Time Synchronization in Distributed Systems: TiDB's Timestamp Oracle
This article is an introduction to PingCAP's TiDB’s timestamp oracle (TSO), how it delivers time services, and its strengths and weaknesses.
Join the DZone community and get the full member experience.
Join For FreeToday, distributed databases lead the market, but time synchronization in distributed systems remains a hard nut to crack. Due to the clock skew, the time in different nodes of a distributed database cannot be synchronized perfectly. Many computer scientists have proposed solutions such as the logic clock by Leslie Lamport (the 2013 Turing Award winner), the hybrid logical clock, and TrueTime.
PingCAP’s TiDB, an open-source distributed NewSQL database, adopts timestamp oracle (TSO) to deliver the time service and uses a centralized control service — Placement Driver (PD) — to allocate the monotonically increasing timestamps.
In this post, I will introduce TiDB’s TSO, how it delivers time services, and its strengths and downsides.
TiDB’s Architecture
Before we go deep into TiDB’s time services, let’s review TiDB’s architecture.
TiDB is an open-source distributed database with horizontal scalability, strong consistency, and high availability. It consists of multiple components, including the PD cluster, TiDB cluster, storage cluster, and TiSpark. These components communicate with each other and form a complete TiDB system.

TiDB cluster | TiKV | TiFlash | TiSpark | Apache Spark
PD is “the brain” of the entire TiDB database and also the focus of our topic today. It has three major tasks. It:
- Stores and manages the metadata of the entire TiDB system in real-time
- Schedules and balances workloads on TiKV and TiFlash nodes in real-time
- Delivers time services
TiDB’s PD Cluster and TSO
The PD cluster usually consists of multiple PD instances (three instances in most cases), and the PD Leader among those instances delivers external services. An etcd store is embedded in the PD cluster to guarantee PD’s availability and improve its ability to store metadata.
If the PD Leader crashes, a new Leader will be elected automatically to ensure the availability of the time services. The etcd Leader shares the same PD instance with the PD Leader, so during the Leader election, etcd Leader will take precedence over the PD Leader. The election process is as follows:
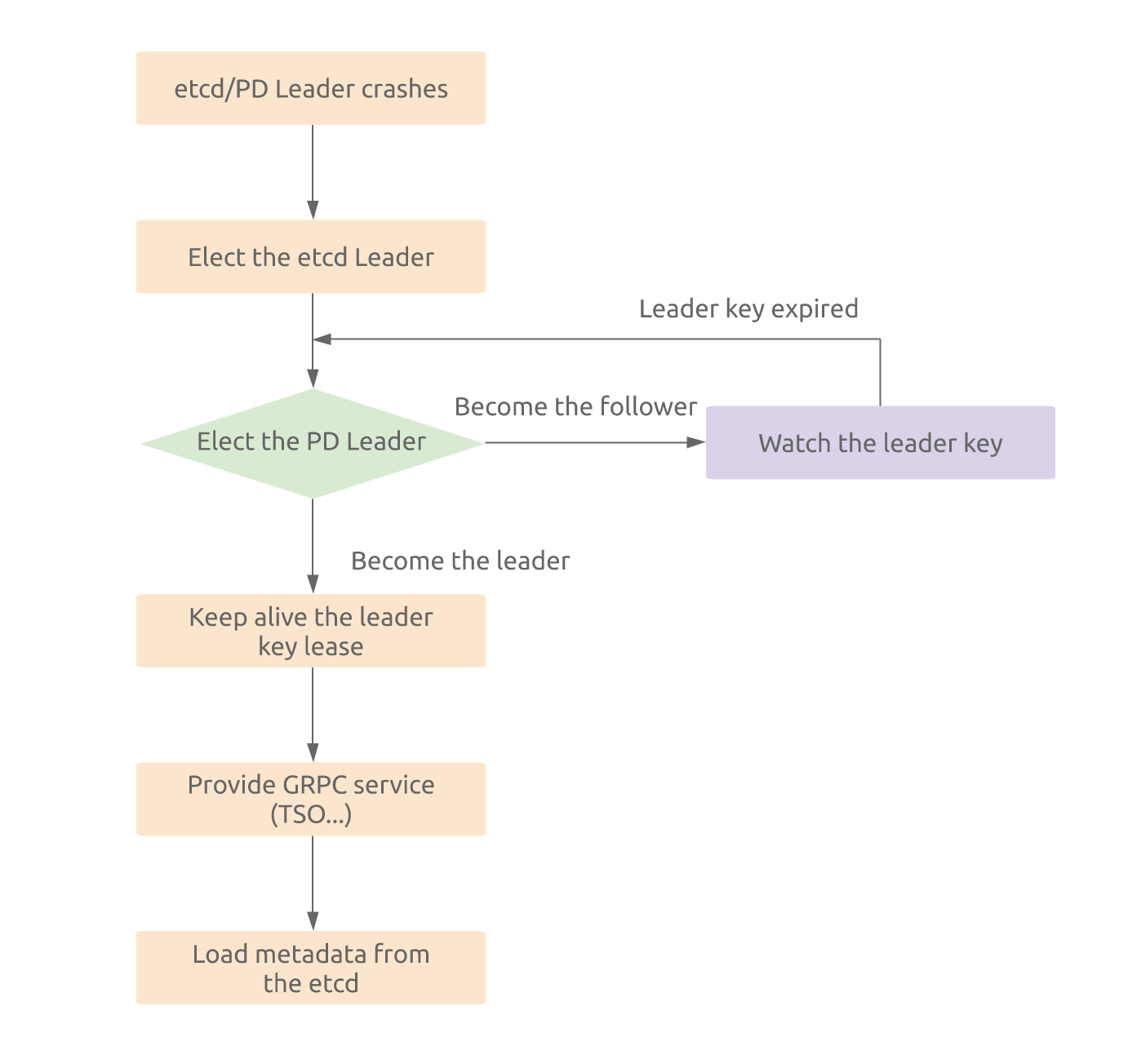
TiDB’s TSO uses a centralized hybrid logical clock to deliver time services. It uses 64 bits to represent a time interval. The lower 18 bits represent the logical clock, and the remaining 46 bits represent the physical clock. Since its logical clock has an 18-bit structure, a total of 2^18 * 1,000 or 262,144,000 timestamps can be generated and allocated per second.
Next, I will introduce how TSO in the PD server comes into play. This section will describe how PD calibrates, delivers, and fast-forwards the time.
Calibrate the Time
When a new PD leader is elected, it does not know the current system time. So its top priority is to calibrate the time.
First, the newly elected PD Leader reads the time stored in the etcd by the previous PD Leader. The stored time is called TLAST, which is the maximum value of the physical time applied by the previous PD Leader. After reading TLAST, the new PD Leader knows that the timestamps allocated by the previous Leader are smaller than TLAST.
Then, the new PD Leader compares TLAST and TNOW, the local physical time:
- If TNOW – TLAST < 1 ms, the current physical time TNEXT = TLAST + 1;
- Otherwise, TNEXT = TNOW.
After the new PD Leader finishes these steps, the time calibration is done.
Deliver the Time
After it finishes the time calibration, the new PD Leader starts to deliver TSO services. To ensure that the next elected PD Leader can successfully calibrate the time after the current PD Leader is down, the current PD leader should store TLAST in the etcd every time after it delivers the time services. But, if the PD Leader did so every time, PD’s performance would be greatly undermined. Therefore, to avoid such problems, the PD Leader pre-applies for an assignable time window, Tx. Its default value is 3.
It first stores TLAST, which is equal to TNEXT + Tx, in the etcd, and then allocates all timestamps during the time period [TNEXT, TNEXT + Tx) in memory.
Preallocation fixes the problem of loss of PD performance caused by frequent operations in the etcd store. However, the flaw is that if the PD Leader crashes, many pre-allocated timestamps would be wasted.
When the client side requests a TSO service, a 64-bit hybrid logical timestamp is returned. Its physical time value is the calibrated TLAST, and its logical clock value increments atomically with the request. If its logical clock value exceeds its maximum value (1 << 18), it sleeps for 50 ms to wait for the physical time to be fast-forwarded. After the physical time fast-forwards, if there are still timestamps to be allocated, the PD Leader continues to allocate them.
TSO service requests are cross-network, so to lower the network bandwidth consumption, TiDB’s PD server supports batch requests of TSO services.
Fast-Forward the Time
During the time services, PD can only allocate timestamps through the increment of the logical time. When the incremented value reaches its top limit, timestamps cannot be allocated anymore, and the physical time needs to be fast-forwarded.
PD checks the current physical time every 50 ms and then fast-forwards the time. According to the equation JetLag = TNOW – TLAST if JetLag > 1 ms, the physical time in the hybrid logical clock is slower than the current physical time and needs to be fast-forwarded to make TNEXT = TNOW.
In addition, when the logical clock reaches its threshold value during the time services, it stops and waits. So, to prevent this situation from happening, when the current logical clock exceeds half of its threshold value, the physical clock inside the hybrid logical clock will be advanced as well. Once this is done, the value of the logical clock will be reset to 0.
When TLAST – TNEXT <= 1 ms, it means that the previously applied time window has been used up, and the next time window needs to be applied. So, the PD Leader stores TLAST (which is equal to TNEXT + Tx) into the etcd and continues to allocate timestamps during the new time window.
Pros and Cons of TSO
TiDB adopts TSO, a centralized clock solution, which is essentially a hybrid logic clock as well. As the centralized clock delivers single-point time services, all the events are ordered. It is also pretty simple to implement. It also has the following downsides; fortunately, most of them have a corresponding solution:
- Loss of performance when delivering time services across regions. To solve this problem, the PD cluster can be deployed in the same region.
- Single-point failure. To fix this problem, the etcd is embedded in the PD cluster, and the Raft consensus algorithm is used to make the time service highly available and consistent.
- Possible performance bottlenecks. Because the TSO services are delivered by the PD Leader only, technically there could be performance bottlenecks in the future. Fortunately, the PD Leader can generate 260 million timestamps per second and has undergone many optimizations. As of yet, I haven’t seen a performance bottleneck.
Opinions expressed by DZone contributors are their own.
Comments