Terraforming Your Cloud Infrastructure The Right Way
Follow this tutorial to find out how to transition an Ops team seamlessly to IaaC and CI/CD in a single migration step.
Join the DZone community and get the full member experience.
Join For Free"Greenfield" vs "Brownfield" Projects In IaaC
According to many authors, software architectures come from two different types of projects. In the first place, there are the "Greenfield" projects. Which are brand new projects; this means the software engineering team starts implementing the architecture without any antecedent. Then, there are the "Brownfield" projects. These are projects that already have a history. The architecture was thought differently and the implementations follow accordingly. Brownfield's meaning is that the team needs to figure out how to transition to the new architecture. In summary, there is no need to start from scratch, but the challenge is to switch to the desired architecture.
My experience in infrastructure is analogous to what I've mentioned in the previous paragraph. There are projects that start with IaaC and others that don't. On one hand, Greenfield projects use IaaC, the team has the required coding skills, and a CI/CD like workflow is already implemented; at least partially. On the other hand, Brownfield projects require many extra steps and involve more complexity. The migration requires time for adoption and a well thought and planned pipeline. In this article, I'll sum up my experience with a Brownfield project in IaaC.
Import Your Existing Infrastructure to Terraform
The first step requires the team to Terraform the Cloud Infrastructure. Every resource used in the Cloud Provider console must be converted to code. There are many ways to accomplish the import.
One way would be to take a look at the resources and start coding them. Despite how logical this sounds, this is a bad option. It would take the developer days to code everything, without even mentioning the mess to sync the configuration code with the state code. A better approach is to use Terraform itself. Start by importing the state code using Terraform import. After that, use the Terraform show command to get the configuration code. This option looks very reasonable. Nonetheless, there is even a better way. The Terraformer tool recursively imports both the configuration and state code automatically.
Use Terraformer to import the cloud infrastructure. Here is a sample of how to use it. It pretty much explains itself.
xxxxxxxxxx
region="us-central1"
project_id="YOUR_PROJECT_ID"
terraformer import google --resources=addresses,disks,dns,firewall,forwardingRules,gcs,gke,globalAddresses,globalForwardingRules,healthChecks,monitoring,iam,images,instances,logging,networks --connect=true --regions="${region}" --projects="${project_id}"
Terraformer exports a folder with the name of the project and subfolders that refer to the regions, resources, providers, outputs, and Terraform states. Despite this looks complete, the Terraform states are not always useful. For instance, I started my Brownfield project with Terraformer 0.13.4. But Terraformer imports the states with 0.12. The incompatibility makes me unable to merge states. In this sense, I planned a different partial approach.
I merged the configuration code from Terraformer and imported the state code using Terraform import. I made an inventory of the resource names scrapping the .tf files generated by Terraformer. Once I figured the approach I coded a Python script to automate my import Operations.
x
import os
class Filesystem(object):
def load_file(filepath=None):
file = open(filepath, "r")
lines = [line[:-1] for line in file.readlines()]
file.close()
return lines
def write_file(filepath=None, data=None):
file = open(filepath, "w")
file.write(data)
file.close()
class Shell(object):
def execute_command(command=None):
return os.system(command)
class Utils(object):
# GCP projects.
PROJECT_1 = "project1"
PROJECT_2 = "project2"
class TerraformImporter(object):
def __init__(self, project_id=None, zone=None, module_name=None, resource_name=None, resource_type=None, **kwargs):
# Metadata.
self.project_id = project_id
self.zone = zone
self.module_name = module_name
self.resource_name = resource_name
self.resource_type = resource_type
self.gke_cluster = kwargs.get("gke_cluster", None)
# Templates.
self.import_template = "terraform import module.{}.{}.{} {}"
def get_import_path_by_resource_type(self):
if self.resource_type == "google_compute_instance":
return "projects/{}/zones/{}/instances/{}".format(self.project_id,
self.zone,
self.resource_name)
elif self.resource_type == "google_compute_disk":
return "projects/{}/zones/{}/disks/{}".format(self.project_id,
self.zone,
self.resource_name)
elif self.resource_type == "google_container_cluster":
return "projects/{}/locations/{}/clusters/{}".format(self.project_id,
self.zone,
self.resource_name)
elif self.resource_type == "google_container_node_pool":
return "{}/{}/{}/{}".format(self.project_id,
self.zone,
self.gke_cluster,
self.resource_name)
elif self.resource_type == "google_compute_firewall":
return "projects/{}/global/firewalls/{}".format(self.project_id,
self.resource_name)
elif self.resource_type == "google_compute_network":
return "projects/{}/global/networks/{}".format(self.project_id,
self.resource_name)
else:
return None
def import_resource(self):
self.get_import_path_by_resource_type()
command = self.import_template.format(self.module_name,
self.resource_type,
self.resource_name,
self.get_import_path_by_resource_type())
print(f"Command: {command}")
response = Shell.execute_command(command=command)
if response != 0:
print(f"Resource couldn't be imported: {response}")
def main():
# Params.
project_id = Utils.PROJECT_1
zone = "dummy"
module_name = "terraform-google-ytem-compute-instances"
resource_name = "dummy"
resource_type = "google_compute_disk"
filepath = os.path.join(os.getcwd(), "compute_disks")
# TF Importer.
for line in Filesystem.load_file(filepath=filepath):
resource_name, zone = line.split(" ")
print(f"Importing {resource_type} named {resource_name} at {zone}")
ti = TerraformImporter(project_id,
zone,
module_name,
resource_name,
resource_type,
gke_cluster="")
ti.import_resource()
if __name__ == "__main__":
main()
The scripts requires as input several parameters and a plain file. The parameters refer to the project id, the zone, the target module name and the resource name. The plain file contains several lines which refer to the resource name and its zone. Both divided by a single space. Running the script imports the configured resources.
In order to test the success of the script, run Terraform plan. The resources that were imported shouldn't present any change.
Continuous Integration and Continous Infrastructure Deployment
Once the infrastructure had been Terraformed, I proceeded to build a CI/CD workflow. Without it, operations in IaaC would be unimaginably chaotic. For instance, DevOps would be able to apply changes locally in their machines without even committing the code. As a consequence, state files and configuration files would constantly fail for the members of the team (which would cause an eventual big fail of the project). In summary, if there is no CI/CD, then the project will be a mess.
Continuous Integration (CI)
Continuous Integration is defined as the pipeline that builds the project, runs syntax, acceptance, unit tests, and packages it for its deployment. In Terraform, validating the acceptance of the code would require the construction of new infrastructure and the deployment of a dummy service which could be used for validation. Even though this idea sounds good, it is not something smart. Imagine your code is used to build a 9 node Kafka/Zookeeper Cluster. You would need to create these servers for each commit which makes this expensive.
In contrast to all mentioned, I decided to stay on syntax checking. Thus, I built a Python script that would be used to iterate all the subfolders with a Terraform project. Each iteration starts terraform, authenticates to the remote backend, and validates the code syntax. Here is a sample of my script.
xxxxxxxxxx
import os
import sys
import unittest
import logging
logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(asctime)-15s %(name)s - %(levelname)s - %(message)s")
class DirectoryNotFoundException(Exception):
def __init__(self, message):
super().__init__(message)
class Utils(object):
FOLDER_BLACKLIST = ["ssh", "images", "venv"]
def iterate_folders(folderpaths=None):
for folderpath in folderpaths:
yield folderpath
class Filesystem(object):
def __init__(self):
pass
def retrieve_folderpaths(self):
return [os.path.join(os.getcwd(), folder) for folder in os.listdir(".") if os.path.isdir(folder) and not folder.startswith(".") and folder not in Utils.FOLDER_BLACKLIST]
def change_directory(self, directory):
if not os.path.isdir(directory):
raise DirectoryNotFoundException(f"Directory: {directory} does not exist.")
os.chdir(directory)
class Terraform(object):
def __init__(self):
pass
def terraform_init(self):
logging.info(f"--------------------------------")
logging.info(f"Running terraform init.")
response_code = os.system("terraform init")
logging.info(f"Response code: {response_code}")
return response_code
def terraform_plan(self):
logging.info(f"--------------------------------")
logging.info(f"Running terraform plan.")
response_code = os.system("terraform plan")
logging.info(f"Response code: {response_code}")
return response_code
def terraform_validate(self):
logging.info(f"--------------------------------")
logging.info(f"Running terraform validate.")
response_code = os.system("terraform validate")
logging.info(f"Response code: {response_code}")
return response_code
class TerraformTests(unittest.TestCase):
def setUp(self):
self.tf = Terraform()
self.fs = Filesystem()
def tearDown(self):
pass
def test_terraform_projects(self):
for folderpath in Utils.iterate_folders(folderpaths=self.fs.retrieve_folderpaths()):
logging.info(f"********************************")
logging.info(f"Executing tests for {folderpath}")
self.fs.change_directory(directory=folderpath)
rc = self.tf.terraform_init()
self.assertTrue(rc == 0)
#rc = self.tf.terraform_plan()
#self.assertTrue(rc == 0)
rc = self.tf.terraform_validate()
self.assertTrue(rc == 0)
if __name__ == "__main__":
unittest.main()
The script executes tests based on the unit test package by Python. Everything is packaged inside a Docker container which is run by a CI tool. I used DroneCI.
Continuous Infrastructure Deployment (CID)
The next step is a tricky one. Continuous Deployment is so famous, yet not often implemented due to its complexity. In the Terraform scope, I chose to use Terraform Cloud. This tool is offered by Hashicorp, is free up to 5 users, handles state files by Git commits, allows notifications (E.g: Slack) and offers an awesome UI.
Each project handled by Terraform has its own workspace on Terraform Cloud. Each workspace listens to a specific integration branch (only commitable by pull requests) and has notifications to Slack for every plan, success, failure, application of the plan, creation, etc.
Terraform Cloud Console
Apply the terraform plan
The New Pull-Request Workflow
The following picture depicts the workflow DevOps engineers must follow in order to manage infrastructure with CI/CD.
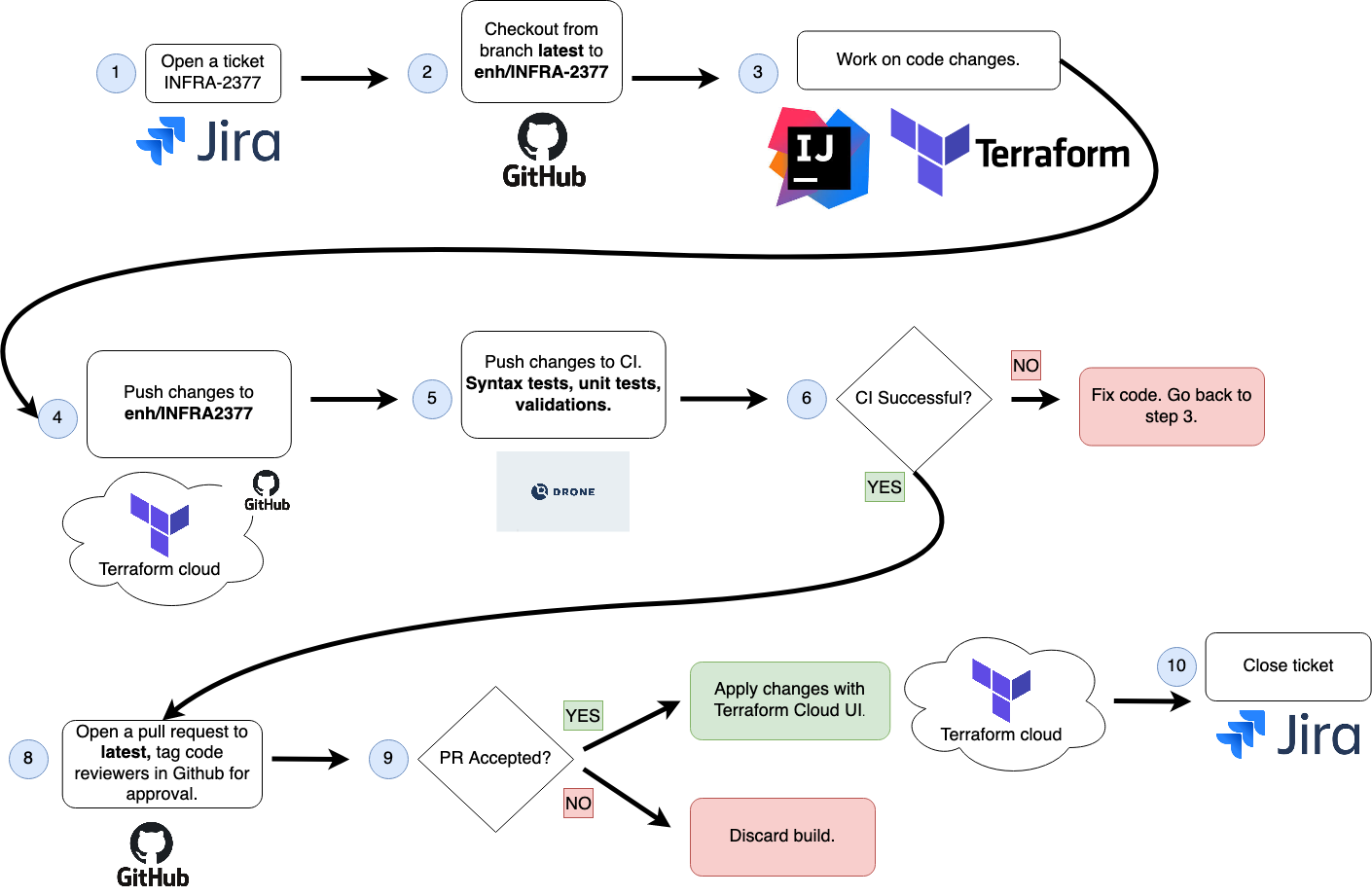
The image is pretty much self-explanatory. But this is something that can be applied as a single step once it has been tested and implemented. As an addition, Terraform Cloud forces Devops to only run Terraform plans and applies from the console. Thus, avoiding any local change.
Conclusion
This article presented an approach to apply IaaC and CI/CID to a "Brownfield" project in Cloud Operations. It started by describing a way to import infrastructure from a cloud provider. Then, depicted how to synchronize the state and configuration Terraform code. After that, it presented an implementation of Continuous Integration. Then it continued presenting how to do Continuous Infrastructure Deployment.
Opinions expressed by DZone contributors are their own.
Comments