Time Series Analysis: VARMAX-As-A-Service
VARMAX-As-A-Service is an MLOps approach for the unification and reuse of statistical models and machine learning models deployment pipelines.
Join the DZone community and get the full member experience.
Join For FreeVARMAX-As-A-Service is an MLOps approach for the unification and reuse of statistical models and machine learning models deployment pipelines. It is the first of a series of articles that will be built on top of that project, representing experiments with various statistical and machine learning models, data pipelines implemented using existing DAG tools, and storage services, both cloud-based and alternative on-premises solutions.
But what is VARMAX and statistical models in general and how are they different from machine learning models?
Statistical Models
Statistical models are mathematical models, and so are machine learning models. A statistical model is usually specified as a mathematical relationship between one or more random variables and other non-random variables. As such, a statistical model is "a formal representation of a theory" and belongs to the field of statistical inference. Some statistical models can be used to make predictions using predefined mathematical formulas and estimating coefficients based on historical data. Statistical models explicitly specify a probabilistic model for the data and identify variables that are usually interpretable and of special interest, such as the effects of predictor variables. In addition to identifying relationships between variables, statistical models establish both the scale and significance of the relationship.
Machine Learning Models
Machine learning models can be interpreted as mathematical models, too. ML models can also build predictions based on historical data without explicit programming. However, those models are more empirical. ML usually does not impose relationships between predictors and outcomes nor isolate the effect of any single variable. The relationships between variables might not be understandable, but what we are provided after are predictions.
Now, let us focus on predictions or forecasts applied to time series data. Time series data can be defined as (successive measurements made from the same source over a fixed time interval) using statistical modeling and machine learning. Both are represented by an underlying mathematical model; they need data to be trained/parameterized, and they produce new time series representing foretasted values. Having those similarities, we will apply the approach used to expose machine learning models as services to a statistical model used for time series forecasting called VARMAX.
VARMAX
VARMAX is a statistical model or, generally speaking, a procedure that estimates the model parameters and generates forecasts. Often, economic or financial variables are not only contemporaneously correlated with each other but also correlated with each other’s past values. VARMAX procedure can be used to model these types of time relationships.
This article is based on an application called VARMAX-As-A-Service that can be found on a dedicated GitHub repository. It is comprised of two main components:
- Runtime component — a dockerized deployable REST service
- Preprocessing component — a set of Python functions responsible for data loading, model optimization, model instantiation, and model serialization, enabling its future reuse
The architecture of the runtime component comprising the application is depicted in the following picture:
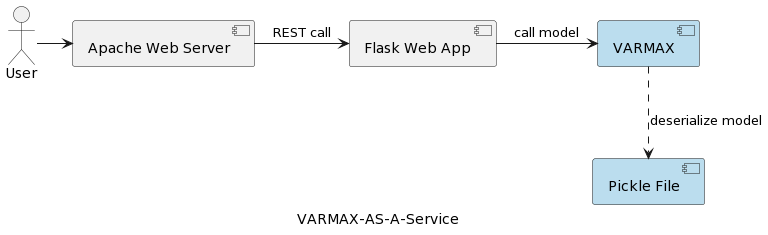
The user sends in a request via a browser to an Apache Web Server hosting the model. Behind the scenes, this is a Python Flask application that is calling a previously configured and serialized pickle file model. Note Pickle is a serialization module in Python's standard library.
Flask is a lightweight WSGI web application framework. It is designed to make getting started quick and easy, with the ability to scale up to complex applications. Flask is a good choice as a framework for the implementation of a web service exposing the statistical model API, and it also provides a web server for testing. However, for deployment in production, we need a web server and gateway interface. The Docker image created in that project is deploying the Flask application using Apache httpd and WSGI (Web Server Gateway Interface) on a Linux-based system. Apache is a powerful and widely-used web server, while WSGI is a standard interface between web servers and Python applications. Apache httpd is a fast, production-level HTTP server. Serving as a “reverse proxy,” it can handle incoming requests, TLS, and other security and performance concerns better than a WSGI server.
The Docker image, as well as the model code, can be found on a dedicated GitHub repository.
REST services can be easily integrated into existing web applications as part of an algorithm or as a step in a DAG of a prediction data pipeline (see Apache Airflow, Apache Beam, AWS Step Functions, Azure ML Pipeline). The integration as a part of the pipeline will be the focus of an upcoming article while this one exposes the service as Swagger documented endpoint and Swagger UI for testing and experimenting with various input datasets.
After deploying the project, the Swagger API is accessible via <host>:<port>/apidocs (e.g., 127.0.0.1:80/apidocs). There are two endpoints implemented, using the user's input parameters and sending an input file:
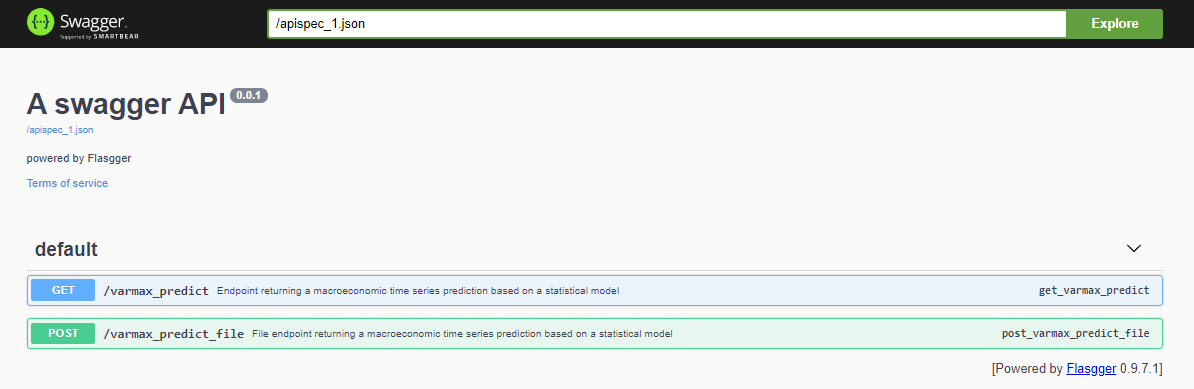
Internally, the service uses the deserialized model pickle file:

Requests are sent to the initialized model as follows:

Prior to the implementation of the REST service and its deployment, the actual model needs to be prepared. In the picture below, the step needed to prepare the model for deployment is called a preprocessing step. It should not be confused with the term data processing from data analysts. In the example project, the data set used to optimize the model parameters is called United States Macroeconomic data and is provided by the Python library statsmodels without the need to apply additional data processing. The preprocessing algorithm is comprised of the following steps:
- Load data
- Divide data into train and test data set
- Prepare exogenous variables
- Find optimal model parameters (p, q)
- Instantiate the model with the optimal parameters identified
- Serialize the instantiated model to a pickle file
And finally, the steps needed to run the application are:
- Execute model preparation algorithm: python varmax_model.py
- Deploy application: docker-compose up -d
- Test model:
http://127.0.0.1:80/apidocs
The presented project is a simplified workflow that can be extended step by step with additional functionalities like:
- Store model files in a remote repository (e.g., Relational Database, MinIO Service, S3 Storage)
- Explore standard serialization formats and replace the pickle with an alternative solution
- Integrate time series data visualization tools like Kibana or Apache Superset
- Store time series data in a time series database like Prometheus, TimescaleDB, InfluxDB
- Extend the pipeline with data loading and data preprocessing steps
- Track model versions
- Incorporate metric reports as part of the
- Implement pipelines using specific tools like Apache Airflow or AWS Step Functions or more standard tools like Gitlab or GitHub
- Compare statistical models' performance and accuracy with machine learning models
- Implement end-to-end cloud-integrated solutions, including Infrastructure-As-Code
- Expose other statistical and ML models as services
Some of these future improvements will be the focus of the next articles and projects. The goal of this article is to build the basic project structure and a simple processing workflow that can be extended and improved over time. However, it represents an end-to-end infrastructural solution that can be deployed on production and improved as part of a CI/CD process over time.
Opinions expressed by DZone contributors are their own.
Comments