Why Use LocalPV with NVMe for Your Workload?
Join the DZone community and get the full member experience.
Join For FreeContainerized applications are ephemeral, which means any data created by a container is lost as soon as the process terminates. This requires a pragmatic approach to data persistence and management when orchestrating containers using Kubernetes. To deal with this, the Kubernetes orchestration platform uses Volume plugins to isolate storage consumption from provisioned hardware.
A Persistent Volume (PV) is a Kubernetes API resource that provisions persistent storage for PODs. Cluster resources can use a PV construct to mount any storage unit -- file system folders or block storage options -- to Kubernetes nodes. PODs request for a PV using Persistent Volumes Claims (PVC). These storage integrations and other features make it possible for containerized applications to share data with other containers and preserve the container state.
PVs can be provisioned statically by the cluster administrator or dynamically using Storage Classes. Some important features that distinguish different Storage Classes include Capacity, Volume Mode, Access Modes, Performance and Resiliency. When a Local Disk is attached directly to a single Kubernetes node, it is known as a Local PV which provides the best performance and is only accessible from a single node where it is attached. This post explores why LocalPV and NVMe storage should be used for Kubernetes workloads.
Non-Volatile Memory Express (NVMe) for Kubernetes
NVMe is a high-speed access protocol that delivers low latency and high throughput for SSD storage devices by connecting them to the processor through a PCIe interface. Early SSDs connected to the CPU through SATA or Serial Attached SCSi (SAS). These relied on legacy standards customized for Hard Disk speeds which were considered inefficient since each connection to the processor remained limited by synchronized locking or the SAS Host Bus Adapter (HBA).
To overcome this challenge, NVMe unlocks the true potential of flash storage using the Peripheral Component Interconnect Express (PCIe) that supports high performance, Non-Uniform Memory Access (NUMA). NVMe also supports parallel processing, with 64K Input-Output queues with each queue having 64K entries. This high-bandwidth, low-latency storage hosts applications that can create as many I/O queues as system configuration, workload and the NVMe controller allows.
Following a NUMA based storage protocol, NVMe allows different CPUs to manage I/O queues, using various arbitration mechanisms. Modern enterprises are data-driven, with users and devices generating huge amounts of data that may overwhelm companies. By enhancing the capabilities of multi-core CPUs, NVMe provides low latency and fast transfer rates for better access and processing of large data sets. NVMe devices typically rely on NAND Flash Memory that can be hosted on various SSD form factors including normal SSDs, U2 Cards, M2 Cards, and PCIe Add-In Cards.
NVMe over Fabrics (NVMe-oF) extends the advantages of NVMe storage access by implementing the NVMe protocol for remotely connected devices. The architecture allows one node to directly access a storage device of another computer over several transport protocols.
NVMe Architecture
In NVMe architecture, the host computer is connected to SSD storage devices via a high throughput Host-Controller Interface. The storage service is composed of three main elements:
- SSD Controllers
- The PCIe Host Interface
- Non-Volatile Memory (e.g., NAND Flash)
To submit queues to the Input/Output, the NVMe controller utilizes Memory-Mapped Controller Registers and the host system’s DRAM. The number of mapped registers determines the number of parallel I/O operations the protocol can support.
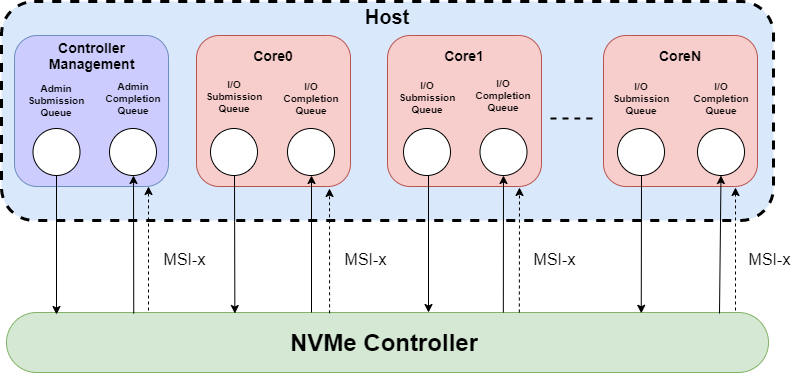
A typical NVMe storage architecture
Advantages of Using NVMe for Kubernetes Clusters
PCIe reduces the need for various abstract implementation layers, allowing for faster, efficient storage. Some benefits of using NVMe for storage include:
- Efficient memory transfer - NVMe protocol only requires one ring per CPU to communicate directly with Non-Volatile Memory, thereby reducing locking speeds for I/O controllers. NVMe also enables parallelism by combining the number of Message Signalled Interrupts with multi-core CPUs to further reduce latency.
- Secured Cluster Data - NVMe-oF enables secure tunnelling protocols developed and managed by reputable data security communities such as the Trusted Security Group (TSG). This enables enterprise-grade security features such as Encryption at REST, Access Control and Crypto-Erase for cluster nodes and SSD storage devices.
- Supports Multi-Core Computing - The NVMe protocol utilizes a private queueing strategy to support up to 64K commands per queue over 64K queues. Since every controller has its own set of queues, the throughput increases linearly with the number of CPU cores available.
- Requires Fewer Instructions to Process I/O requests - NVMe relies on an efficient set of commands to half the number of CPU instructions required to implement Input-Output operations. This reduces latency while enabling advanced security features like reservations and power management for cluster administrators.
Why use LocalPV with NVMe Storage for Kubernetes Clusters?
While most storage systems used to persist data for Kubernetes clusters are remote and independent of the source nodes, it is possible to attach a local disk directly to a single node. Locally attached storage typically guarantees higher performance and tighter security than remote storage.
A Kubernetes LocalPV represents a portion of local disk storage that can be used for data persistence in StatefulSets. With LocalPV, the local disk is specified as a persistent volume that can be consumed with the same PVC and Storage Class abstractions used for remote storage. This results in low latency storage that is suitable for fault-tolerant use-cases such as:
- Distributed data stores that share replicated data across multiple nodes
- LocalPV can also be used to cache data sets that require faster processing over data gravity
LocalPV vs. hostPath Volumes
Before the introduction of LocalPV volumes, hostPath volumes were used for accessing local storage. There were certain challenges while orchestrating local storage with hostPath as it didn’t support important Kubernetes features, such as StatefulSets. Additionally, hostPath volumes required separate operators for disk management, POD scheduling and topology, making them difficult to use in production environments.
LocalPV volumes were designed in response to issues with the scheduling, disk accounting and portability of hostPath volumes. One of the major distinctions is that the Kubernetes control plane knows the Node that owns a LocalPV. With hostPath, data is lost when a POD referencing the volume is scheduled to a different node. LocalPV volumes can only be referenced using a Persistent Volume Claim (PVC) while hostPath volumes can be referenced both directly in the POD definition file and via PVC.
How to Configure a Kubernetes Cluster with LocalPV NVMe Storage
Workloads can be configured to access NVMe SSDs on a local machine using LocalPV and a Persistent Volume Claim, or StatefulSet with volume claim attributes. This section explores how to attach a local disk to a Kubernetes cluster with NVMe storage configured.
- The first step is to create a storage class that enables Volume Topology-Aware Scheduling. This will instruct the Kubernetes API to not bind a PVC until a Pod consuming the PVC is scheduled. The configuration file for the storage class will be similar to:
$ cat sc.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: openebs-device-sc
allowVolumeExpansion: true
parameters:
devname: "test-device"
provisioner: device.csi.openebs.io
volumeBindingMode: WaitForFirstConsumerCheck the doc on storageclasses to know all the supported parameters for Device LocalPV.
- If the device with a meta partition is available on certain nodes only, then make use of topology to tell the list of nodes where we have the devices available. As shown in the below storage class, we can use
allowedTopologiesto describe device availability on nodes.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: openebs-device-sc
allowVolumeExpansion: true
parameters:
devname: "test-device"
provisioner: device.csi.openebs.io
allowedTopologies:
- matchLabelExpressions:
- key: kubernetes.io/hostname
values:
- device-node1
- device-node2The above storage class tells that device with meta partition test-device is available on nodes device-node1 and device-node2 only. The Device CSI driver will create volumes on those nodes only.
- The OpenEBS Device driver has its own scheduler which will try to distribute the PV across the nodes so that one node should not be loaded with all the volumes. Currently, the driver supports two scheduling algorithms:
VolumeWeightedandCapacityWeighted, in which it will try to find a device which has lesser number of volumes provisioned in it or less capacity of volume provisioned out of a device respectively, from all the nodes where the devices are available. To know about how to select a scheduler via storage-class, refer this link. Once it is able to find the node, it will create a PV for that node and also create aDeviceVolumecustom resource for the volume with the node information. The watcher for this DeviceVolume CR will get all the information for this object and create a partition with the given size on the mentioned node.
The scheduling algorithm currently only accounts for either the number of volumes or total capacity occupied from a device and does not account for other factors like available cpu or memory while making scheduling decisions. So if you want to use node selector/affinity rules on the application pod, or have cpu/memory constraints, a Kubernetes scheduler should be used. To make use of kubernetes scheduler, you can set the volumeBindingMode as WaitForFirstConsumer in the storage class. This will cause a delayed binding, i.e Kubernetes scheduler will schedule the application pod first, and then it will ask the Device driver to create the PV. The driver will then create the PV on the node where the pod is scheduled.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: openebs-device-sc
allowVolumeExpansion: true
parameters:
devname: "test-device"
provisioner: device.csi.openebs.io
volumeBindingMode: WaitForFirstConsumerPlease note that once a PV is created for a node, the application using that PV will always get scheduled to that particular node only, as PV will be sticky to that node. The scheduling algorithm by Device driver or kubernetes will come into picture only during the deployment time. Once the PV is created, the application can not move anywhere as the data is there on the node where the PV is.
- Create a PVC using the storage class created for the device driver.
$ cat pvc.yaml
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: csi-devicepv
spec:
storageClassName: openebs-device-sc
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 4Gi- Create the deployment YAML using the PVC backed by device driver storage.
$ cat fio.yaml
apiVersion: v1
kind: Pod
metadata:
name: fio
spec:
restartPolicy: Never
containers:
- name: perfrunner
image: openebs/tests-fio
command: ["/bin/bash"]
args: ["-c", "while true ;do sleep 50; done"]
volumeMounts:
- mountPath: /datadir
name: fio-vol
tty: true
volumes:
- name: fio-vol
persistentVolumeClaim:
claimName: csi-devicepvAfter the deployment of the application, we can go to the node and see that the partition is created and is being used as a volume by the application for reading/writing the data.
Advantages of Using LocalPV with NVMe for Kubernetes Operators
Some benefits of integrating LocalPV into clusters using NVMe for storage include:
- Compared to remotely connected storage systems, Local Persistent Volumes support more Input-Output Operations Per Second (IOPS) and throughput since the volume directory is directly mounted on the node. This means that with LocalPV Volumes, organizations can hone in on the high performance offered by NVMe SSDs.
- LocalPV also enables the dynamic reservation of storage resources needed for stateful services. This makes it easy to relaunch a process on the same node using the same SSD volume.
- LocalPV volume configuration pins tasks to the nodes where their data resides, eliminating the need for scheduling constraints, thereby enabling quicker access of SSDs through NVMe.
- Destroying a LocalPV is as easy as deleting the PVC consuming it, allowing for simpler storage management.
Summary
Non-Volatile Memory Express (NVMe) enhances data storage and access by leveraging the performance benefits of flash memory for SSD based storage. By connecting storage devices to the CPU directly via the PCIe interface, data companies eliminate the bottlenecks associated with SATA or SAS based access. LocalPV reduces the data path between storage and Kubernetes nodes by mounting a volume directly on a Kubernetes node. This results in higher throughput and IOPS, suitable for fault-tolerant stateful applications.
OpenEBS by MayaData is one of the popular open-source, agile storage stacks for performance-sensitive databases orchestrated by Kubernetes. Mayastor, OpenEBS’s latest storage engine, delivers very low overhead versus the performance capabilities of underlying devices.. OpenEBS Mayastor does not require NVMe devices or that workloads consume NVMe, although in both cases performance will increase. OpenEBS Mayastor is unique currently amongst open source storage projects in utilizing NVMe internally, to communicate to options OpenEBS replicas. To learn more about how OpenEBS Mayastor, leveraging NVMe as a protocol, performs when leveraging some of the fastest NVMe devices currently available on the market, visit this article.
OpenEBS Mayastor builds a foundational layer that enables workloads to coalesce and control storage as needed in a declarative, Kubernetes-native way. While doing so, the user can focus on what's important, that is, deploying and operating stateful workloads.
If you’re interested in trying out Mayastor for yourself, instructions for how to set up your own cluster, and run a benchmark like `fio` may be found at https://docs.openebs.io/docs/next/mayastor.html.
Related Blogs:
https://blog.mayadata.io/the-benefits-of-using-nvme-for-kubernetes
https://blog.mayadata.io/mayastor-nvme-of-tcp-performance
Opinions expressed by DZone contributors are their own.
Comments