Temporal Paradoxes: Multitasking at Its Finest
Distributed systems are complicated. By building an application with Temporal, you get parallelism, concurrency, and fault tolerance for free.
Join the DZone community and get the full member experience.
Join For FreeWhen computing started, it was relatively easy to reason about things as a single series of computations. It didn't take long, though, before we introduced the ability to compute more than one thing at a time. These days, we take for granted computers' ability to multitask. We know that it's because we have multiple cores, CPUs, and servers. Yet somehow, "single-threaded" things like JavaScript and Python are also able to "do more than one thing at a time."
How? There are two different concepts at play here, often at the same time, often confused, yet entirely distinct: Parallelism and Concurrency.
Quickly defined, they are:
- Parallelism: More than one thing literally running at the exact same time.
- Concurrency: The ability to handle multiple things in an undefined order.
Or, put another way, concurrency gives the illusion that multiple things are happening at the same time (as a result of how a program or runtime environment was designed). With parallelism, multiple things actually are happening simultaneously.
Let's take a deeper look. Then, I'll show you how Temporal provides you with reliable concurrency and parallelism with a durable, distributed event loop.
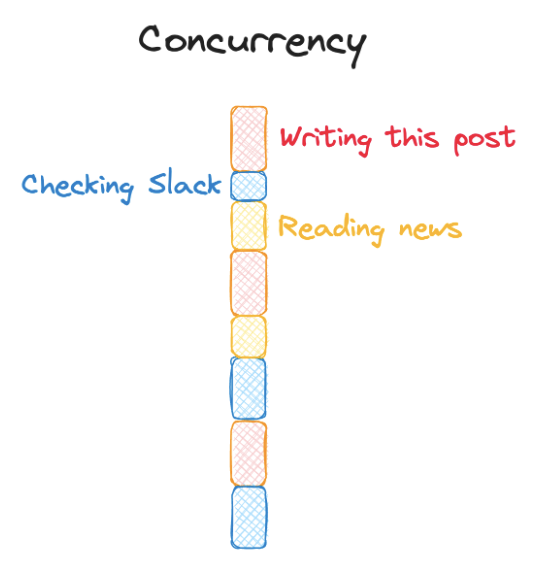
Concurrency
Concurrency is most easily understood through a concept formally called "time-division multiplexing," more commonly known as "multitasking." I might spend a few minutes writing this post, then check Slack messages, then read some news, and then come back to writing. All the tasks are making progress before any one of them is done, but I can't write and do the dishes at the same time. That's concurrency: I'm capable of pausing one thing and coming back to it later after doing something else in the meantime.
But just because I can't check email while also writing a blog post doesn't mean you couldn't be checking email while I'm writing these words. (That'd be parallelism.) You and I are still employing the same skills, though: writing a post and reading an email. Similarly, a well-decomposed program might have one function for calculating a Fibonacci number and a different one for a fractal sequence. Said program could be designed in such a way as to enable pausing one function and allowing the other to run for some time. That, again, is concurrency.
But, if we popped those functions into separate threads or forked one off to another process and ran on a multi-core machine, suddenly, we'd have parallelism, too!
Parallelism
Thus, parallelism might sometimes imply concurrency, but "concurrent" doesn't necessarily mean "parallel." The main difference is that parallelism has things running literally at the same time, while concurrency has them run interleaved.
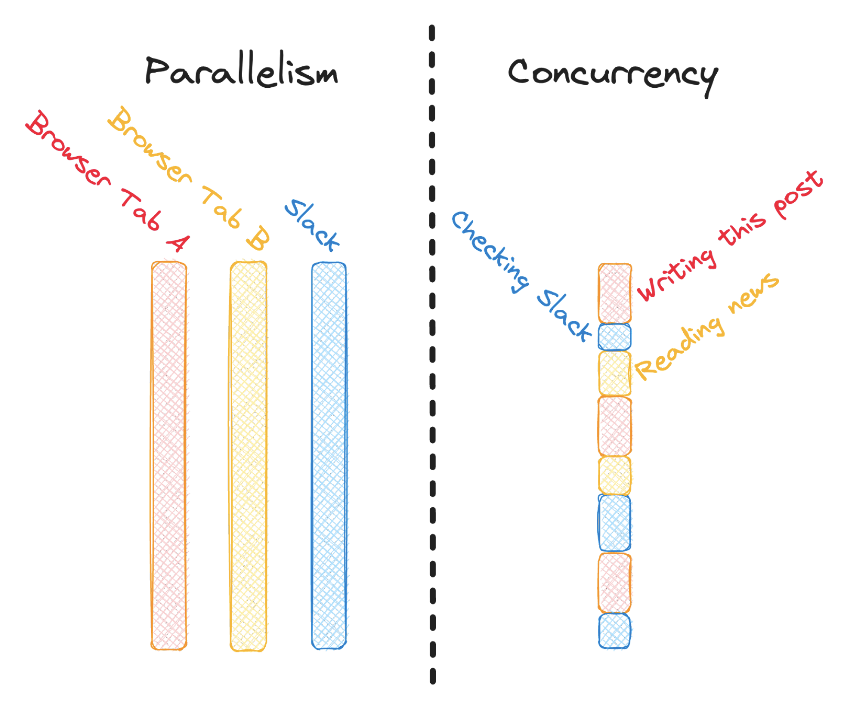
Parallelism is both trivially easy and wildly complex to achieve. Nearly every modern computing device has a multi-core processor, even incredibly small and cheap ones. With that, we do get some parallelism for free: Slack truly is running at the same time as the Google Docs tab I'm writing this in.
In one sense, if your entire computer were a single "program," then the work of building concurrency into it was done naturally as part of separately building out the different functions—chat, browser, terminal. It just happens to run in parallel because of the hardware it's running on.7
Parallelism and Concurrency
As you might imagine, things get complicated from here. Adding threads, hyperthreads, co-processors (e.g., GPUs or VPUs), or entire other machines gives us multiple levels of parallelism and/or concurrency.
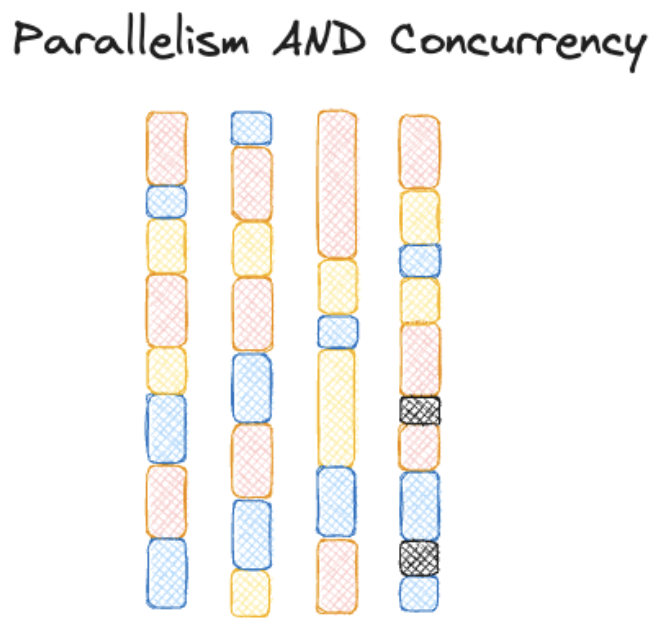
And so, knowing which one is happening within an overall system is often difficult to determine. (This is a big reason why they're confusing and often mixed up or interchanged.)
Consider a bunch of independent processes that you expect to take the same amount of time to run (as in, they run in a reasonable amount of time and do, in fact, finish). When you kick off the processes, and they move on down to your multicore CPU, eventually, they complete and produce results.
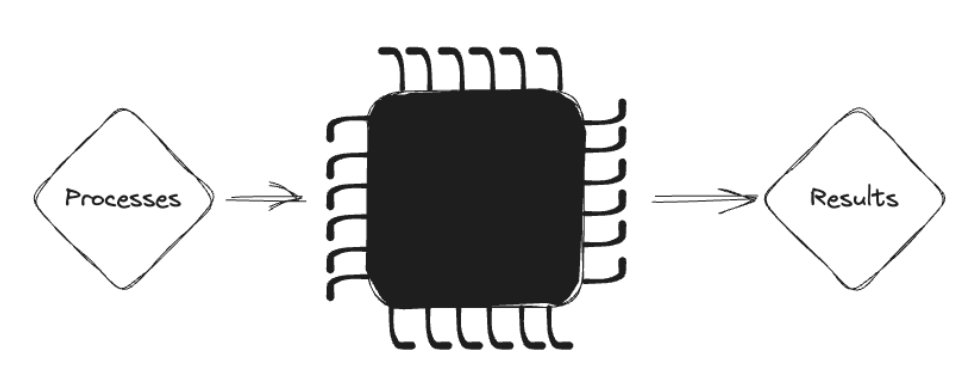
Was the CPU running those processes concurrently, in parallel, both, or neither (serially and in a deterministically predictable order)? Does it even matter if everything happened successfully?
Consider instead that these processes run on different CPUs in different servers yet need to communicate with each other. We're now solidly in the realm of parallelism and concurrency in distributed systems.
If those processes can be run on any machine at any time, in any order, be able to communicate with each other (also at any time), and access common resources (like a database), you're suddenly opening up a whole new world of complexity.
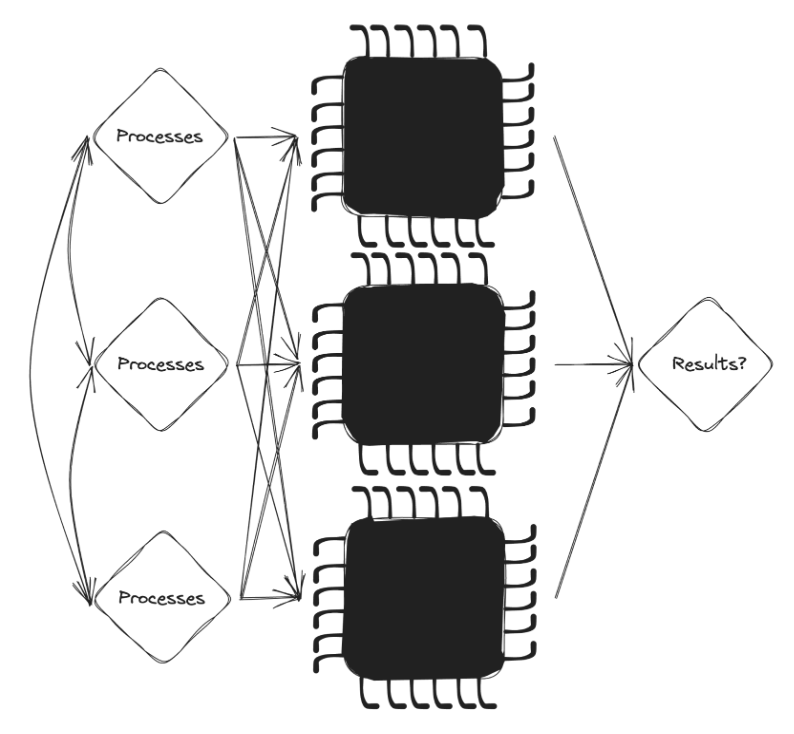
In a single system, those complexities are handled by the operating system, which acts as the mediator between a massive crowd of resource-hungry processes and the resources they're yearning for. This OS mediator was good enough for most of our computing needs for a long time (and still entirely necessary), giving us APIs for accessing shared resources (like the filesystem or network) from any process on the system.
But as our applications have grown to be bigger than a single machine, the single-system OS model breaks down: among other challenges, the kernel on machine A has no idea what resources are available on machine B. And yet, processes need some kind of compute resource; they may not care if it's on machine A or B (as long as other properties like location, performance, etc. are maintained) and just need to be run on something.
Distributed Systems and Temporal
Therein lies the complication of a distributed system. Not only is it a highly parallel environment, there's nothing inherent in the system to mediate access to resources. Critically, this is important because hardware, networks, and everything fails eventually, and work gets lost unless it can be rescheduled on a "good" resource.
To mitigate this fact of distributed system life, we inevitably end up needing to build out something that allows for recovery from failure or is tolerant of those failures in the first place. System design patterns like microservices vs. monoliths, event sourcing and CQRS, or message queues and producers/consumers arise in large part to be able to tolerate and recover from a variety of failures.
Often, these patterns work by breaking an application down into smaller parts and persisting the state of what's already happened, thereby duplicating as little work as possible when something fails. (This is, albeit in a bit of a mental leap, a form of concurrency.)
Those patterns yield their own complications, though. As the system's complexity skyrockets, debugging problems, maintenance, or even just adding features all get difficult and error-prone.
Temporal as a Concurrent (And Parallel) Distributed System
While Temporal doesn't solve all problems inherent in highly parallel systems, it does mitigate most of them. By building an application with Temporal, you are getting parallelism, concurrency, and fault tolerance for free.
Consider an online food ordering and delivery application where the main "business unit" is an order. It's mostly just a high-level conceptual view of the status of one item in the [distributed] system; each step in the order's lifecycle is independent of the others in that once it gets the work request, it can work without any additional communication until it is done. But the lifecycle as a whole is the fundamental concern of the customer ("Where's my order right now?").
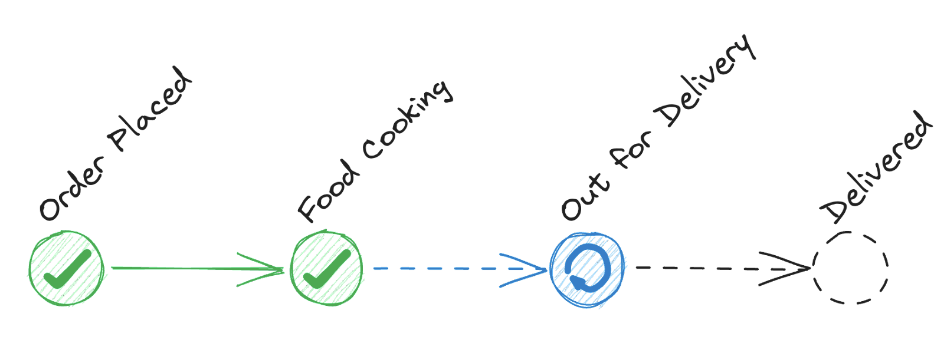
If we treat the order itself as a single software entity — say, a function — it might look something like this pseudo-JavaScript:
function orderStatus(order) {
paymentSucessful = await validateAndPay(order);
if (paymentSucessful) {
// [update status display for "✔︎ order placed"]
} else {
// [inform customer of failure]
}
foodCooked = await sendToRestaurant(order);
// [success/error handling as above]
pickedUp = await findDeliveryDriver(order);
// [success/error handling as above]
delivered = await deliverOrder(order);
// [success/error handling as above]
return "Success!"
}Assuming the OS-level process running this function is perfectly reliable and never goes down, JavaScript is able to concurrently run many, many instances of this function. JavaScript and many other languages operate on a single-threaded, non-blocking event loop model. Extremely briefly, this works as follows:
1. Code runs until done or when it yields (via an await or a timer, e.g., setTimeout in JavaScript).
a. If yielding from an await or timer, the thing being awaited is added to a heap of tasks.
2. The main thread, aka the event loop, checks for ready-to-run tasks. This could be other functions, a timer whose time has come, or an awaited future/promise that has now been resolved.
a. If yes, run them.
3. Repeat ad infinitum.
This allows two functions for, say, Order A and Order B, to run interleaved with each other and make independent progress, regardless of how long the other takes. By this model of concurrency, you get a very strong illusion of parallelism: assuming the restaurants and delivery drivers take a random amount of time to complete, sometimes A will make it all the way through findDeliveryDriver before B even starts, and while A is waiting for deliverOrder to resolve, B completes. Other times, A will finish before B. These two functions appear to run in parallel.
Temporal works almost exactly like this. In fact, Temporal’s SDKs always only run one thing at a time for a given Workflow, even when using ostensibly parallel things like the Go SDK's workflow.Go().
The fundamental difference, though, is that the queue of ready-to-run tasks is not kept in memory but in the Temporal Server. This way, you can have many, many "main threads, aka event loops," in the form of Temporal Workers.
So, while the JavaScript event loop + task queue might look like this:
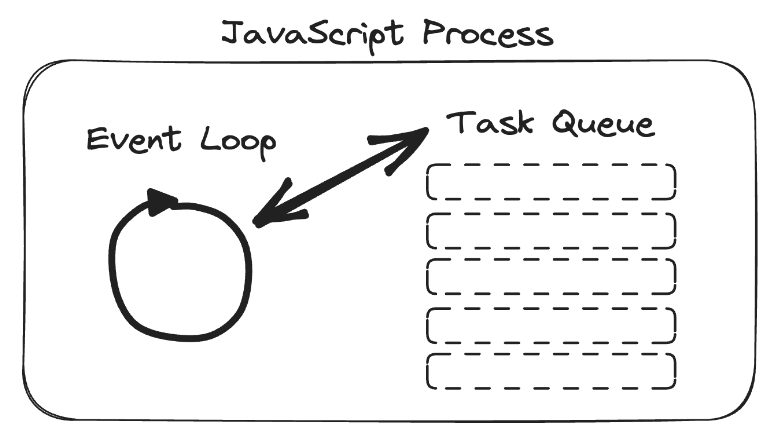
Temporal's version looks more like this:
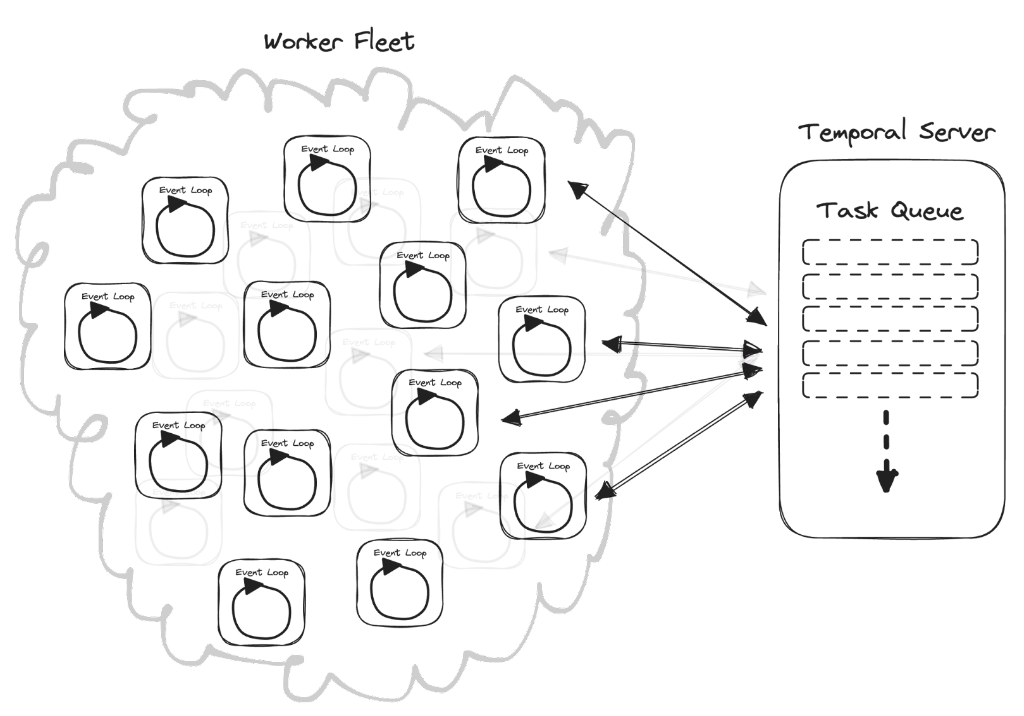
An abstract cloud labeled "Worker Fleet" contains numerous boxes, each of which is labeled "Event Loop" and contains an arrow looping back on itself. Outside of the cloud is a box labeled "Temporal Server," which contains a representation of an infinitely growing "Task Queue." There are bi-directional arrows between many of the "Event Loop" boxes and the "Temporal Server" box.
(Note: The Temporal Server is actually a cluster of many different services, not just a Task Queue.)
With this, Temporal gives you parallelism through being able to have, practically speaking, as many workers as you need. It gives you concurrency by those Workers running with a kind of event loop. It gives you distributed computing by supporting those Workers being run not just in one process but on any machines that you want (as long as they can still reach the Temporal Server).
It also largely solves the problem of a single process crashing, losing connectivity, and losing work as a result: If the "tasks" created by an await are stored elsewhere, the processes running the event loop can come and go with no impact on the function's progress. As a result, the manual effort of implementing producers/consumers, message queues, event sourcing, or other architectural patterns is almost entirely removed.
Summary
Parallelism and Concurrency are topics that are often conflated with each other. Most often, this is because if a single program is effectively and correctly designed to take advantage of parallelism, then it is also concurrent.
However, "only a single thing at a time" environments like JavaScript or Temporal Workers also have a high degree of concurrency but with no internal parallelism for running a single program. (With parallelism achieved only through running multiple JS VMs or Temporal Workers.)
Concurrency, therefore, is the ability of a program to handle different components, interleaving with each other as they run. Parallelism is the environment's ability to run more than one thing at a time.
Whether you were comfortable with the distinction between these two concepts or not, hopefully, this post has improved your sense of them and how they are involved in Temporal applications.
Published at DZone with permission of Andrew Fitz Gibbon. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments