The Design of a Distributed Rule Engine Framework
MirAIe rule engine is an extensible and scalable rule engine framework that allows users to group and automate multiple activities.
Join the DZone community and get the full member experience.
Join For FreeOver the past few years, while working on the MirAIe IoT platform, we realized the need for an extensible and scalable rule engine framework. A rule engine enables you to group, manage and automate various actions and is used in a variety of applications such as home automation, fraud detection, risk management, and workflow automation. At Panasonic, we are engaged in several initiatives in the fields of mobility, industry 4.0, building management, and home automation. The framework must therefore be adaptable to be used with a variety of applications. In this article, I'll describe a high-level design of our rule engine framework.
Anatomy of a Rule
A rule essentially allows users to group and automate numerous tasks. Examples of user-generated rules include turning on your bedroom air conditioner whenever the room temperature rises above 27 degrees, turning on a cluster of lights in an office lobby every evening at 6, notifying you when the efficiency of a machine in assembly lines drops below 80 percent, or sending out a push notification to your electric car when it’s battery level drops below 30%, and a charging station with an open slot is found nearby.

Figure 1 Anatomy of a Rule
A rule has a trigger condition that specifies when the rule should be activated. The trigger may depend on the user’s location, the condition of a sensor, a specific instant in time, external weather conditions, or any other factors. Several triggers may be coupled using one or more logical operators, which together specify the trigger condition for a rule.
A rule also has one or more actions that are activated when these trigger conditions are met. An action might be as straightforward as turning on a light or as complex as creating a report and sending it to several users as an attachment.
Design Considerations
Rule trigger conditions may depend on multiple input sources. The data source could be internal, like a sensor installed in the laboratory that sends out a periodic status every few seconds, or external, like weather data, which needs to be retrieved and stored once daily because the data doesn’t change frequently. The challenge is assimilating multiple input sources to create a single value and determining whether a rule should be activated.
Due to the wide range of applications our framework must enable, we decided to focus on two fundamental design principles. The first principle is that the architecture must be extensible to support a wide variety of input triggers and output actions. For home automation use cases, the most common triggers could be dependent on time, device status, or outside weather conditions. Whereas for our Smart Factory use cases, a trigger could be user activity or aggregate data collected over time, such as machine efficiency. The idea is to ensure that new trigger types can be added without much change in the architecture. Likewise, rule actions are also extensible. Common actions could be to call an API, send out a notification, or create a task and push it to the task queue.
Our second guiding principle for this design is to prioritize flexibility, allowing for the independent scaling of each component. A flexible system can be adapted to changing demands without the need to scale the entire system resulting in improved resilience and cost efficiency. For example, if a large number of rules need to be triggered at the evening of 6 pm, the system should only scale up the timer trigger service and the rule execution service appropriately, while the other services should continue to work at their original scale. By offering such flexibility, the system can meet varying needs efficiently and effectively.
Rule Engine Components
To enable extensibility, we decoupled rule trigger services, rule processing engine, and rule execution services. Rule trigger services are a collection of microservice, each capable of processing a specific type of rule trigger logic. The rule engine combines various trigger statuses as per the rule definition to determine if a rule should be triggered. Finally, rule execution services are application-specific rule execution logic that performs the intended actions specified in the rule. Each of these components is developed independently. They implement a well-defined interface and can be scaled independently.
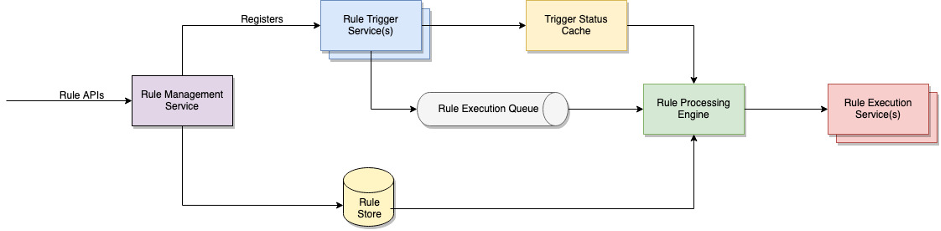
Figure 2 Rule Engine Components
Rule Trigger Services
Rule trigger services implement logic to determine when a rule should be triggered. It is a collection of microservices, each capable of processing a very specific type of trigger. For instance, the logic for point-of-time activation and time duration-based triggers is handled by a microservice for timer triggers. Likewise, different services handle triggers for the device status or weather-based triggers.
Based on the rule trigger conditions in the rule definition, a rule registers itself with one or more rule trigger services when it is first created. Each trigger service provides three primary APIs to register, update and de-register a rule. The actual payload to register for a trigger can vary between services, however, the rule creation/update APIs are designed in such a way that the rule management service can quickly identify the trigger type and delegate the parsing and interpreting trigger conditions to the respective trigger service. The endpoints of individual trigger types can be shared as part of the configuration or environment variables or they can be discovered at runtime using a standard service discovery pattern.
Each trigger type has a different activation service logic. A trigger may capture data from one or more input sources, process it, cache it if necessary and emit an event when it decides if the rule should be triggered. A rule trigger service emits a Boolean true when a specific rule meets the trigger criteria or false when it does not.
A rule can include one or more triggers, where each trigger establishes a specific condition that must be satisfied for the rule to execute. For example, consider a rule that turns on the living room light at six pm every day or when the ambient lighting level falls below 100 lux. The rule combines two conditions using the OR logic, the first of which is a time-based trigger and the second is the device (ALS sensor) status trigger. More complex rules can also be created with a combination of multiple triggers and logical operators.

Figure 3 Rule trigger status
To manage the status of each trigger, a persistent cache is used, which is updated by the respective trigger services. This ensures that the latest trigger status is always available to the rule processing engine, allowing it to evaluate the conditions and invoke the appropriate action. In the picture above, a red trigger status indicates that the trigger condition is currently failing, and a green status indicates that the trigger condition is already met. Once the trigger status of a rule changes, the respective trigger service adds the rule id to a queue for processing, which is subsequently consumed by the rule processing engine.
Each rule trigger service is designed to be horizontally scalable and can scale independently of other system components based on the number of registered rules. The decoupling also allows the activation logic of each trigger to evolve independently as the application evolves. Moreover, new trigger types can be added to the system with minimum change.
Rule Processing Engine
The rule processing engine processes rules from the to-be-processed rule queue and executes the rule based on the trigger status. If the trigger logic is a combination of one or more rule triggers, the processing engine combines the status of each input trigger based on the trigger logic specified in the rule definition to compute a final Boolean value. Once it determines that the rule must be triggered, it invokes the rule execution service to execute the rule.
There are broadly two categories of trigger status. A point-in-time trigger is valid only when the trigger status is changed, for example, activating a rule at six pm or device status change triggers such as turning off the fan when the AC is turned on. Such rules should be activated immediately after the event has taken place, provided all other trigger conditions are also met. The rule processing engine immediately resets the value of such triggers after it has processed the rule.
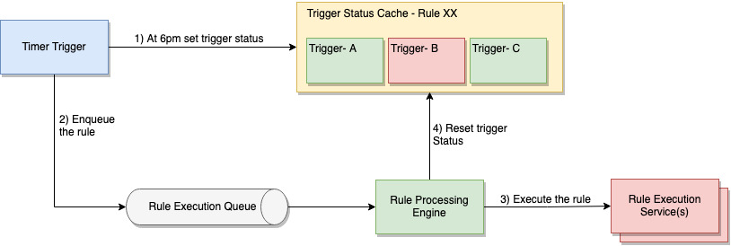
Figure 4 Point-in-time trigger example: Activating a rule at 6 pm
The second category of triggers represents the persistent status of entities over an extended period. For instance, consider a scenario where the porch light should be turned on if motion is detected between 6 pm and 6 am. A timer trigger service would set the trigger value to true at 6 pm and then set it to false at 6 am. These statuses are not reset by the rule processing engine and remain unchanged until explicitly modified by the trigger service. This enables the system to maintain the persistent state of entities and make decisions based on their ongoing status.
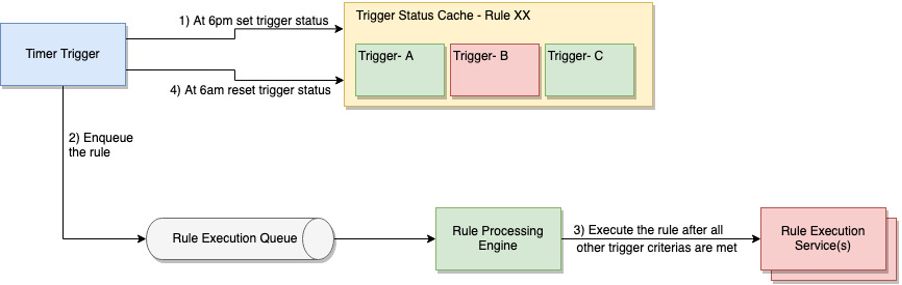
Figure 5 Time-duration trigger example: Activating a rule between 6 pm and 6 am
Rule Execution Services
A rule execution service can call an HTTP API, send an MQTT message or fire a push notification to execute a rule. The list of actions a rule can perform is application specific and extensible. Like rule trigger services, rule action services are decoupled with the core rule engine and are independently scalable.
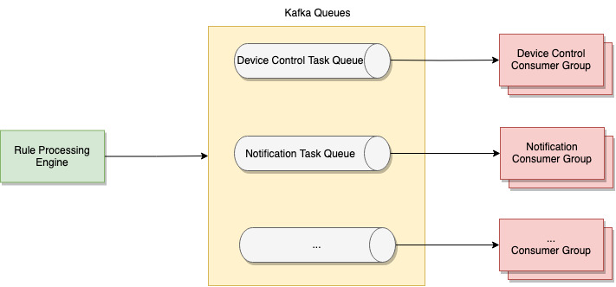
Figure 6 Rule Execution Flow
One way to decouple rule execution service with multiple rule action services is using a message queue such as Kafka. Based on the action type, the rule execution service can publish rule actions to separate Kafka topics and a set of consumers can consume those topics and execute the relevant action. The rule action payload can be specific to the action type and is captured as part of the rule definition and passed as is to the task queues.
Scaling Trigger Services
Rule trigger services can be stateful and hence scaling them could be a challenge. There is no common approach to scaling all trigger services as their underlying implementation varies based on the trigger type and external services they may depend on. In this section, I will explain scaling methods used for two important trigger types.
Device Status Triggers
To register a rule with the device status trigger service, the rule management service will provide the device identifier, device properties, and their corresponding threshold values. The device status trigger service will store these in a shared cache such as Redis and ensure they are accessible using just the device Id.
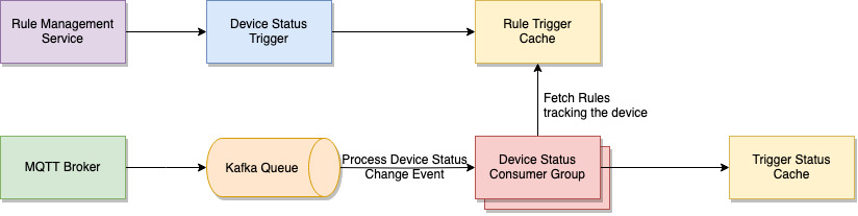
Figure 7 Device Status Trigger Service
In the given example, notifications about changes in device status are sent through the MQTT protocol and then added to the Kafka message queue. A Kafka consumer responsible for device status receives and processes each incoming event. It checks the rule trigger cache to determine if any rules are associated with the device. Based on this information, the consumer updates the corresponding trigger status cache, reflecting the current state of the triggers for that device. This mechanism ensures that the trigger status cache remains up to date with the latest device status changes, allowing the system to evaluate rules accurately based on the most recent information.
All our services are containerized and run in a Kubernetes cluster. The device status trigger service is a standard API service that is scaled up using an application load balance and an auto-scaling group. The device status consumer group is scaled up based on the rate of incoming device status change events. Kubernetes Event-Driven Autoscaling (KEDA) can drive the scaling of device status consumers based on the number of events needing to be processed. Furthermore, there are tools that can predict Kafka workload, which can be employed to scale consumers more promptly, leading to improved performance.
Timer Trigger
The timer trigger service processes point-in-time triggers and time duration triggers. The trigger request payload could be as simple as a specific time of day or as detailed as the specification of a Unix Cron job. The service does not need to hold all registered rule requests in memory as rules may not trigger for days or months. Instead, once it receives a rule registration request, it calculates the next time when the rule should be run and stores the rule details along with the next run time in a database.
Periodically, at a fixed interval, the service fetches all rules that need to be activated in the subsequent time window and pulls them into memory. This can be done by filtering on the next run time field of the rule. Once it has identified all the rules that need to be run, the service orders the rule by trigger time and spawns one or more Kubernetes pods to process these rules. Each pod will only be assigned a subset of the rules. The rule assignment to different pods can be shared via Zookeeper or Kubernetes Custom Resource Definition (CRD).
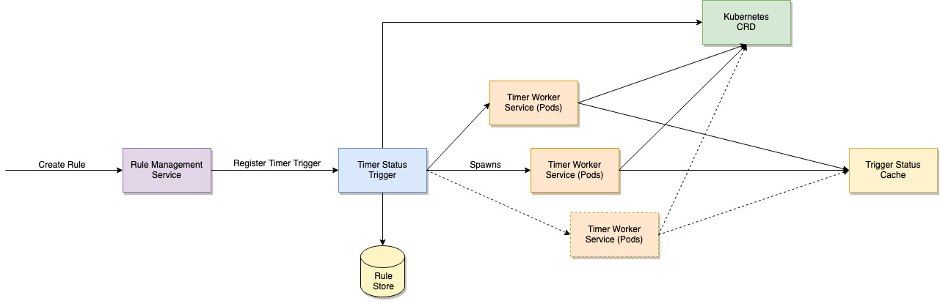
Figure 8 Timer trigger service
Kubernetes CRD can be used to share data and distribute work across multiple pods by defining custom resources that represent specific tasks. The timer trigger services use this functionality by dividing all the rules that require processing in the next time window into separate tasks and storing them in CRD. Multiple worker pods are subsequently created and assigned specific tasks. Each pod then processes the rules and updates the trigger status cache accordingly.
Maintainability and Extensibility
The rule management service and the rule execution services are stateless services with fairly simple logic. Rule management provides standard API for rule creation, update, and deletion. Rule execution services are working independently to execute the rule actions, primarily invoking app-specific operations.
The communication between the rule management service and trigger services can be made asynchronous, removing the need for service discovery. For example, each trigger service can have its dedicated queue in a Kafka message broker. The rule management service can add trigger requests to corresponding queues based on the trigger type, which can be consumed by the Kafka consumer (trigger service) processing that triggers type.
Adding support for a new trigger type and new action type is simple, given all key components are decoupled from each other. Rule management service has a plug-in-based design wherein plug-ins are added for each supported trigger type and action type to validate corresponding triggers and actions payload in the rule definition. Rule trigger and action type names can be translated to the corresponding Kafka queue names for communication between the rule management service and trigger services and between the rule processing service and execution services.
Testing the system is possible at many levels. It is relatively easy to cover individual services with unit tests, focusing on specific functionalities. To facilitate easy debugging and troubleshooting in a distributed environment, it is essential to adhere to best practices for distributed logging and tracing. A properly implemented logging and tracing mechanism will enable us to trace the flow of requests across different services, identify issues, and diagnose problems effectively. Following these best practices ensures better visibility into the system's behaviour and simplifies the debugging process.
Reliability
Let's begin by identifying potential challenges that may arise. It's important to acknowledge that any service within the system can experience downtime unexpectedly, the system load can grow faster than its capacity to scale effectively, and certain services or infrastructure components might encounter temporary unavailability.
Using Kafka for communication helps achieve reliability at several levels. Kafka provides features that contribute to message delivery and consumption reliability, including message persistence, strong durability guarantees, fault-tolerant replication, load distribution between consumer groups, and at least one delivery semantics.
The most straightforward case for reliability involves trigger services. For device status trigger, Kafka is configured to guarantee at least one delivery, which ensures that no status change event is lost. However, achieving reliability in the timer trigger service required additional steps. Here it is important to avoid overwhelming any single worker with a large number of events that need processing at the same time.
Our approach is to chronologically order the list of rules to be processed in the next time window and distribute them in a round-robin manner among the worker services. Furthermore, the number of worker pods is proportional to both the number of timer tasks within the time window and the maximum number of tasks to be executed at any given time. This ensures that an adequate number of worker nodes are available to handle a potentially high volume of timer tasks simultaneously. Additionally, it's beneficial to configure the worker pod to automatically restart in case of a crash, enabling it to resume and complete its assigned task without manual intervention.
In addition, Kubernetes offers the advantage of defining resource limits and minimum requirements for each service. This includes specifying the maximum amount of CPU or RAM resources a service can utilize and the minimum resources it needs to start successfully. With Kubernetes, concerns about issues like a "noisy neighbor" problem, where one pod's resource-intensive behavior affects others on the same cluster node, are mitigated. Kubernetes provides isolation and resource management capabilities that help maintain the stability and reliability of the overall system.
Summary
MirAIe rule engine is an extensible and scalable rule engine framework that allows users to group and automate multiple activities. The framework supports a variety of internal or external triggers and focuses on two design principles: extensibility and flexibility. The architecture must be extensible to support a variety of input triggers and output actions, allowing for new types to be added without much change. The system also prioritizes flexibility to enable independent scaling of each component, resulting in improved resilience and cost efficiency.
Published at DZone with permission of Neeraj Nayan. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments