can then be used in three different ways.
Data Diff
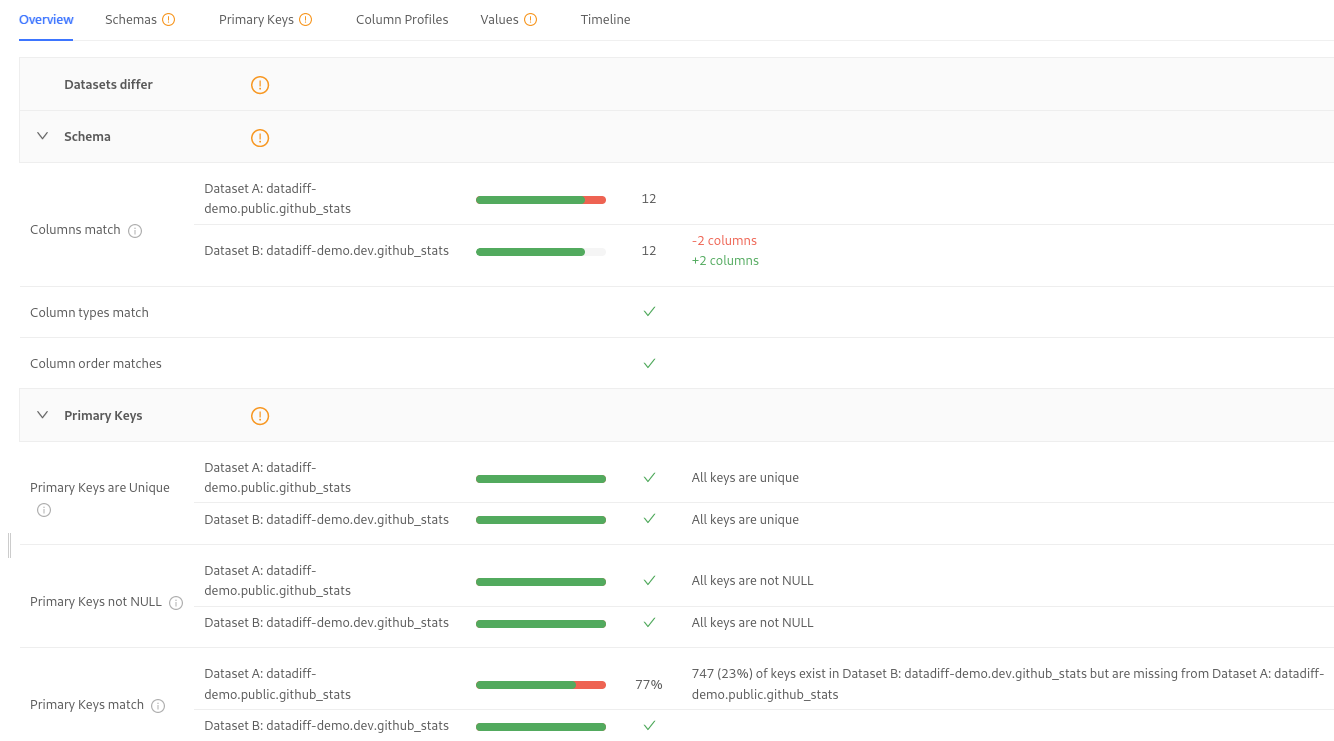
When integrated into the CI pipeline, Datafold can be configured to run Data Diff and attach a report to the pull request. Data Diff runs both the previous model version and the current model version of the code on the test data, and then it calculates diff metrics to help the pull request reviewer make an approval decision.
{kind=link}
Having a report like this attached to a pull request can help the code reviewer be 100% sure about the decision they make to approve (or reject) the code change.
Data Lineage
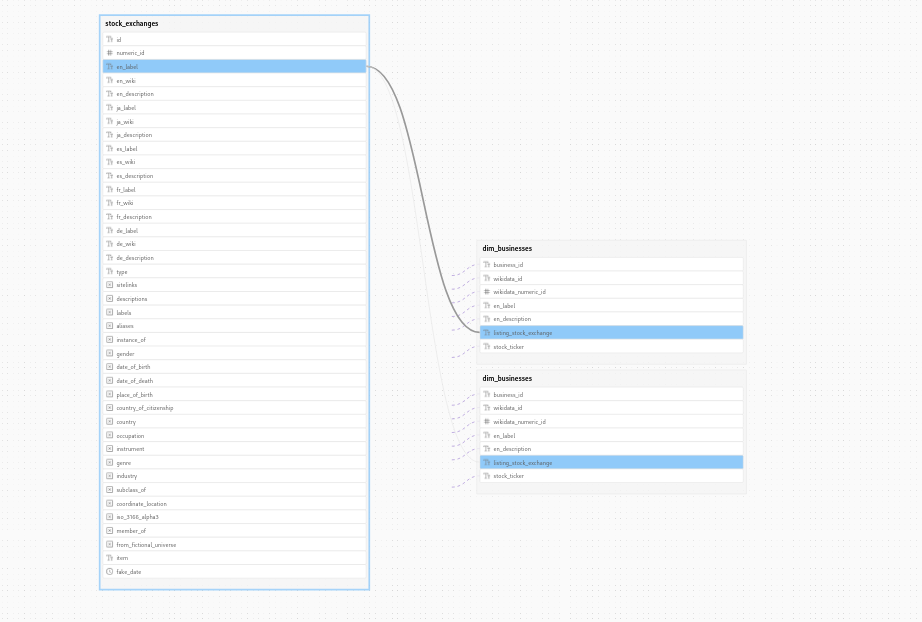
While dbt provides some table-level data lineage information, Datafold provides comprehensive table and column-level lineage in an interactive user interface. This makes it easy to see which data will be impacted by changes to a column’s calculation or even a field’s name or definition.
{kind=link}
Data lineage functionality is an extension of the Data Catalog feature provided by Datafold. Beyond lineage information, Data Catalog provides everything required by the developers to find the right data asset.
Data Monitoring and Alerts
Datafold keeps track of all the pipeline runs by dbt and can run diagnostics on each execution to generate alerts. Simple SQL statements can be specified to enable Datafold to generate these alerts in case unexpected patterns are found in the output. This can help in the early detection of quality incidents. Setting up alerts is as easy as selecting a data source and configuring an SQL statement.
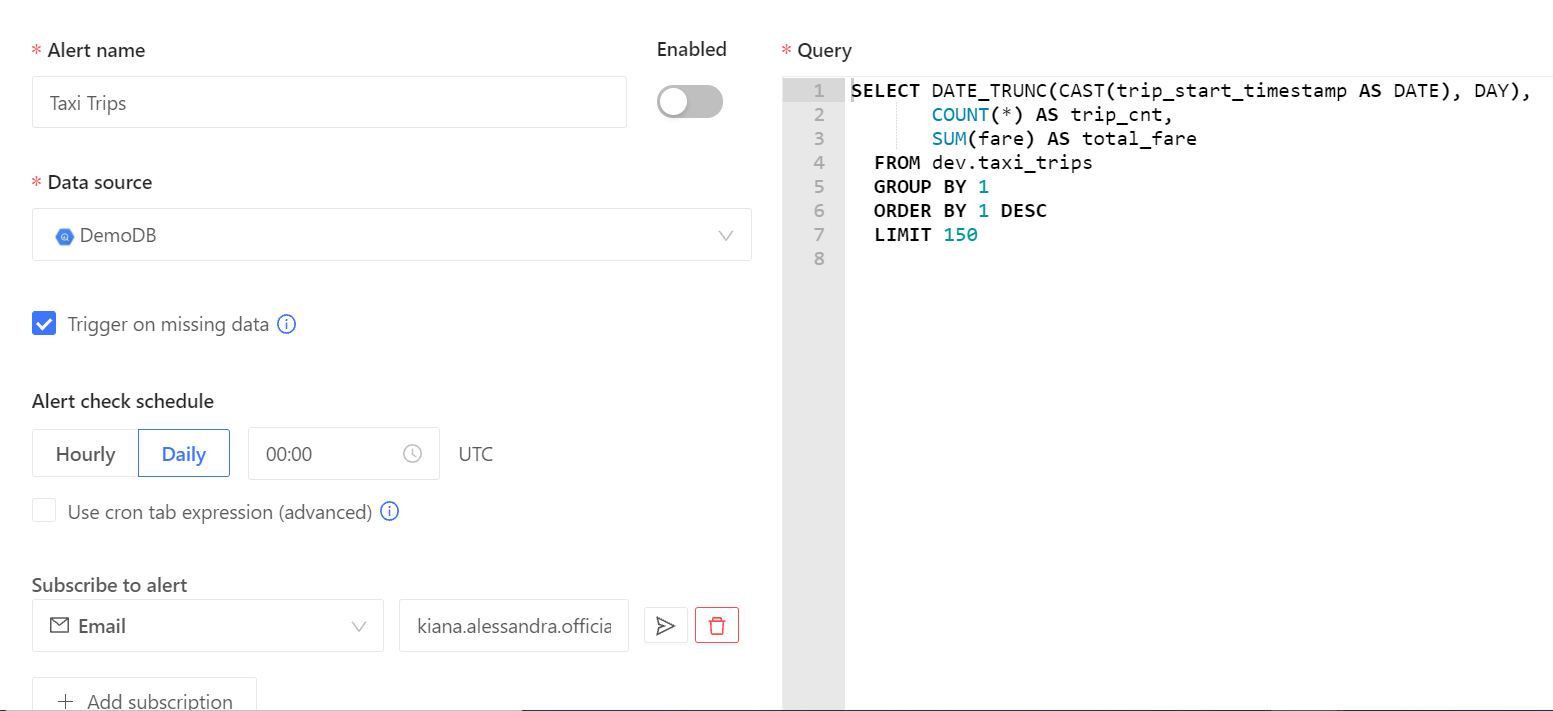
{kind=link}
Even if the developer has not specified any alert conditions, Datafold’s machine learning models are intelligent enough to detect anomalies in the output data and then generate alerts. The models can adapt to the seasonality and trend variations in the data and will construct dynamic thresholds, thereby eliminating unwanted alerts in case of natural variations.
Conclusion
Data in the modern enterprise is evolving constantly, especially as more and more data sources are brought into the mix. It’s not enough for DataOps teams simply to manage data assets; their KPIs increasingly include data quality and reliability for those assets.
This stresses the team’s need for visibility and effective troubleshooting, to ensure data quality amidst any changes made to the existing data. Even the smallest of errors in the source data could harm downstream analytics modules and machine learning models. Because this directly affects an organization’s strategic decision-making process, it’s imperative for data engineering processes to be reliable, repeatable, and understandable—and that’s exactly what today’s DataOps teams get when they combine Datafold with dbt.
Opinions expressed by DZone contributors are their own.
Comments