Internal Architecture of the SQLite Database
Explore the internal architecture of the SQLite database.
Join the DZone community and get the full member experience.
Join For FreeIn a computer program, the database is the heart of handling data and provides a fast and efficient way of storing and retrieving data. Learning the database's internal architecture and looking into a fully featured database at the code level is not so easy because of the database's complexity. But SQLite is a nice little compact database that is used in millions of devices and operating systems. An interesting fact about the SQLite database is that its code base is highly readable. Most of the code is well commented, and the overall software architecture is highly layered. My previous article describes the backend implementation of the SQLite Database, while this article looks into how the SQLite compiler and the VM work at a high level.
As I mentioned earlier, SQLite has a highly layered architecture that can be separated into seven layers. We will go through each of the layers one-by-one.

Tokenizer
The first layer is called the tokenizer. The purpose of the tokenizer is to create tokens for a given SQL query. The tokenizer scans the SQL query from left to right and generates a list of tokens. The following are some of the types of tokens used in the SQL tokenizer.
- Operator tokensare used to tokenize arithmetic operators in SQL queries. Here are some of the example sets of operator tokens:
- "-" as token MINUS
- "(" as token LP
- "+" as token PLUS
- Keyword tokens are used to tokenize the keywords used in SQL queries. ADD, SELECT, ROW, and INSERT are examples of keyword tokens.
- Whitespace tokens are used to separate other tokens. Here, comments are also identified as white space tokens.
Parser
A parser is used to generate a parse tree by reading a stream of tokens. SQLite uses Lemon parser to parse SQL queries. Lemon parser allows SQLite C compiler to generate relevant C code from given sets of language rules. Language rules are defined by using Context Free Grammer (CFG). An example parser tree for the following SQL statement is shown below.
SELECT title FROM StartsIn, MovieStar WHERE starName="Jack" AND birthday like "%1990"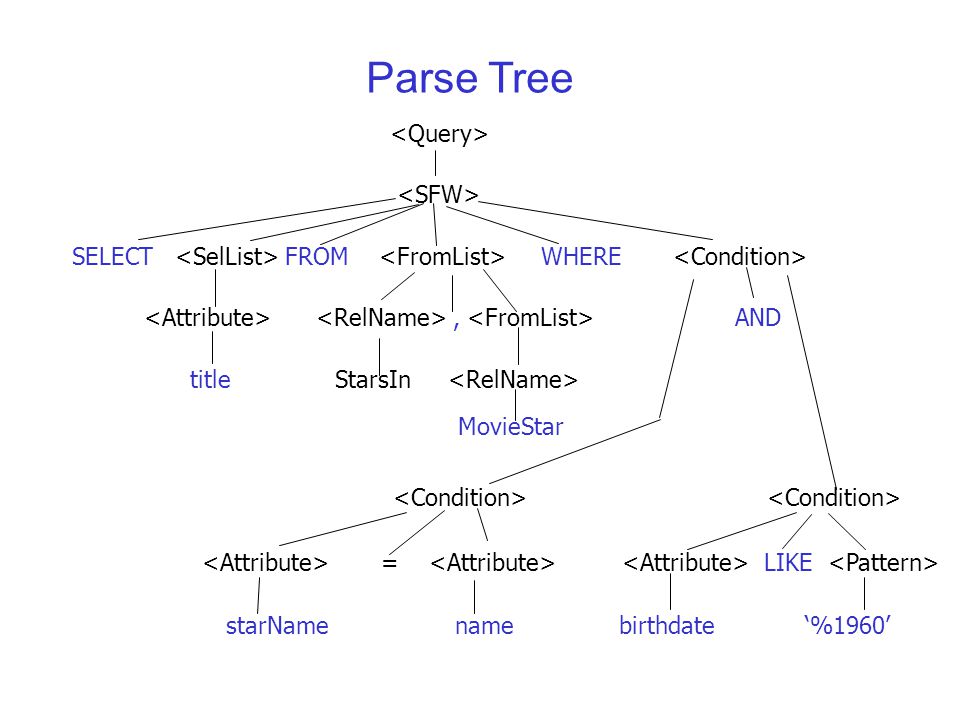
In the below example, CFG rules generate a program to evaluate a simple mathematical expression.
program ::= expr(A). { std::cout << "Result=" << A << std::endl; }
expr(A) ::= expr(B) MINUS expr(C). { A = B - C; }
expr(A) ::= expr(B) PLUS expr(C). { A = B + C; }
expr(A) ::= expr(B) TIMES expr(C). { A = B * C; }
expr(A) ::= expr(B) DIVIDE expr(C). {
if(C != 0){
A = B / C;
}else{
std::cout << "divide by zero" << std::endl;
}
} /* end of DIVIDE */
expr(A) ::= INTEGER(B). { A = B; }Here MINUS, PLUS, TIMES, and DIVIDE are the operator tokens generated by the tokenizer. In this code, lines number 3 to 6 are defined by the CFG for mathematical operation. The lemon parser takes the precedence of these to operate the same as the given order. Think the given expression to evaluate is "3+5*6/3". The tokenized output will be:
3 PLUSE 5 TIMES 6 DIVIDE 3
According to the precedence, the lemon parser evaluates line #6 first and evaluates 6/3. Then, it evaluates the TIMES operation in line #5, and the result would be 10. Finally, it evaluates line #4 and generates the final result as 13. This result will be printed in line #1, which has the least precedence.
All of the SQL rules are defined in the same kind of structure as I described in the previous example.
Code Generator and Virtual Machine
While SQL query parsing, SQLite generates a sequence of instructions that need to run in order to generate the result. Each of these instructions has some operation and input to perform. It is the same as calling to a function with arguments. These generated codes are running on top of the virtual machine. The virtual machine reads each of these instructions one-by-one and evaluates it. To understand what the available operations are and how the virtual machine works, we need to have a good understanding of Btree.
Btree
Btree is a data structure used to store data as a tree based on its value. The simplest form of the BTree is the Binary tree. Databases use a B-tree data structure to store indexes to improve the performance of the database. Data records are stored in a B+tree structure. If no indexing is used, only B+tree is used to store the data. A cursor is a special pointer that is used to point a record (or row), which is given with the page ID and offset. You can travel through all the data records by using the cursor. To find the data in the given Btree, which used indexing, SQLite starts to move the cursor to the root node first element and performs a B-tree search. If there is no Btree indexing available, SQLite searches the matching record in the B+tree by using linear search. You can find out more details about Btree in this article.
To search for data on a B+tree, the sequence of operations is generated by the Code Generator as follows. You can check the sequence of instructions that need to run for a particular SQL query by adding "explain" keyword at the beginning of the query.
explain select * from foo where value = "value";
|ColumnCount |1 |0 |
|ColumnName |0 |0 |value
|Open |0 |3 |foo // Open cursor and point it to the third page which is root page for foo table(p3 is not important )
|VerifyCookie |46|0 | // Make sure schema not changed
|Rewind |0 |11| // Go to first entry
|Column |0 |0 | // read data and push it on stack
|Column |0 |0 |
|Ne |1 |10| //Pop the top two elements from the stack. If they are not equal, then jump to instruction P2. Otherwise, continue to the next instruction.
|Callback |1 |0 | // Pop P1 values off the stack and form them into an array
|Next |0 |5 | // Move cursor to next record, if data exit goto P2 else go to next line
|Close |0 |0 | // Close the cursorPager
Pages are the smallest unit of a transaction on the file system. Btree and B+tree are stored on the page. When the database needs to read data from a file, it requests it as a page. Once the page is loaded into the database engine, it can store the page if it accesses it frequently on its cache. Pages are numbered and start from one. The first page is called the root page. The size of the page is constant.
VFS (Virtual File System)
File access on Unix and Windows are different from each other. VFS provides a common API to access files without considering the type of operating system it runs on. This API includes functions to open, read, write, and close a file. Some of the API is used in VFS to read and write data into a file. You can find out more about Pager and VFS in this blog post.
Conclusion
In this post, I tried to explain the SQLite database implementation at a high level. If you are interested in knowing more about the internal architecture of SQLite, I'd love to share my knowledge with you. Comment below if there are any improvements that need to be made or if you need any clarifications. Also, here is my backend implementation that was used to understand the SQLite architecture. In this repository, I tried to separate each of the layers in SQLite and write some tests for each of the layers. You can find the SQLite 2.5 source code that was used to implement this project here.
Opinions expressed by DZone contributors are their own.
Comments