The Art of Being Ready: Reliability in Extreme Conditions
By adopting a holistic approach and utilizing the principles and practices of engineering, we can have the best of both worlds — speed, and reliability.
Join the DZone community and get the full member experience.
Join For FreeWhen it comes to online services, uptime is crucial, but it’s not the only thing to consider. Imagine running an online store — having your site available 99.9% of the time might sound good, but what if that 0.1% of downtime happens during the holiday shopping season? That could mean losing out on big sales. And what if most of your customers are only interested in a few popular items? If those pages aren’t available, it doesn’t matter that the rest of your site is working fine.
Sometimes, being available during peak moments can make or break your business. It’s not just e-commerce — a small fraction of airports handle most of the air traffic, just a tiny minority of celebrities are household names, and only a handful of blockbuster movies dominate the box office each year. It’s the same distribution pattern everywhere.
To be successful, it’s important to not only maintain uptime but also be ready for significant events. Some teams implement change freezes before key times, such as Prime Day, Black Friday, or Cyber Monday. This approach is reasonable, but it can be limiting as it doesn’t allow teams to quickly respond to unexpected opportunities or critical situations. Additionally, not all demand can be predicted, and it’s not always clear when those high-impact events will happen. This is where “Reliability when it matters” comes in. We need to be able to adapt and respond quickly to changes in customer demand without being held back by code freeze periods and being prepared for unforeseen situations.
By considering time as a valuable resource and understanding the relative significance of different moments, organizations can better translate customer value and adjust risk and availability budgets accordingly. This approach allows organizations to be flexible and responsive to changes in demand without missing out on crucial features or opportunities. In the end, it’s about being ready when luck comes your way.
It’s important to note that a system is not static and is constantly changing. The system itself, the infrastructure it’s hosted on, and the engineering organization all change over time. This means that knowledge about the system also changes, which can impact reliability.
Besides that, incidents and outages are inevitable, no matter how much we try to prevent them. Bugs will be shipped, bad configurations will be deployed, and human error will occur. There can also be interdependencies that amplify outages. An incident rarely has a single cause and is often a combination of factors coming together. The same goes for solutions, which are most effective when they involve a combination of principles and practices working together to mitigate the impact of outages.
Operating a system often means dealing with real-world pressures, such as time, market, and management demands to deliver faster. This can lead to shortcuts being taken and potentially compromise the reliability of the system. Growth and expansion of the user base and organization can also bring additional complexity and result in unintended or unforeseen behaviors and failure modes. However, by adopting a holistic approach and utilizing the principles and practices of engineering I’m going to cover below, we can have the best of both worlds — speed, and reliability. It’s not an either-or scenario but rather a delicate balance between the two.
What Is Reliability?
Reliability is a vital component of any system, as it guarantees not only availability but also proper functioning. A system may be accessible, yet if it fails to operate accurately, it lacks reliability. The objective is to achieve both availability and precision within the system, which entails containing failures and minimizing their impact. However, not all failures carry equal weight. For instance, an issue preventing checkout and payment is far more crucial than a minor glitch in image loading. It’s important to focus on ensuring important functions work correctly during critical moments.
In other words, we want to focus on being available and functioning correctly during peak times, serving the most important functionality, whether it be popular pages or critical parts of the process.
Making sure systems work well during busy times is tough, but it’s important to approach it in a thoughtful and thorough way. This includes thinking about the technical, operational, and organizational aspects of the system. Key parts of this approach include:
- Designing systems that are resilient, fault-tolerant, and self-healing.
- Proactively testing systems under extreme conditions to identify potential weak spots and prevent regressions.
- Effective operational practices: defining hosting topology, auto-scaling, automating deployment/rollbacks, implementing change management, monitoring, and incident response protocols.
- Navigating the competing pressures of growth, market demands, and engineering quality.
- Cultivating a culture that values collaboration, knowledge sharing, open-mindedness, simplicity, and craftsmanship. It also requires a focus on outcomes in order to avoid indecision and provide the best possible experience for customers.
Further, we’re going to expand on the concept of “Reliability when it matters” and provide practical steps for organizations to ensure availability and functionality during critical moments. We’ll discuss key elements such as designing systems for reliability, proactively testing and monitoring, and also delve into practical steps like automating deployment and incident response protocols.
Reliability Metrics: A Vital Tool for Optimization
When optimizing a service or system, it's essential to initially define your objectives and establish a method for monitoring progress. The metrics you choose should give you a comprehensive view of the system’s reliability, be easy to understand, share, and highlight areas for improvement. Here are some common reliability metrics:
- Incident frequency: the number of incidents per unit of time.
- Incident duration: the total amount of time incidents last.
While these metrics are a good starting point, they don’t show the impact of incidents on customers. Let’s consider the following graph:
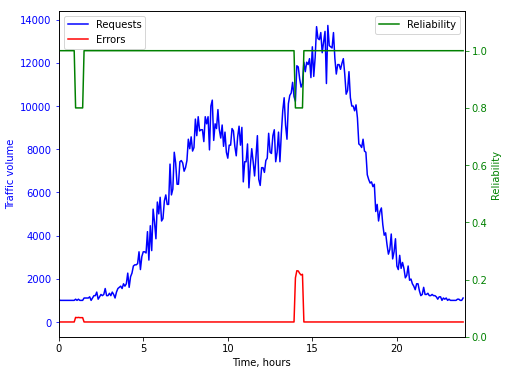
Suppose we have two incidents, one at 1 am and one at 2 pm, each causing about 10% of requests to fail for an equal duration of 30 minutes. Treating these incidents as equally impactful on reliability wouldn’t reflect their true effects on customers. By considering traffic volume, the reliability metric can better show that an incident during peak traffic has a bigger impact and deserves higher priority.
Our goal is to have a clear signal that an incident during peak traffic is a major problem that should be fixed. This distinction helps prioritize tasks and make sure resources are used effectively. For example, it can prevent the marketing team’s efforts to bring more visitors from being wasted. Additionally, tracking the incident frequency per release can help improve the deployment and testing processes and reduce unexpected issues. In the end, this should lead to faster delivery with lower risks.
Digging Deeper Into Metrics
To get a deeper understanding of these metrics and find areas for improvement, try tracking the following:
- Time to detection: how long it takes to notice an incident.
- Time to notification: how long it takes to notify relevant parties.
- Time to repair: how long it takes to fix an incident.
- Time between incidents: this can reveal patterns or trends in system failures.
- Action item completion rate: the percentage of tasks completed.
- Action item resolution time: the time it takes to implement solutions.
- Percentage of high-severity incidents: this measures the overall reliability of the system.
Finally, regularly reviewing these metrics during weekly operations can help focus on progress, recognize successes, and prioritize. By making this a regular part of your culture, you can use the data from these metrics to drive better decisions and gradually optimize the system.
Remember, the usefulness of metrics lies in the actions taken from them and their ability to drive progress. It’s a continuous feedback loop of refining both the data and the action items to keep the system improving.
Designing for Resilience
A system that isn’t designed to be resilient probably won’t handle peak times as smoothly. Here are some considerations that can help ensure a system’s reliability under a variety of conditions:
Do’s:
- Prepare for component failure: By partitioning the service or using isolation, you can limit the blast radius and reduce the impact of failures.
- Implement fault-tolerance: Implementing mechanisms like retries, request hedging, and backpressure will improve the system’s availability and performance.
- Use rate-limiting and traffic quotas: Don’t rely solely on upstream dependencies to protect themselves. Use rate-limiting and traffic quotas to ensure that your system remains reliable.
- Categorize functionality: Prioritize functions by categorizing them into “critical,” “normal,” and “best-effort” categories. This will help keep essential functions available at all costs during high demand.
- Implement error-pacing and load-shedding: These mechanisms help prevent or mitigate traffic misuse or abuse.
- Continuously challenge the system: Continuously challenge the system and consider potential failures to identify areas for improvement.
- Plan for recovery: Implement fail-over mechanisms and plan for recovery in the event of a failure. This will help reduce downtime and ensure that essential services are available during challenging conditions.
- Make strategic trade-offs: Make strategic trade-offs and prioritize essential services during challenging external conditions.
Dont’s:
- Don’t assume callers will use your service as intended.
- Don’t neglect rare but potential failures; plan and design prevention measures.
- Don’t overlook the possibility of hardware failures.
I explored some of the ideas in the following blog posts:
- Ensuring Predictable Performance in Distributed Systems
- Navigating the Benefits and Risks of Request Hedging for Network Services
- FIFO vs. LIFO: Which Queueing Strategy Is Better for Availability and Latency?
- Isolating Noisy Neighbors in Distributed Systems: The Power of Shuffle-Sharding
Reliability Testing
Reliability testing is essential for maintaining the availability and functionality of a system during high demand. To ensure a reliable system, it is important to:
- Design for testability so each component can be tested individually.
- Have good enough testing coverage as a prerequisite for being agile.
- Calibrate testing by importance, focusing on essential functions and giving a bit of slack to secondary or experimental features.
- Perform extensive non-functional testing, such as load testing, stress testing, failure-injection testing, soak testing, and fuzzing/combinatorial testing.
It’s crucial to avoid:
- Blindly pursuing high coverage numbers.
- Assuming that a single data point provides a comprehensive understanding. Ensure that results are robustly reproducible.
- Underinvesting in testing environments and tooling.
Proper testing not only ensures correctness, serves as living documentation, and prevents non-functional regressions but also helps engineers to understand the system deeper, flex their creative muscles while trying to challenge them, and ultimately create more resilient, reliable systems for the benefit of all stakeholders.
Remember, if you don’t deliberately stress test your system, your users will do it for you. And you won’t be able to choose when that moment comes.
Reliability Oriented Operations
Operating a distributed system is like conducting an orchestra, a delicate art that requires a high level of skill and attention to detail. Many engineers tend to underestimate the importance of operations or view it as secondary to software development. However, in reality, operations can have a significant impact on the reliability of a system. Just like a conductor’s skill and understanding of the orchestra is vital to ensure a harmonious performance.
For example, cloud computing providers often offer services built on open-source products. It’s not just about using the software but how you use it. This is a big part of the cloud computing provider business.
To ensure reliability, there are three key aspects of operations to consider:
- Running the service: This involves hosting configuration, deployment procedures, and regular maintenance tasks like security patches, backups, and more.
- Incident prevention: Monitoring systems in real-time to quickly detect and resolve issues, regularly testing the system for performance and reliability, capacity planning, etc.
- Incident response: Having clear incident response protocols that define the roles and responsibilities of team members during an incident, as well as effective review, communication, and follow-up mechanisms to address issues and prevent similar incidents from happening or minimize their impact in the future.
The incident response aspect is particularly crucial, as it serves as a reality check. After all, all taken measures were insufficient. It’s a moment of being humble and realizing that the world is much more complex than we thought. And we need to try to be as honest as possible to identify all the engineering and procedural weaknesses that enabled the incident and see what we could do better in the future.
To make incident retrospectives effective, consider incorporating the following practices:
- Assume the reader doesn’t have prior knowledge of your service. First of all, you write this retrospective to share knowledge and write clearly so that others can understand.
- Define the impact of the incident. It helps to calibrate the amount of effort needed to invest in the follow-up measures. Only relatively severe incidents require a deep process, do not normalize retrospectives by having them for every minor issue that doesn’t have the potential to have a lasting impact.
- Don’t stop at comfortable answers. Dig deeper without worrying about personal egos. The goal is to improve processes, not blame individuals or feel guilt.
- Prioritize action items that would have prevented or greatly reduced the severity of the incident. Aim to have as few action items as possible, each with critical priority.
In terms of not stopping at the “comfortable answers,” it’s important to identify and address underlying root causes for long-term reliability. Here are a few examples of surface-level issues that can cause service disruptions:
- Human error while pushing configuration.
- Unreliable upstream dependency causes unresponsiveness.
- Traffic spike leading to the temporary unavailability of our service.
It can be difficult to come up with action items to improve reliability in the long term based on these diagnoses.
On the other hand, deeper underlying root causes may sound like:
- Our system allowed the deployment of an invalid configuration to the whole fleet without safety checks.
- Our service didn’t handle upstream unavailability and amplified the outage.
- Our service didn’t protect itself from excessive traffic.
Addressing underlying root causes can be more challenging, but it is essential for achieving long-term reliability.
This is just a brief overview of what we should strive for in terms of operations, but there is much more to explore and consider. From incident response protocols to capacity planning, there are many nuances and best practices to be aware of.
The Human Factor in System Reliability
- Collaboration with other teams and organizations in order to share knowledge and work towards a common goal.
- A degree of humility and an open-minded approach to new information in order to adapt and evolve the system.
- A focus on simplicity and craftsmanship in order to create evolvable and maintainable systems.
- An action-driven and outcome-focused mindset, avoiding stagnation and indecision.
- A curious and experimental approach akin to that of a child, constantly seeking to understand how the system works and finding ways to improve it.
Conclusion
Ensuring reliability in a system is a comprehensive effort that involves figuring out the right metrics, designing with resilience in mind, and implementing reliability testing and operations. With a focus on availability, functionality, and serving the most important needs, organizations can better translate customer value and adjust risks and priorities accordingly.
Building and maintaining a system that can handle even the toughest conditions not only helps drive business success and pleases customers but also brings a sense of accomplishment to those who work on it. Reliability is a continuous journey that requires attention, skill, and discipline. By following best practices, continuously challenging the system, and fostering a resilient mindset, teams, and organizations can create robust and reliable systems that can withstand any challenges that come their way.
Opinions expressed by DZone contributors are their own.
Comments