Distributed Systems: Common Pitfalls and Complexity
The complexity of distributed systems is an important challenge. In this post, explore the types of complexity you may encounter and effective tactics to use.
Join the DZone community and get the full member experience.
Join For FreeThe complexity of distributed systems is an important challenge for engineers and developers. Complexity tends to increase as the system evolves, and therefore it is important to be proactive. Let's talk about what types of complexity you may encounter and what effective tactics to deal with it in your work.
Distributed Systems and Complexity
In development, a distributed system is a network of computers that are connected to each other and working on a single task. Each computer or node has its own local memory and processor and runs its own processes. However, they use a common network for coordination and centralization. A distributed system is very reliable; failure of one component does not disrupt the entire network.
In a centralized computing system, one computer with one processor and one memory works on solving problems. In a centralized system, there are nodes, but they access the central node, which can cause network congestion and slowness. A centralized system has a single point of failure — this is an important disadvantage of it.
Complexity
Complexity can be defined from different perspectives and aspects. There are two main definitions that are important.
In systems theory, complexity describes how different independent parts of the system interact and communicate with each other: how they define interactions with each other, how they depend on each other, how many dependencies they have, and also how they interact within the whole.
From a software and technology perspective, complexity refers to the details of the software architecture, such as the number of components.
Monolithic Architecture
Monolithic architecture is a great example of a centralized system. It is represented as a single deployable and single executable component. For instance, such components may contain a user interface and different modules located in one place.
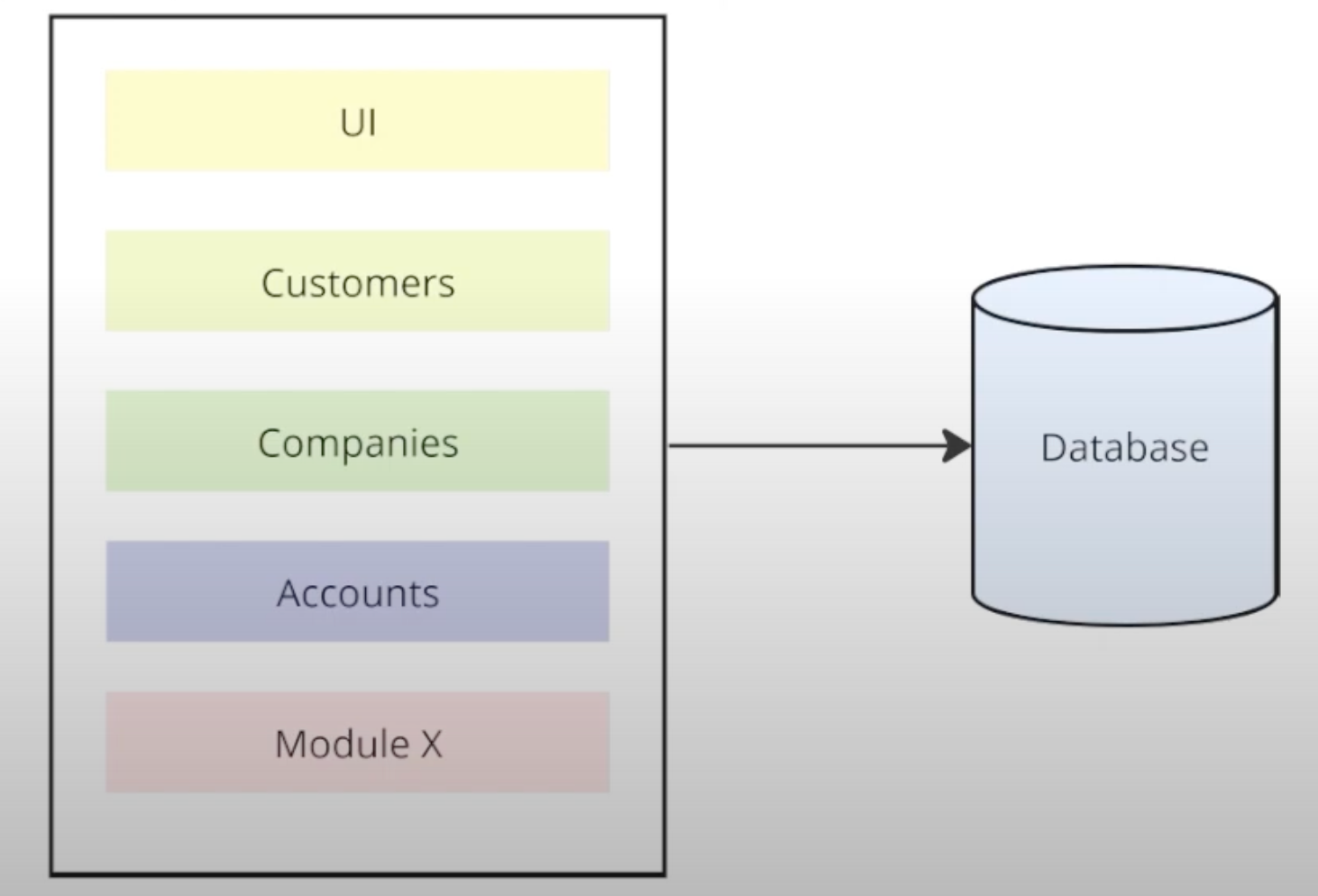
Although this architecture is a traditional one for building software, it has several important drawbacks:
- Inability to scale modules independently
- Harder to control the growing complexity
- Lack of modules independent deployment
- Challenging to maintain a huge code database
- Technology and vendors coupling
Microservices Architecture
Microservices architecture is an architectural style and a variant of service-oriented architecture that structures the system as a collection of loosely coupled services. For example, companies, accounts, customers, and UI are represented as separate processes deployed on multiple nodes.
All these services have their own time-to-time shared database, but this is probably a bad practice or antipattern.
There are some advantages of such an architecture.
- Horizontal scalability is a game-changer! You can scale the database horizontally, and you can scale your services horizontally. Technically, any infrastructure component can be scaled horizontally by cloning, but many challenges must be solved.
- High availability and tolerance: Whenever you have several clones, you may organize some techniques that will help you avoid any downtimes in case of crashes, memory leaks, or power outages.
- Geographic distribution: If we all have customers in the USA, Europe, or Asia, and we also want to bring the best experience to our customers, we need to distribute these services across the world and organize more complicated techniques for data replication.
- Technology choice: You are free to choose your solutions.
Quality Attributes
There are three main quality attributes which any system has at some level or another:
- Reliability: Continuing to function properly despite challenges, meaning being fault-tolerant or resilient; Even if a system operates reliably now, it doesn’t guarantee future reliability. A frequent cause of performance degradation is increased load: for example, the system might have expanded from 10,000 to 100,000 concurrent users, or from 1 million to 10 million.
- Scalability is the term we use to describe a system’s ability to handle increased load. It is important to note that the scalability weakness of the whole system is determined by its weakest component.
- Maintainability is about making life better for the engineering and operations teams who need to work with the system. Good and stable abstractions can help reduce complexity and make the system easier to modify and adapt for new use features.
What Are the Main Issues?
“Anything that can go wrong will go wrong and at the worst possible time.”
— Murphy Law
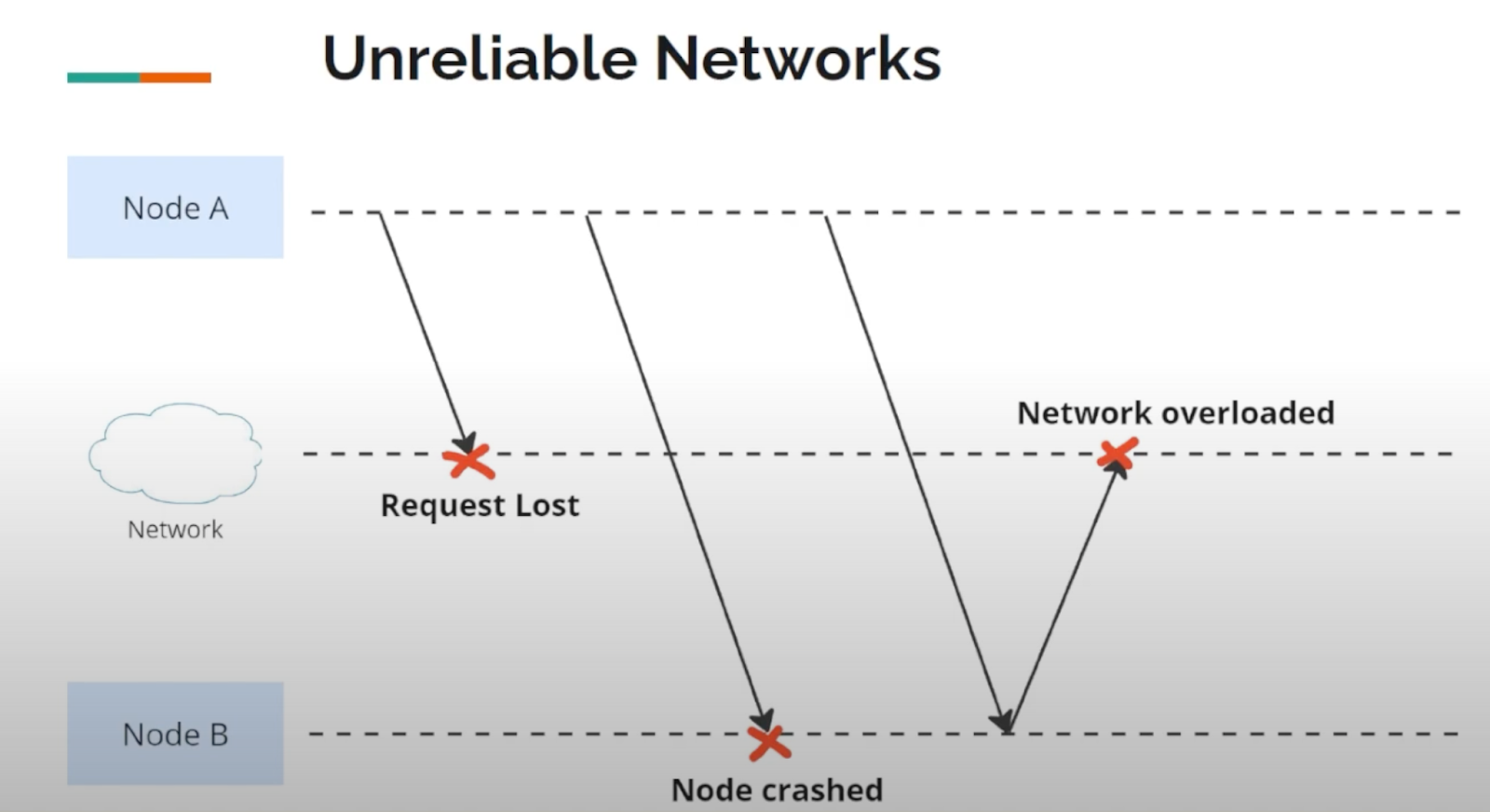
Unreliable Networks
There are many reasons why networks are not reliable, such as:
- Your request may have been lost.
- Your request may be waiting in a queue and will be delivered later.
- The remote node may have failed (perhaps it crashed or was powered down).
- The remote node may have temporarily stopped responding.
- The remote node may have processed your request, but the response has been lost on the network.
- The remote node may have processed your request, but the response has been delayed and will be delivered later.
Strategy: Timeout
The simplest solution to the problem is to apply timeout logic on the caller's side. For example, if the caller doesn’t receive a response after some timeout, it just throws an error and shows an error to the user.
Strategy: Retry
At scale, we can’t just throw exceptions for every network problem and upset users or delay system execution. So, if a response indicates that something goes wrong, just retry it. But what if the request was processed by the server and only the response was lost? In this scenario, retries may lead to severe consequences like several orders, payments, transactions, and so on.
Strategy: Idempotency
To avoid that, we can utilize a technique named idempotency.
The concept of idempotency pertains to the notion that performing the same action multiple times has the same effect as performing it just once. To achieve the property of exactly-once semantics, a solution can be employed that attaches an idempotency key to the request. Upon retrying the same request with the identical idempotency key, the server will verify that a request with such a key has already been processed and will simply return the previous response. Consequently, any number of retries with the same key will not have a deleterious effect on the system's behavior.
Strategy: Circuit Breaker
Another pattern that might be useful in preventing overloading and completely crushing the server in case of failure is the circuit breaker.
Circuit Breaker acts as a proxy to prevent the calling system, which is under maintenance, likely will fail, or heavily failing right now. There are so many reasons why it can go wrong: memory leak, a bug in the code, or external dependencies that are faulted. In such scenarios, it is better to fail fast rather than risk cascading failures.
Concurrency and Lost Writes
Concurrency represents one of the most intricate challenges in distributed systems. Concurrency implies the simultaneous occurrence of multiple computations.
Consequently, what occurs when an attempt is made to update the account balance simultaneously from disparate operations? In the absence of a defensive mechanism, it is highly probable that race conditions will ensue, which will inevitably result in the loss of writes and data inconsistency. In this example, two operations are attempting to update the account balance concurrently. Since they are running in parallel, the last one to complete wins, resulting in a significant issue. To circumvent this problem, various techniques can be employed.
Strategy: Snapshot Isolation
The ACID acronym stands for Atomicity, Consistency, Isolation, and Durability. All of the popular SQL databases implement these properties.
- Atomicity specifies that the operation will be either completely executed or failed, no matter at what stage it happens. It allows us to ensure that another thread cannot see the half-finished result of the operation.
- Consistency means that all invariants are defined and will be satisfied before successfully committing a transaction and changing the state.
- Isolation in the sense of ACID means that concurrently executing transactions are isolated from each other. There is a serializable isolation level which is the strictest one to process all transactions sequentially, but another level named snapshot isolation in popular databases is mainly used.
- Durability promises that once the transaction is committed, all the data is stored safely.
The key idea of this level is that databases track recorded versions and fail to commit transactions for ones that were already modified outside of the current transaction.
Strategy: Compare and Set
Most of the NoSQL databases do not provide ACID properties while choosing in favor of BASE, wherein such databases compare and the set is used. The purpose of this operation is to avoid lost updates by allowing an update to happen only if the value has not changed since you last read it. If the current value does not match what you previously read, the update has no effect and the read-modify-write cycle must be retried.
For instance, Cassandra provides lightweight transactions that allow you to utilize various IF, IF NOT EXISTS, and IF EXISTS conditionals to prevent concurrency issues.
Strategy: Lease
Another potential solution is the lease pattern. To illustrate, consider a scenario where a resource must be updated exclusively. The lease pattern entails first obtaining a lease with an expiration period for the resource, then updating it, and finally returning the lease.
In the event of failures, the lease will automatically expire, allowing another thread to access the resource. Although this technique is highly beneficial, there is a risk of process pauses and clock desynchronization, which may lead to issues with parallel resource access.
Dual Write Problem
The dual write problem is a challenge that arises in distributed systems, particularly when multiple data sources or databases must be kept in sync. To illustrate, consider a scenario in which new data must be stored in the database and messages are sent to Kafka. Since these two operations are not atomic, there is a possibility of failure during the publishing of new messages.
If a transaction is attempted while messages are being sent, the result is a more problematic situation. In the event that the transaction fails to commit, external systems may have already been informed of changes that, in fact, did not occur.
Strategy: Transactional Outbox
One potential solution is the implementation of a transactional outbox. This involves the storage of events in an "OutboxEvents" table within the same transaction as the operation itself. Due to the atomicity of the process, no data will be stored in the event of a transaction failure.
Another necessary component is Relay, which polls the OutboxEvents table at regular intervals and sends messages to destinations. This approach allows for the achievement of at least one delivery guarantee. Nevertheless, this is not a concern since all consumers must be idempotent due to the unreliability of the network.
Strategy: Log Tailing
An alternative solution to the construction of a custom transactional outbox is the utilization of a database transactional log and custom connectors to read directly from this log and send changes to destinations.
This approach has its own advantages and disadvantages. For instance, it requires coupling to database solutions but allows for the writing of less code in the application.
Unreliable Clocks
Time tracking is a fundamental aspect of any software or infrastructure, as it enables the enforcement of timeouts, expirations, and the gathering of metrics. However, the reliability of clocks represents a significant challenge in distributed systems, as the accuracy of time is contingent upon the performance of individual computers, which may have clocks that are either faster or slower than others.
There are two primary types of clocks utilized by computers: time-of-day and monotonic clocks. Time-of-day clocks return the date and time according to a specific calendar, and they are typically synchronized with Network Time Protocol (NTP). However, delays and network issues may affect the synchronization process, leading to clock desynchronization. Monotonic clocks continuously advance, making them suitable for measuring durations.
However, the monotonically increased value is unique to each computer, limiting their use for multi-server date and time comparison. Achieving highly accurate clock synchronization is a challenging task. In the majority of cases, the necessity for such a solution is not apparent. However, in instances where compliance with regulations necessitates its use, the Precision Time Protocol can be employed, although this will entail a significant investment.
Availability and Consistency
The CAP Theorem posits that any distributed data store can only satisfy two of the three guarantees. However, since network unreliability is not a factor that can be significantly influenced, in the case of network partitions, the only viable option is to choose between availability or consistency.
Consider the scenario in which two clients read from different nodes: one from the primary node and another from the follower. A replication is configured to update followers after the leader has been changed. However, what happens if, for some reason, the leader stops responding?
This could be a crash, network partitioning, or another issue. In highly available systems, a new leader must be assigned, but how do we choose between existing followers? To address this issue, a distributed consensus algorithm must be employed. However, before delving into the specifics of this algorithm, it is essential to gain a comprehensive understanding of the various types of consistency.
Consistency Type
There are two main classes of consistency used to describe guarantees.
- Weak consistency, or eventually one, means that data will be synchronized on all followers after some time if you stop making changes to the leader.
- Strong consistency is a property that ensures that all nodes in the system see the same data at the same time, regardless of which node they are accessing.
Strategy: Distributed Consensus Algorithm (e.g., Raft)
Returning to the problem when the leader crashes, there is a need to elect a new leader. This problem, at first glance, looks easy, but in reality, there are so many conditions and tradeoffs that have to be taken into account when selecting the appropriate approach.
Per Raft protocol, if followers do not receive data or heartbeat from the leader for a specified period of time, then a new leader election process begins. Each Replication Unit (monolith write node or multiple shards) is associated with a set of Raft logs and OS processes that maintain the logs and replicate changes from the leader to followers.
The Raft protocol guarantees that followers receive log records in the same order they are generated by the leader. A user transaction is committed on the leader as soon as half of the followers acknowledge the receipt of the commit record and writes it to the Raft log.
Strategy: Read From Leader
One of the possible effective and simple strategies is to read from the follower by the user who just saved new data to avoid replication lag.
Instead of Conclusion
From monolithic architectures to microservices, each approach presents its own set of advantages and challenges. While monolithic architectures offer simplicity, they often struggle with scalability and maintainability, pushing developers towards a more modular and scalable microservices architecture.
Central to the discussion is the management of complexity, which manifests in various forms, from network unreliability to concurrency issues and the dual write problem. Strategies such as timeouts, retries, idempotency, and circuit breakers offer effective tools for mitigating the risks associated with unreliable networks, while techniques like snapshot isolation, compare and set, and leases address the challenges of concurrency and lost writes.
Furthermore, the critical issue of unreliable clocks underscores the importance of accurate time synchronization in distributed systems, with solutions ranging from NTP synchronization to the Precision Time Protocol. Additionally, the CAP theorem reminds us of the inherent trade-offs between availability and consistency, necessitating a thorough understanding of distributed consensus algorithms like Raft.
In conclusion, mastering the maze of complexity in distributed systems requires a multifaceted approach, combining theoretical knowledge with practical strategies. By embracing these strategies and continuously adapting to the evolving landscape of distributed computing, engineers and developers can navigate the complexities with confidence, ensuring the reliability, scalability, and maintainability of their systems in the face of ever-changing challenges.
Opinions expressed by DZone contributors are their own.
Comments