The Guide to SRE Principles
This article covers key principles that underlie SRE, provides some examples of those key principles, and includes relevant details and illustrations to clarify these examples.
Join the DZone community and get the full member experience.
Join For FreeSite reliability engineering (SRE) is a discipline in which automated software systems are built to manage the development operations (DevOps) of a product or service. In other words, SRE automates the functions of an operations team via software systems.
The main purpose of SRE is to encourage the deployment and proper maintenance of large-scale systems. In particular, site reliability engineers are responsible for ensuring that a given system’s behavior consistently meets business requirements for performance and availability.
Furthermore, whereas traditional operations teams and development teams often have opposing incentives, site reliability engineers are able to align incentives so that both feature development and reliability are promoted simultaneously.
Basic SRE Principles
This article covers key principles that underlie SRE, provides some examples of those key principles, and includes relevant details and illustrations to clarify these examples.
| Principle | Description | Example |
|---|---|---|
| Embrace risk | No system can be expected to have perfect performance. It’s important to identify potential failure points and create mitigation plans. Additionally, it’s important to budget a certain percentage of business costs to address these failures in real time. | A week consists of 168 hours of potential availability. The business sets an expectation of 165 hours of uptime per week to account for both planned maintenance and unplanned failures. |
| Set service level objectives (SLOs) | Set reasonable expectations for system performance to ensure that customers and internal stakeholders understand how the system is supposed to perform at various levels. Remember that no system can be expected to have perfect performance. |
|
| Eliminate work through automation | Automate as many tasks and processes as possible. Engineers should focus on developing new features and enhancing existing systems at least as often as addressing real-time failures. | Production code automatically generates alerts whenever an SLO is violated. The automated alerts send tickets to the appropriate incident response team with relevant playbooks to take action. |
| Monitor systems | Use tools, to monitor system performance. Observe performance, incidents, and trends. |
|
| Keep things simple | Release frequent, small changes that can be easily reverted to minimize production bugs. Delete unnecessary code instead of keeping it for potential future use. The more code and systems that are introduced, the more complexity created; it’s important to prevent accidental bloat. | Changes in code are always pushed via a version control system that tracks code writers, approvers, and previous states. |
| Outline the release engineering process | Document your established processes for development, testing, automation, deployments, and production support. Ensure that the process is accessible and visible. | A published playbook lists the steps to address reboot failure. The playbook contains references to relevant SLOs, dashboards, previous tickets, sections of the codebase, and contact information for the incident response team. |
Embrace Risk
No system can be expected to have perfect performance. It’s important to create reasonable expectations about system performance for both internal stakeholders and external users.
Key Metrics
For services that are directly user-facing, such as static websites and streaming, two common and important ways to measure performance are time availability and aggregate availability.
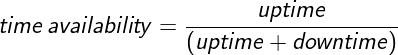
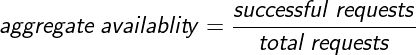
This article provides an example of calculating time availability for a service.
For other services, additional factors are important, including speed (latency), accuracy (correctness), and volume (throughput).
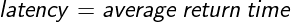
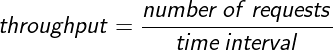
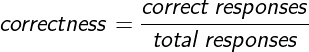
An example calculation for latency is as follows:
- Suppose 10 different users serve up identical HTTP requests to your website, and they are all served properly.
- The return times are monitored and recorded as follows: 1 ms, 3 ms, 3 ms, 4 ms, 1 ms, 1 ms, 1 ms, 5 ms, 3 ms, and 2 ms.
- The average response time, or latency, is 24 ms / 10 returns = 2.4 ms.
Choosing key metrics makes explicit how the performance of a service is evaluated, and therefore what factors pose a risk to service health. In the above example, identifying latency as a key metric indicates average return time as an essential property of the service. Thus, a risk to the reliability of the service is “slowness” or low latency.
Define Failure
In addition to measuring risks, it’s important to clearly define which risks the system can tolerate without compromising quality and which risks must be addressed to ensure quality.
This article provides an example of two types of measurements that address failure: mean time to failure (MTTF) and mean time between failures (MTBF).
The most robust way to define failures is to set SLOs, monitor your services for violations in SLOs, and create alerts and processes for fixing violations. These are discussed in the following sections.
Error Budgets
The development of new production features always introduces new potential risks and failures; aiming for a 100% risk-free service is unrealistic. The way to align the competing incentives of pushing development and maintaining reliability is through error budgets.
An error budget provides a clear metric that allows a certain proportion of failure from new releases in a given planning cycle. If the number or length of failures exceeds the error budget, no new releases may occur until a new planning period begins.
The following is an example error budget.
| Planning cycle | Quarter |
| Total possible availability | 2,190 hours |
| SLO | 99.9% time availability |
| Error budget | 0.1% time availability = 21.9 hours |
Suppose the development team plans to release 10 new features during the quarter, and the following occurs:
- The first feature doesn’t cause any downtime.
- The second feature causes downtime of 10 hours until fixed.
- The third and fourth features each cause downtime of 6 hours until fixed.
- At this point, the error budget for the quarter has been exceeded (10 + 6 + 6 = 22 > 21.9), so the fifth feature cannot be released.
In this way, the error budget has ensured an acceptable feature release velocity while not compromising reliability or degrading user experience.
Set Service Level Objectives (SLOs)
The best way to set performance expectations is to set specific targets for different system risks. These targets are called service level objectives, or SLOs. The following table lists examples of SLOs based on different risk measurements.
| Time availability | Website running 99% of the time |
| Aggregate availability | 99% of user requests processed |
| Latency | 1 ms average response rate per request |
| Throughput | 10,000 requests handled every second |
| Correctness | 99% of database reads accurate |
Depending on the service, some SLOs may be more complicated than just a single number. For example, a database may exhibit 99.9% correctness on reads but have the 0.1% of errors it incurs always be related to the most recent data. If a customer relies heavily on data recorded in the past 24 hours, then the service is not reliable. In this case, it makes sense to create a tiered SLObased on the customer’s needs. Here is an example:
| Level 1 (records within the last 24 hours) | 99.99% read accuracy |
| Level 2 (records within the last 7 days) | 99.9% read accuracy |
| Level 3 (records within the last 30 days) | 99% read accuracy |
| Level 4 (records within the last 6 months) | 95% read accuracy |
Costs of Improvement
One of the main purposes of establishing SLOs is to track how reliability affects revenue. Revisiting the sample error budget from the section above, suppose there is a projected service revenue of $500,000 for the quarter. This can be used to translate the SLO and error budget into real dollars. Thus, SLOs are also a way to measure objectives that are indirectly related to system performance.
| SLO | Error Budget | Revenue Lost |
|---|---|---|
| 95% | 5% | $25,000 |
| 99% | 1% | $5,000 |
| 99.90% | 0.10% | $500 |
| 99.99% | 0.01% | $50 |
Using SLOs to track indirect metrics, such as revenue, allows one to assess the cost of improving service. In this case, spending $10,000 on improving the SLO from 95% to 99% is a worthwhile business decision. On the other hand, spending $10,000 on improving the SLO from 99% to 99.9% is not.
Eliminate Work Through Automation
One characteristic that distinguishes SREs from traditional DevOps is the ability to scale up the scope of a service without scaling the cost of the service. Called sublinear growth, this is accomplished via automation.
In a traditional development-operations split, the development team pushes new features, while the operations team dedicates 100% of its time to maintenance. Thus, a pure operations team will need to grow 1:1 with the size and scope of the service it is maintaining: If it takes O(10) system engineers to serve 1000 users, it will take O(100) engineers to serve 10K users.

In contrast, an SRE team operating according to best practices will devote at least 50% of its time to developing systems that remove the basic elements of effort from the operations workload. Some examples of this include the following:
- A service that detects which machines in a large fleet need software updates and schedules software reboots in batches over regular time intervals.
- A “push-on-green” module that provides an automatic workflow for the testing and release of new code to relevant services.
- An alerting system that automates ticket generation and notifies incident response teams.
Monitor Systems
To maintain reliability, it is imperative to monitor the relevant analytics for a service and use monitoring to detect SLO violations. As mentioned earlier, some important metrics include:
- The amount of time that a service is up and running (time availability)
- The number of requests that complete successfully (aggregate availability)
- The amount of time it takes to serve a request (latency)
- The proportion of responses that deliver expected results (correctness)
- The volume of requests that a system is currently handling (throughput)
- The percentage of available resources being consumed (saturation)
Sometimes durability is also measured, which is the length of time that data is stored with accuracy.
Dashboards
A good way to implement monitoring is through dashboards. An effective dashboard will display SLOs, include the error budget, and present the different risk metrics relevant to the SLO.

Logs
Another good way to implement monitoring is through logs. Logs that are both searchable in time and categorized via request are the most effective. If an SLO violation is detected via a dashboard, a more detailed picture can be created by viewing the logs generated during the affected timeframe.

Whitebox Versus Blackbox
The type of monitoring discussed above that tracks the internal analytics of a service is called whitebox monitoring. Sometimes it’s also important to monitor the behavior of a system from the “outside,” which means testing the workflow of a service from the point of view of an external user; this is called blackbox monitoring. Blackbox monitoring may reveal problems with access permissions or redundancy.
Automated Alerts and Ticketing
One of the best ways for SREs to reduce effort is to use automation during monitoring for alerts and ticketing. The SRE process is much more efficient than a traditional operations process.
A traditional operations response may look like this:
- A web developer pushes a new update to an algorithm that serves ads to users.
- The developer notices that the latest push is reducing website traffic due to an unknown cause and manually files a ticket about reduced traffic with the web operations team.
- A system engineer on the web operations team receives a ticket about the reduced traffic issue. After troubleshooting, the issue is diagnosed as a latency issue caused by a stuck cache.
- The web operations engineer contacts a member of the database team for help. The database team looks into the codebase and identifies a fix for the cache settings so that data is refreshed more quickly and latency is decreased.
- The database team updates the cache refresh settings, pushes the fix to production, and closes the ticket.
In contrast, an SRE operations response may look like this:
- The ads SRE team creates a deployment tool that monitors three different traffic SLOs: availability, latency, and throughput.
- A web developer is ready to push a new update to an algorithm that serves ads, for which he uses the SRE deployment tool.
- Within minutes, the deployment tool detects reduced website traffic. It identifies a latency SLO violation and creates an alert.
- The on-call site reliability engineer receives the alert, which contains a proposal for updated cache refresh settings to make processing requests faster.
- The site reliability engineer accepts the proposed changes, pushes the new settings to production, and closes the ticket.
By using an automated system for alerting and proposing changes to the database, the communication required, the number of people involved, and the time to resolution are all reduced.
The following code block is a generic language implementation of latency and throughput thresholds and automated alerts triggered upon detected violations.
# Define the latency SLO threshold in seconds and create a histogram to track
LATENCY_SLO_THRESHOLD = 0.1
REQUEST_LATENCY = Histogram('http_request_latency_seconds', 'Request latency in seconds', ['method', 'endpoint'])
# Define the throughput SLO threshold in requests per second and a counter to track
THROUGHPUT_SLO_THRESHOLD = 10000
REQUEST_COUNT = Counter('http_request_count', 'Request count', ['method', 'endpoint', 'http_status'])
# Check if the latency SLO is violated and send an alert if it is
def check_latency_slo():
latency = REQUEST_LATENCY.observe(0.1).observe(0.2).observe(0.3).observe(0.4).observe(0.5).observe(0.6).observe(0.7).observe(0.8).observe(0.9).observe(1.0)
quantiles = latency.quantiles(0.99)
latency_99th_percentile = quantiles[0]
if latency_99th_percentile > LATENCY_SLO_THRESHOLD:
printf("Latency SLO violated! 99th percentile response time is {latency_99th_percentile} seconds.")
# Check if the throughput SLO is violated and send an alert if it is
def check_throughput_slo():
request_count = REQUEST_COUNT.count()
current_throughput = request_count / time.time()
if current_throughput > THROUGHPUT_SLO_THRESHOLD:
printf("Throughput SLO violated! Current throughput is {current_throughput} requests per second.")
Example of automated alert calls
Keep Things Simple
The best way to ensure that systems remain reliable is to keep them simple. SRE teams should be hesitant to add new code, preferring instead to modify and delete code where possible. Every additional API, library, and function that one adds to production software increases dependencies in ways that are difficult to track, introducing new points of failure.
Site reliability engineers should aim to keep their code modular. That is, each function in an API should serve only one purpose, as should each API in a larger stack. This type of organization makes dependencies more transparent and also makes diagnosing errors easier.
Playbooks
As part of incident management, playbooks for typical on-call investigations and solutions should be authored and published publicly. Playbooks for a particular scenario should describe the incident (and possible variations), list the associated SLOs, reference appropriate monitoring tools and codebases, offer proposed solutions, and catalog previous approaches.
Outline the Release Engineering Process
Just as an SRE codebase should emphasize simplicity, so should an SRE release process. Simplicity is encouraged through a couple of principles:
- Smaller size and higher velocity: Rather than large, infrequent releases, aim for a higher frequency of smaller ones. This allows the team to observe changes in system behavior incrementally and reduces the potential for large system failures.
- Self-service: An SRE team should completely own its release process, which should be automated effectively. This both eliminates work and encourages small-size, high-velocity pushes.
- Hermetic builds: The process for building a new release should be hermetic, or self-contained. That is to say, the build process must be locked to known versions of existing tools (e.g., compilers) and not be dependent on external tools.
Version Control
All code releases should be submitted within a version control system to allow for easy reversions in the event of erroneous, redundant, or ineffective code.
Code Reviews
The process of submitting releases should be accompanied by a clear and visible code review process. Basic changes may not require approval, whereas more complicated or impactful changes will require approval from other site reliability engineers or technical leads.
Recap of SRE Principles
The main principles of SRE are embracing risk, setting SLOs, eliminating work via automation, monitoring systems, keeping things simple, and outlining the release engineering process.
Embracing risk involves clearly defining failure and setting error budgets. The best way to do this is by creating and enforcing SLOs, which track system performance directly and also help identify the potential costs of system improvement. The appropriate SLO depends on how risk is measured and the needs of the customer. Enforcing SLOs requires monitoring, usually through dashboards and logs.
Site reliability engineers focus on project work, in addition to development operations, which allows for services to expand in scope and scale while maintaining low costs. This is called sublinear growth and is achieved through automating repetitive tasks. Monitoring that automates alerting creates a streamlined operations process, which increases reliability.
Site reliability engineers should keep systems simple by reducing the amount of code written, encouraging modular development, and publishing playbooks with standard operating procedures. SRE release processes should be hermetic and push small, frequent changes using version control and code reviews.
Published at DZone with permission of Vishal Padghan. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments