The Great Data Mesh Debate: Will It Sink or Swim?
Let's explore the intricacies of Data Mesh, address the great debate around its obsolescence and explore the opportunities and challenges it presents.
Join the DZone community and get the full member experience.
Join For FreeData Mesh has been gaining attention in the industry as a new approach to managing data. However, amidst the excitement, there are concerns about its complexities and whether it can deliver on its promises. In this article, we will dive into the intricacies of Data Mesh, address the great debate around its obsolescence and explore the opportunities and challenges it presents. We will also discuss what the industry might be missing and the potential roadblocks that could hinder its successful implementation.
Data Mesh: A Paradigm for Democratized and Scalable Data Architecture
So, what does the prominently used term "data mesh" mean, and why should one consider implementing one?
Akin to how software engineering teams transitioned from monolithic applications to microservice architectures, the data mesh represents the data platform equivalent of microservices. Drawing inspiration from Eric Evans' domain-driven design theory, which advocates for flexible and scalable software development aligning with specific business domains, the data mesh offers a comparable approach.
Unlike traditional monolithic data infrastructures, which handle data consumption, storage, transformation, and output in a centralized data lake, a data mesh supports distributed, domain-specific data consumers. It treats "data-as-a-product," with each domain responsible for managing its own data pipelines.
Crucially, according to data mesh principles, the domain teams assume ownership of the underlying platform or data storage layer, which has sparked some controversy. These domains are connected through a universal interoperability layer, adhering to consistent syntax and data standards. While some infrastructure duplication may occur, certain teams have embraced a more centralized platform, resulting in hybrid "data meshy" structures.
In the era of self-service business intelligence, it’s cringeworthy that many enterprises proclaim themselves as data-first organizations. However, not all of them prioritize the democratization and scalability of their data architecture to the extent it deserves.
Great companies recognize the transformative potential of data. Say, for instance, perhaps a CEO within an enterprise became an early adopter of technologies like Snowflake and Looker, or a Chief Data Officer (CDO) led initiatives to educate teams on data management best practices, while a Chief Technology Officer (CTO) invested in a dedicated data engineering group. Nonetheless, the entire data team yearns for a simpler way to address the growing demands of your organization, from handling continuous ad hoc queries to managing diverse data sources through a centralized Extract, Transform, Load (ETL) pipeline.
Underlying this quest for democratization and scalability is the realization that your current data architecture, often limited to a siloed data warehouse or a data lake with limited real-time streaming capabilities, may not be sufficient to meet your evolving needs.
Fortunately, there is a solution that can provide a fresh perspective on data management — the data mesh, an architectural paradigm making waves across the industry.
It's worth noting that data mesh is often confused with the term "data fabric," introduced by a Forrester analyst around the turn of the millennium. A data fabric encompasses various heterogeneous solutions comprising a modern data platform linked by a virtual management layer. However, it does not emphasize decentralization and domain-driven architecture to the same extent as the data mesh.
The Demise of Data Mesh: Hype or Reality?
In the realm of social media discussions, there is already speculation about the demise of data mesh. Coined by Zhamak Dehghani, the former principal consultant at ThoughtWorks, in 2019, data mesh presents a novel approach to managing analytical data through a distributed architecture. By enabling end-users to directly access and query data in its original location, data mesh eliminates the need for centralization in data lakes or warehouses. Under this paradigm, data is treated as a product, with ownership vested in the teams most closely involved in its consumption and understanding.
The concept was introduced to address the challenges organizations face relying on centralized data platform architectures, offering a solution to scale, and owning the delivery of data products by timely decision-making and democratizing data for everyone. Data mesh tackles issues related to data availability and accessibility at scale, granting business users and data scientists the ability to extract, analyze, and operationalize valuable insights from diverse data sources, regardless of their location. It does so without requiring constant intervention from specialized data teams.
Although data mesh is a relatively recent concept, discussions surrounding its demise have already gained traction. Let’s delve into the reasons behind this growing skepticism.
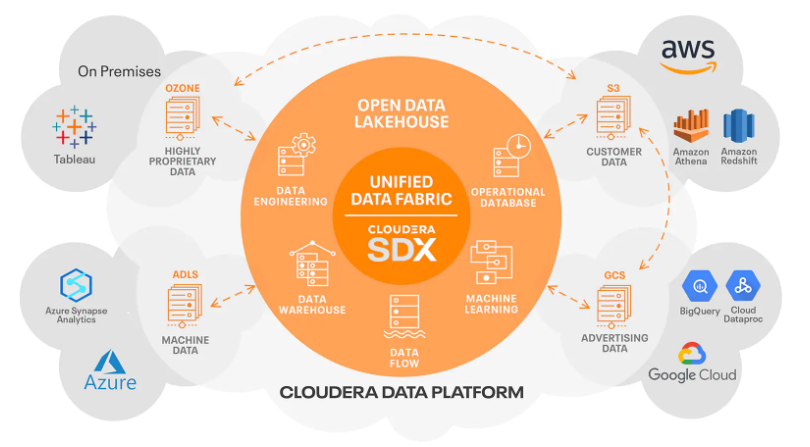
Cloudera Data Platform facilitates a data mesh architecture with key principles viz. Domain Ownership, Data-as-a-product, self-service platform, and federated governance.
The Complexity of Data Mesh: Moving Beyond Technical Aspects
Data Mesh is not just about technical aspects; it encompasses core principles of data management. It involves managing data by domain, treating data as a product, enabling self-service data platforms, and implementing federated computational governance. These pillars form the foundation of Data Mesh and shape its overall value proposition.
- Domain-oriented data owners and pipelines: In a data mesh architecture, data ownership is federated among domain data owners who are responsible for providing their data as products. This approach enables communication and collaboration between distributed data across different locations.
While the data infrastructure is responsible for providing each domain with the necessary solutions to process data, the domains themselves manage the ingestion, cleaning, and aggregation of data to generate assets usable by business intelligence applications. Each domain owns its own Extract, Transform, Load (ETL) pipelines, while a set of capabilities applicable to all domains handles storage, cataloging, and access controls for the raw data. Once data is served to and transformed by a specific domain, the domain owners can leverage it for their analytics or operational requirements. Data lineage plays a crucial role in understanding consumption patterns across the organization and supporting the transition toward a more decentralized structure.
- Self-serve functionality: Data meshes utilize principles of domain-oriented design to provide a self-serve data platform, allowing users to abstract technical complexity and focus on their specific data use cases. The data mesh centralizes domain-agnostic data infrastructure capabilities into a shared platform to address concerns about duplicating efforts and skills required to maintain data pipelines and infrastructure in each domain. This central platform handles data pipeline engines, storage, and streaming infrastructure. Meanwhile, each domain leverages these components to run customized ETL pipelines, providing the necessary support to serve their data while maintaining autonomy over the process.
- Interoperability and standardization of communications: At the core of each domain is a universal set of data standards that facilitate collaboration between domains when needed. As certain data, both raw sources and cleaned, transformed, and served datasets, becomes valuable to multiple domains, cross-domain collaboration is essential. The data mesh achieves this by standardizing formatting, governance, discoverability, and metadata fields, among other data features. Additionally, similar to individual microservices, each data domain defines and agrees upon Service Level Agreements (SLAs) and quality measures that they guarantee to their consumers.
- Domain-oriented data governance: A domain-oriented data governance approach is implemented in the data mesh architecture to ensure compliance with global and regulatory constraints and policies. This approach utilizes a federated service to safeguard data and systems across the organization.
The federated governance model allows for the enforcement of data protection measures while accommodating the unique requirements of each domain. It ensures that data and systems are protected according to applicable regulations and policies, providing a framework for managing data privacy, security, and compliance at the domain level.
By implementing federated governance, the data mesh architecture promotes a structured and coordinated approach to data governance, enabling effective management of data assets while maintaining compliance with relevant regulations and policies.
The Concerns With Domain Ownership
One of the key concerns with Data Mesh lies in the idea of domain ownership. While it may seem appealing to have individual business areas own and manage their data, it raises questions about potential silos and fragmentation. The concept of domains may lead to an incomplete view of data when dealing with enterprise-wide data governance or master data management. The balance between empowering domain owners and ensuring data collaboration across domains is a challenge that needs to be addressed.
The Elusive Parameters of Data Mesh
A significant challenge in understanding Data Mesh is the need for specific guidelines and parameters. The language used around Data Mesh often revolves around new ways of thinking and treating data differently. While concepts like federated data stores and data virtualization are mentioned, there is a lack of clear implementation guidance. This ambiguity makes it difficult for organizations to bridge the gap between theory and practice when adopting Data Mesh.
The Reality Behind the "Dead" Narrative
In June 2022, Gartner released the Hype Cycle Data Management 2022, which assesses the maturity of technologies based on adoption levels and projected mainstream adoption timelines. This cycle helps data and analytics leaders identify promising technologies and determine the right time for evaluation and adoption.
According to the Hype Cycle Data Management 2022, data mesh is currently in the "innovation trigger" stage and has not yet reached the "peak of inflated expectations." However, it is predicted to become "obsolete before the plateau."
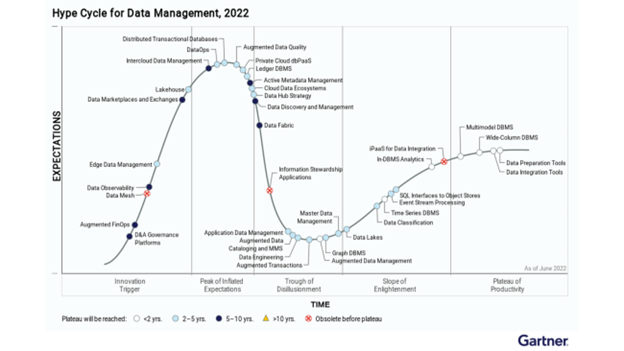
Gartner analysts Mark Beyer, Ehtisham Zaidi, and Robert Thanaraj quantified the perceived benefits of data mesh as low and noted that its market penetration among the target audience is also relatively low, ranging between 1 to 5 percent. The hype surrounding data mesh arises from claims that it addresses challenges in centralized data warehouses, data lakes, and data hubs.
Why Does This Happen?
Gartner explains that data mesh solutions utilize business applications to capture and distribute data in a decentralized manner. Typically, a decentralized data management approach is pursued when a centralized approach fails to deliver satisfactory results, often due to implementation and delivery challenges. However, with the advancement of technologies and solutions supporting centralized data access, distributed approaches like data mesh are anticipated to lose popularity within enterprise IT.
Following the publication of the report, industry experts expressed both support and opposition to Gartner's observations. Scott Hirleman, the host of Data Mesh Radio, criticized Gartner for its perceived bias towards vendors and technology, asserting that data mesh is unlikely to become obsolete.
Malcolm Hawker, former Gartner analyst and current head of data strategy at Profisee, defended Gartner's observation. He clarified that Gartner does not believe data mesh is currently obsolete, but rather, the chart indicates future obsolescence. Hawker expressed Gartner's belief that the data fabric will emerge as the dominant data management architectural pattern, eventually rendering data mesh obsolete.
Data Mesh and the Merging of Core Principles With Technology
The industry is grappling with the question of how to merge the core principles and theories of Data Mesh with the practical aspects of technology and processes. While the idea of treating data as a product and embracing domain-centric ownership is appealing, the actual implementation and standardization present significant challenges. Organizations must find a balance between adopting the principles of Data Mesh and ensuring they have the right tools, technologies, and processes to support it effectively.
Learning From Past Mistakes
Data Mesh is one of many attempts at decentralizing data management. Previous experiences, such as the transition from centralized data warehousing to domain-focused approaches, have faced challenges. It is essential to learn from past mistakes and evaluate whether advancements in technology and increased understanding can overcome the hurdles faced previously.
The Need for Clarity and Hard Questions
To ensure the success of Data Mesh, clarity is required regarding its principles, governance models, and the handling of cross-functional data. Hard questions need to be addressed, such as how to handle critical data domains like customer or product, which cut across multiple domains. With satisfactory answers to these questions, the practicality and effectiveness of Data Mesh may be confident.
The Role of Observability in Overcoming Data Mesh Challenges
The data mesh architecture concept brings exciting opportunities and concerns to the data industry. Some individuals and organizations worry about the potential risks associated with increased autonomy and democratization in data mesh, particularly regarding data discovery, health, and management.
However, a closer examination reveals that data mesh architecture actually addresses these concerns by mandating scalable and self-serve data observability. Data observability becomes crucial for domains to own their data within the data mesh framework truly. This self-serve capability encompasses various functionalities and standardizations, including data encryption for both at-rest and in-motion data, versioning of data products, data product schemas, data product discovery and catalog registration, data governance and standardization, data lineage for production, monitoring, and alerting of data products, logging of data products, and metrics to measure data product quality.
When combined, these capabilities and standardizations establish a robust layer of observability. The data mesh paradigm emphasizes the importance of a standardized and scalable approach for individual domains to handle data observability, enabling teams to address critical questions such as data freshness, data integrity, tracking schema changes, and understanding the dependencies of pipelines both upstream and downstream.
Looking ahead, data mesh continues to gain momentum, with Zhamak Dehghani, the creator of data mesh, making waves in the data industry by announcing her new startup, nextdata. This startup aims to empower data developers, users, and owners by providing a delightful experience with built-in trust in data products.
As the data mesh trend evolves, organizations must find a balance between implementing a fully decentralized data mesh approach and incorporating elements of a center of excellence in their architectures. To explore further insights and perspectives into data mesh, one can delve into brainy resources from Zhamak Dehghani, the book "Data Mesh in Action" by Sven Balnojan, "The Data Mesh: Re-Thinking Data Integration" by Kevin Petrie, and "Should Your Application Consider Data Mesh Connectivity?" by Joe Gleinser.
Conclusion
Data Mesh presents an intriguing concept for data management, but it faces significant challenges before it can truly take hold. The industry needs to address domain ownership concerns, define more precise parameters, and find ways to merge core principles with technology. By learning from past experiences and asking hard questions, organizations can navigate the complexities of Data Mesh and determine its viability in their data management strategies.
Opinions expressed by DZone contributors are their own.
Comments