Tarantool: Speeding Up Development With Rust
The dev speed of Lua, the execution speed of C, but with a modern spin.
Join the DZone community and get the full member experience.
Join For FreeAs you may know, Tarantool supports any programming language that is compatible with C and can be compiled to machine code. Among other things, it is possible to implement stored procedures and modules in Lua and C. Nevertheless, we have already used Rust in two of our projects, and in one of them, we converted the Lua code to Rust entirely, thus achieving a 5x performance improvement in comparison with the Lua version and about the same output as the C version.
I am Oleg Utkin from Tarantool, and my main expertise is in data-intensive storage systems. I will cover the two projects mentioned above and the reason why we find Rust so good — it has long had various bindings for the Tarantool API and for Lua modules writing. For example, you can write Rust code for Tarantool right away, along with stored procedures and third-party modules that can be used without Lua. Are you interested? Then let's roll!

One would think that Lua or C are both alright languages. Except they have some significant drawbacks. Although Lua allows you to write code rather quickly, in some situations it may not be executed fast enough.
And, frankly, it does not have a very good ecosystem, as this language is basically used to be embedded in applications so that users can extend the app's functionality and write their own code. This leads to Lua modules that are often incompatible with Tarantool, such as ones for networking and other asynchronous operations. And code written for one environment, say, OpenResty on Nginx, can't be executed on Tarantool or on a pure Lua interpreter. Which results in somewhat isolated ecosystems.
If we talk about C, the code is fast to execute, but quite hard to write because of the manual memory management. This can cause various bugs related to memory handling and slow down the debugging process. In addition, it has a rather complicated interface for writing Lua modules, and integrating with third-party libraries is not so smooth also. First of all, this is because of the sheer variety of build systems that you have to integrate with your code. And secondly, because of the differences in approaches, for example, to work with the network, they have to be collated.
So I made a list of what I would like to have in a language:
- A rich ecosystem of packages that can be reused, thus saving time on development, debugging, and testing.
- A handy package manager for connecting and tracking dependencies.
- A user-friendly build system that will build it all, link it, and make it easy to integrate with other libraries.
- Relatively fast development speed.
- Safe memory handling.
- Fast execution.
Rust appears to meet these criteria quite well. Let's look at our cases first.
The First Case: Developing Stored Procedures for Tarantool
Consider a simple stored procedure that takes three parameters — year, quarter, and minimum price:
Code in Lua
function some_procedure(year, quarter, min_cost)
local space = box.space.some_space.index.some_index
local result = space
:pairs({ year, quarter }, { iterator = 'GE' })
:take_while(function(record)
return record.year == year
and record.quarter == quarter
end)
:filter(function(record)
return record.earning > min_cost
end)
:totable()
return result
endWhat does this do? This stored procedure works with a table of transactions, broken down by quarter, and selects among them the ones that belong to a certain quarter and have a larger total than we specified in the query.
It's rather simple to do so in Lua. But if we wanted to get code that ran faster, we could rewrite it in C, and it would look like this:
Code in C
int some_procedure(box_function_ctx_t* ctx, const char* args, const char* args_end) {
uint32_t args_n = mp_decode_array(&args);
assert(args_n == 3);
uint32_t year = mp_decode_uint(&args);
uint32_t quarter = mp_decode_uint(&args);
double min_cost = mp_decode_double(&args);
uint32_t space_id = box_space_id_by_name("some_space", strlen("some_space"));
uint32_t index_id = 0;
char key_buf[128];
char *key_end = key_buf;
key_end = mp_encode_array(key_end, 3);
key_end = mp_encode_uint(key_end, year);
key_end = mp_encode_uint(key_end, quarter);
key_end = mp_encode_double(key_end, min_earnings);
box_iterator_t* it = box_index_iterator(space_id, index_id, ITER_GE, key_buf, key_end);
while (1) {
box_tuple_t* tuple;
if (box_iterator_next(it, &tuple) != 0) {
return -1;
}
if (tuple == NULL) {
break;
}
uint32_t args_n = mp_decode_array(&tuple);
assert(args_n == 3);
uint32_t record_year = mp_decode_uint(&tuple);
uint32_t record_quarter = mp_decode_uint(&tuple);
double record_cost = mp_decode_double(&tuple);
if (record_year != year || record_quarter != quarter) {
break;
}
if (record_cost <= min_cost) {
continue;
}
box_return_tuple(ctx, tuple);
}
box_iterator_free(it);
return 0;
}It's three times longer. While two-thirds of this code is not the stored procedure logic itself, but just the work of deserializing the data that comes from the storage. For comparison, this is what it looks like on Rust:
Code in Rust
#[derive(Serialize, Deserialize)]
struct Record {
year: u16,
quarter: u8,
earnings: f64,
}
fn some_procedure(ctx: &FunctionCtx, args: FunctionArgs) -> c_int {
let args_tuple: Tuple = args.into();
let (year, quarter, min_cost): (u16, u8, f64) = args.as_struct().unwrap();
let space = Space::find("some_space").index("some_index");
let result: Vec<Record> = index
.select(IteratorType::GE, &(year, quarter))
.map(|tuple| tuple.as_struct::<Record>())
.take_while(|record| record.year == year && record.quarter == quarter)
.filter(|record| record.cost >= min_cost)
.collect()
match ctx.return_mp(&result) {
Ok(_) => 0,
Err(_) => -1,
}
}We used the existing Tarantool bindings to write this code. It is similar in size and logic to the Lua version, but it has the same performance as the C version. What makes it happen?
Code Generation, Macros
One of the coolest things that Rust has is metaprogramming. You can write your own macros that will work with your code through abstract syntax tree manipulation while it's compiling. It is basically a kind of stored procedure that takes this tree and is capable of making any modifications to it.
You don't even have to write it yourself. There are plenty of libraries that will do this for you. They usually use the Serde framework (Serializer, Deserializer):
Serde
#[derive(Serialize, Deserialize)]
struct Record {
year: u16,
quarter: u8,
cost: f64,
}
fn parse_record(raw_data: &str) -> Result<Record, ParseError> {
let record: Record = serde_json::from_str(raw_data)?;
return record;
}Serde implements a universal interface for writing libraries that will serialize/deserialize your data during compilation. Any library that can serialize JSON or MessagePack can be connected with this code, and Serde can literally do it in one line.
Functional Programming and Iterators
Rust includes various operations to handle the data that comes from iterators. For example, you can map data using the map operator, or filter and aggregate data via reduce:
 You can see that the query we make in Rust takes about the same amount of code as we would write in Lua, and has about the same logic.
You can see that the query we make in Rust takes about the same amount of code as we would write in Lua, and has about the same logic.
Results
Here's an example of a test. The results of a sampling procedure on one Tarantool instance (one thread) at 100% CPU usage are as follows:
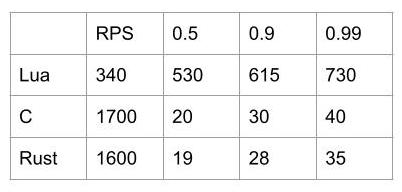
We can see that the Lua code provides 340 RPS, and the C version gives 1700 RPS. Rust allows you to write code as simple as in Lua, but achieves performance comparable to C.
Another Case: Module Development
The next case we used Rust in was module development. This is an example of how Rust code can be wrapped in bindings, and whether it's Lua, JS, or Python, you get a ready-to-use module for your programming language. Let me show you a simple example:

There's a procedure written in Lua that outputs “hello, world”. To implement it in Rust, we just need to follow a certain signature of functions, which we can then pass into Lua. There is no need to perform any data conversion. This applies to all primitive data types that Rust has: they will be automatically encoded into a type suitable for Lua.
If you have some custom type, you can define methods for your structure that will be passed into Rust. Here's a good example:
Example of Lua bindings for the avro_rs library
struct Avro { schema: Schema }
impl Avro {
pub fn new(schema: &str) -> Result<Self, avro_rs::Error> {
Ok(Avro { schema: Schema::parse_str(schema)? })
}
pub fn decode<R: Read>(&self, reader: &mut R) -> Result<Value, avro_rs::Error> {
let avro_value = avro_rs::from_avro_datum(&self.schema, reader, None)?;
Ok(Value::try_from(avro_value)?)
}
}
impl mlua::UserData for Avro {
fn add_methods<'lua, M: LuaUserDataMethods<'lua, Self>>(methods: &mut M) {
methods.add_method("decode", |lua, this: &Avro, blob: LuaString| {
let json_value = this.decode(&mut blob.as_bytes())?;
lua.to_value_with(&json_value)
});
}
}In our actual case, the task was to decode Avro messages inside Tarantool using Lua. Unfortunately, there was no implementation of Avro in Lua, and even if there was, it would probably be quite slow. But we already had a ready-made library written in Rust. We ported it to Lua by simply writing bindings for it.
Of course, the possible applications of Rust are not limited to these. Generally speaking, Rust can replace languages like C and C++ as it can compile to machine code just like them. You will only have to pay for all the features of the language once, at compile time.
But you can use it in much more applied tasks as well. For example, speed up the backend by rewriting the code in Rust with very little effort. There are also many blockchain implementation libraries. I believe it's so popular for these tasks simply because they require high speed of code execution and simplicity of development. Rust can provide all that.
Now let's see what exactly makes Rust so cool. I've classified its features into 4 main categories: memory, types, ecosystem, and network application development.
What Makes Rust so Good
Memory
Among the main Rust features are the concepts of ownership and affine data types:
Ownership transfer
struct User {
name: String,
country: String,
age: i32,
}
pub fn main() {
let user = User {
name: String::from("Igor"),
country: String::from("Russia"),
age: 30,
};
print_user_age(user); // this is where the user is moved inside the function
print_user_country(user); // error: using a moved object
}
fn print_user_age(user: User) {
println!("{} is {} years old", user.name, user.age);
}
fn print_user_country(user: User) {
println!("{} lives in {}", user.name, user.country);
}This means that the data you initialize in some scope will be released exactly once. There will be no problems with variables moving to another scope and getting released there, while you try to reuse data for which destructors have already been called. The compiler can detect this and tell the programmer to fix it.
Borrowing
In case we don't want to transfer ownership of some of our variables to other scopes, we can transfer them by reference:
Borrowing
struct User {
name: String,
country: String,
age: i32,
}
pub fn main() {
let user = User {
name: String::from("Igor"),
country: String::from("Russia"),
age: 30,
};
print_user_age(&user); // transfer via link
print_user_country(&user); // transfer via link
// This is where destructor for the user will be called
}
fn print_user_age(user: &User) {
println!("{} is {} years old", user.name, user.age);
}
fn print_user_country(user: &User) {
println!("{} lives in {}", user.name, user.country);
}The ownership of the variables we allocate in the current scope remains there, and the destructor will be called there as well. But theoretically it is possible that we may have a link that was declared in the external scope, but the data to which it points is allocated in the child scope.
That is, the data that the link points to can be released before the link itself has been released, and at that moment it will point to invalid data. This is where the Borrow checker, built-in to the Rust compiler, comes in:
Borrow checker
struct User { age: i32 }
pub fn main() {
let user_ref: &User;
{
let user = User { age: 30 };
user_ref = &user; // compilation error, as this may cause an invalid reference
// This is where destructor for the user will be called, making user_ref link invalid
}
// This is where destructor for user_ref will be called
}If that situation actually occurs, the compiler will inform you about it and the code won't compile. Generally speaking, it can be said that the Rust compiler guarantees that you will not have references that point to invalid data.
Smart Pointers
But what if we can't determine the size of the data at compile time? This is where the Box type steps in. It allows you to allocate data to the heap. Basically, it's a smart pointer, similar to std::unique_ptr in C++. We allocate data on the stack, move it to the heap straight away, yet its behavior remains the same as if we had this data allocated on the stack. In the example below, we move the user variable to the invoked function and then release the data:
Box type
struct User {
name: String,
country: String,
age: i32,
}
pub fn main() {
let user = Box::new(User {
name: String::from("Igor"),
country: String::from("Russia"),
age: 30,
});
print_user_age(user); // this is where the user is moved inside the function
}
fn print_user_age(user: Box<User>) {
println!("{} is {} years old", user.name, user.age);
// This is where destructor for the user will be called
}But there are situations where you need to use a reference to the same objects in more than one scope or pass them to other execution threads. Rust has the Rc (reference counter) type for that, which is also a smart pointer. When we allocate memory via Rc, we get a counter that indicates how many references there are to that particular data. When we explicitly clone this pointer, the reference counter to this data increments. The counter is decremented when the pointer calls its destructor. If the counter reaches 0, then the data is cleared:
Rc (reference counter) type
struct User {
name: String,
country: String,
age: i32,
}
pub fn main() {
let user = Rc::new(User {
name: String::from("Igor"),
country: String::from("Russia"),
age: 30,
});
let user2 = user.clone(); // cloning a smart pointer
print_user_age(user2); // this is where the pointer to the user is moved inside the function
print_user_country(user); // this is where the user is moved inside the function
}
fn print_user_age(user: Rc<User>) {
println!("{} is {} years old", user.name, user.age);
}
fn print_user_country(user: Rc<User>) {
println!("{} lives in {}", user.name, user.country);
}This approach is called reference counting and is used in many other places. What's so good about it? For instance, here are charts from a rather interesting article by the Discord team about how they were able to speed up their services by switching from Go to Rust:
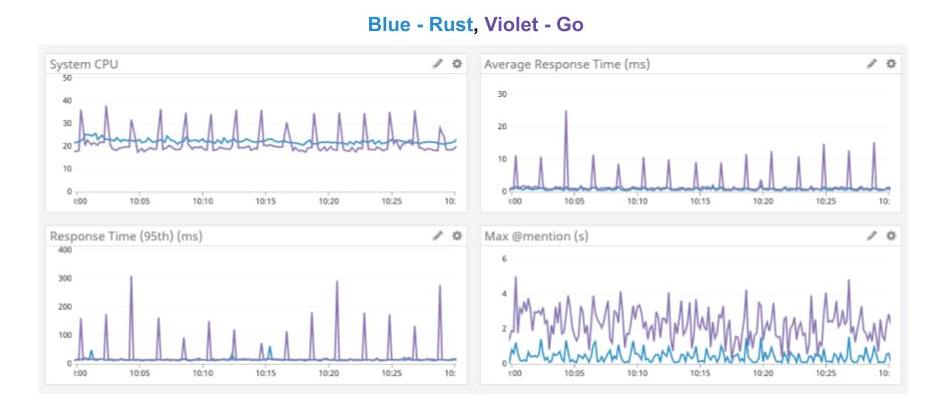
Garbage Collection stops code execution to free up unused memory. But these stops have a negative impact on the latency of requests, especially at 95% and above. The graph shows that thanks to Rust, the latency was reduced significantly and the load on the CPU has become more balanced.
Unsafe
We talked about the features that allow Rust to check the used memory for reliability. But there are situations where we need to perform operations on raw pointers, and the Rust compiler can't check them. So it's the developer's responsibility to check what kind of data is under the pointers and how valid they are.
For this kind of situation, Rust has a special keyword called unsafe, which allows you to isolate a block of code where the compiler can give the developer access to unsafe operations:
let mut num = 5;
let r1 = &num as *const i32;
let r2 = &mut num as *mut i32;
unsafe {
println!("r1 is: {}", *r1);
println!("r2 is: {}", *r2);
}Thanks to this, you will be able to dereference raw pointers. These may be null pointers or pointers to an invalid memory location. And it also provides the possibility to call functions marked as unsafe. You can perform unsafe operations inside such functions, but they can be called only from unsafe blocks. The programmer should understand that with unsafe functions, the compiler can not predict if this code will corrupt the data or not. And whether the pointers it passes or receives from such functions will be valid.
You will also be able to work with FFI when, say, you include a dynamic library. Clearly, the compiler cannot check that the operations you will do in this dynamic library will not affect your memory in any way.
Now let's move on to the next category.
Algebraic Data Types
Algebraic data types in Rust are derived from functional programming. This is effectively a type of sum of types, and in some languages, they are called tagged enum. They allow you to store several options of how the type might look and what structure it may have:
Enum
enum Shape {
Square { width: u32, length: u32 },
Circle { radius: u32 },
Triangle { side1: u32, side2: u32, side3: u32 },
}
pub fn main() {
let square = Shape::Square { width: 10, length: 20 };
let circle = Shape::Circle { radius: 20 };
let shape: Shape = square;
match shape {
Shape::Square { width, length } => println!("square({}, {})", width, length),
Shape::Circle { radius } => println!("circle({})", radius),
_ => println!("other shape"),
}
}In this example, we distinguish several enum choices — Square, Circle, Triangle — and assign them to the common variable Shape. Then, using pattern matching, we determine what we have inside this variable and implement some logic based on that.
Rust also uses this mechanism to handle errors:
Error checking
enum Result<T, E> {
Ok(T),
Err(E),
}
fn do_something_that_might_fail(i: i32) -> Result<f32, String> {
if i == 42 {
Ok(13.0)
} else {
Err(String::from("this is not the right number"))
}
}
fn main() -> Result<(), String> {
let v = do_something_that_might_fail(42)?;
println!("found {}", v);
// equivalent to
let result = do_something_that_might_fail(42);
match result {
Ok(v) => println!("found {}", v),
Err(e) => return Err(err),
}
Ok(())
}How does this work? The Result type is returned from the function, and it can be one of two states: Ok(T), which means the function was executed successfully, or Err(E), which returns some kind of error. We can handle it explicitly — with the same pattern matching. Or by using a special operator (question mark) that returns whatever the function returned on success. If it finished with an error, the error is then passed on to the function that triggered the execution.
The problem with null pointers is solved in a similar way. We have variables that may store data or may not. This is where the Option type comes to the rescue; it can be in either of two states. It is either None (no data in the current variable) or Some(T), which stores the data that we want to return:
Option type
enum Option<T> {
None,
Some(T),
}
fn do_something_that_might_fail(i: i32) -> Option<f32> {
if i == 42 {
Some(13.0)
} else {
None
}
}
fn main() {
let result = do_something_that_might_fail(42);
match result {
Some(v) => println!("found {}", v),
None => println!("not found"),
}
}This allows us to accurately handle all cases where there is no data in the variable, at compile time.
Traits
Another crucial feature of the language is traits, a sort of interface or abstract class that is present in OOP languages. Traits allow you to define the desired behavior of a structure or enum by specifying which methods they should implement.
In addition, traits also make it possible to implement default methods, which, for example, are based on mandatory methods. That is, by implementing just a couple of mandatory methods, we can get a lot of methods based on them — and have logic for our structures implemented automatically:
traits
trait Animal {
pub fn get_name(&self);
pub fn say();
}
struct Dog { name: String };
impl Animal for Dog {
pub fn get_name(&self) -> String { self.name.clone() }
pub fn say() { println!("bark"); }
}
struct Cat { name: String };
impl Animal for Cat {
pub fn get_name(&self) -> String { self.name.clone() }
pub fn say() { println!("meow"); }
}
fn main() {
let animal: Animal = Dog{ name: String::from("Rex") };
animal.say();
println!("animal's name is {}", animal.get_name());
}Now let's move on to the next category.
Ecosystem
Package Manager and Build System
Rust has Cargo that combines a very handy package manager and a build system. From your package description with all dependencies and any additional meta-information, Cargo automatically downloads, builds, and links these dependencies. Also, it is possible to specify additional building logic:

How can this be useful? For example, we can compile an implementation of the Protobuf specification as we build our package. And if we want to compile our Rust project with some C code, this can be done automatically at compile time by simply specifying which files should be linked to it.
Third-Party Libraries
The Rust ecosystem has a vast variety of packages that might come in handy for all sorts of situations, from various network protocol connectors to database connectors to HTTP frameworks. But if that's not enough for you, Rust has an interface to communicate with third-party languages. For example, you can write code in C and call it in Rust code:

This is very practical if you already have some of your code written in C — you can simply rewrite parts of it in Rust. Or vice versa, you have some Rust code, and you can integrate it into your project.
It is worth noting that calling C code by FFI is always considered unsafe in Rust. The programmer needs to be more thorough in order to handle cases where unsafe memory manipulation occurs. They should write a safe wrapper over an insecure interface.
Debugging Tools
Also, various debugging tools were brought to Rust from C. For example, Valgrind for searching leaks, GDB and LLDB debuggers, as well as perf and dtrace profilers. Here is an example of tracing a simple application via perf:

You can see that all the characters are pulled up quite conveniently. You can also check your functions to see how much CPU time they are consuming.
Documentation
Rust has a special website that contains documentation for all the packages from their registry. Comments for your functions can be included in your package as its documentation, letting you add parts of the documents directly into your code. The whole thing will be displayed on the documentation website along with the rest of the Rust packages documentation.
There is also a very good official documentation, the Rust book, available as a tutorial from the developers of the language. It describes all the components of the language with some examples. Basically, after reading the Rust book, you can pretty much say you know how to write in Rust.
And finally, there is the Rustonomicon, a detailed guide on how to properly write wrappers over unsafe code, that will be safe to work with from Rust code. This guide also describes some innards of the language, and is worth reading.
I would recommend taking the Rust tour for beginners — it shows all the capabilities of the language, with various examples for each.
And we still have one last category to figure out in order to understand the specifics of Rust.
Network Applications Development
Asynchronous Interfaces, Async/Await
Rust's standard library comes with interfaces that allow you to implement your asynchronous runtimes and interact with external ones from your code. But Rust itself doesn't contain any runtime — it's implemented by third-party developers. There are two most popular libraries for this: Tokio and async-std. They have similar interfaces and performance, but Tokio was introduced a little earlier, so it is more popular and has more packages for it.
Among the basics, Tokio includes a multithreaded work-stealing runtime for executing asynchronous code. This means that there is a thread pool inside the runtime that runs an OS thread for every CPU thread. The asynchronous tasks that you execute in your code will be evenly balanced between these threads — that is, you can use all the processor cores in your code.
Work-stealing means that one of the threads, having completed all its tasks, can start performing tasks from the queue of another thread. This allows you to load the processor more evenly, and to avoid situations where one thread, having completed its tasks, is idle while waiting for new ones.
Besides, Tokio includes part of the standard library responsible for handling asynchronous code and carries a huge ecosystem of ready-to-use packages. In general, Tokio has an approach very similar to the one used in the Go language. Rust's analog of goroutines is a task, and they're balanced between threads in the runtime. Here's a fairly simple example of a TCP server:

First, we create a TcpListener, which will accept connections from the socket in an infinite thread. Each separate connection can be run in a dedicated task, which will be balanced between processor threads, evenly utilizing it.
Or, for example, just as in Go, you can create channels in Rust with Tokio that allow you to exchange data between tasks via messaging:

Conclusion
Rust can be a better substitute for C and C++ as a system programming language. For instance, it can be used to write modules for Linux that up to now could not be written in C++.
It is also suitable not only for system programming, but for application development. In fact, as I said, you can rewrite the backend to Rust and achieve a big performance boost.
Finally, Rust is good for writing modules for other languages (Lua, JS, Python) if you want to speed up code or if that language does not have the libraries you want to use.
Opinions expressed by DZone contributors are their own.
Comments