Rust’s Ownership and Borrowing Enforce Memory Safety
By using an ownership model, Rust takes a novel approach to ensure memory safety at compile time.
Join the DZone community and get the full member experience.
Join For FreeRust’s ownership and borrowing might be confusing if we don't grasp what's really going on. This is particularly true when applying a previously learned programming style to a new paradigm; we call this a paradigm shift. Ownership is a novel idea, yet tricky to understand at first, but it gets easier the more we work on it.
Before we go further about Rust’s ownership and borrowing, let’s first understand what “memory safety” and “memory leak” are and how programming languages deal with them.
What Is Memory Safety?
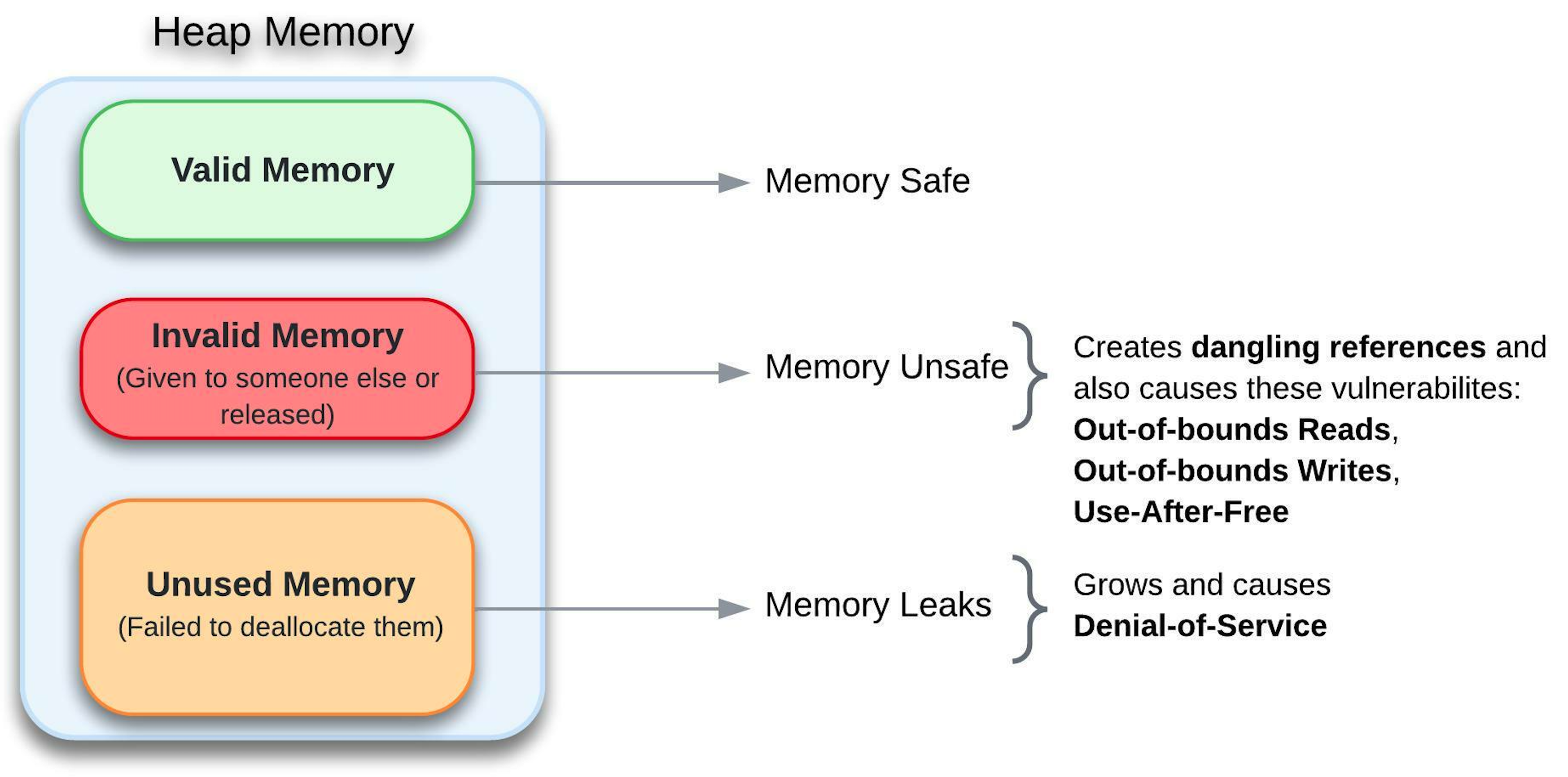
Memory safety refers to the state of a software application where memory pointers or references always refer to valid memory. Because memory corruption is a possibility, there are very few guarantees about a program's behaviour if it is not memory safe. Simply put, if a program isn't really memory safe, there are few assurances about its functionality. When dealing with a memory-unsafe program, a malicious party is able to use the flaw to read secrets or execute arbitrary code on someone else's machine.

Let's use pseudocode to see what valid memory is:
// pseudocode #1 - shows valid reference
{ // scope starts here
int x = 5
int y = &x
} // scope ends hereIn the above pseudocode, we’ve created a variable x assigned with a value of 10. We use the & operator or keyword to create a reference. Thus, the &x syntax lets us create a reference that refers to the value of x. To put it simply, we’ve created a variable x that owns 5 and a variable y that is a reference to x.
Since both variables x and y are in the same block or scope, variable y has a valid reference that refers to the value of x. As a result, variable y has a value of 5.
Take a look at the below pseudocode. As we can see, the scope of x is limited to the block in which it’s created. We get into dangling references when we try to access x outside of its scope. Dangling reference…? What exactly is it?
// pseudocode #2 - shows invalid reference aka dangling reference
{ // scope starts here
int x = 5
} // scope ends here
int y = &x // can't access x from here; creates dangling referenceDangling Reference
A dangling reference is a pointer that points to a memory location that has been given to someone else or released (freed). If a program (aka process) refers to memory that has been released or wiped out, it might crash or cause non-deterministic results.
Having said that, memory unsafety is a property of some programming languages that allows programmers to deal with invalid data. As a result, memory unsafety introduced a variety of problems that might cause the following major security vulnerabilities:
- Out-of-bounds Reads
- Out-of-bounds Writes
- Use-After-Free
Vulnerabilities caused by memory unsafety are at the root of many other serious security threats. Unfortunately, uncovering these vulnerabilities can be extremely challenging for developers.
What Is a Memory Leak?
It’s important to understand what a memory leak is and what its consequences are.

A memory leak is an unintentional form of memory consumption whereby the developer fails to free an allocated block of heap memory when it is no longer needed. It's simply the opposite of memory safety. More on the different memory types later, but for now, just know that a stack stores fixed-length variables known at compile time, whereas the size of variables that may change later at runtime must be placed on the heap.
When compared to heap memory allocation, stack memory allocation is considered to be safer since memory is automatically released when it is no longer relevant or necessary, either by the programmer or by the program runtime itself.
However, when programmers generate memory on the heap and fail to remove it in the absence of a garbage collector (in the case of C and C++), a memory leak develops. Also, if we lose all references to a chunk of memory without deallocating that memory, then we have a memory leak. Our program will continue to own that memory, but it has no way of ever using it again.
A little memory leak is not a problem, but if a program allocates a larger amount of memory and never deallocates it, the program’s memory footprint will continue to rise, resulting in Denial-of-Service.
When a program exits, the operating system immediately recovers all of the memory it owns. As a result, a memory leak only affects a program while it’s running; it has no effect once the program has terminated.
Let’s go over the key consequences of memory leaks.
Memory leaks reduce the performance of the computer by reducing the amount of available memory (heap memory). It eventually causes the whole or a portion of the system to stop working correctly or to slow down severely. Crashes are commonly linked with memory leaks.
Our approach to figuring out how to prevent memory leaks will vary depending on the programming language we’re using. Memory leaks might begin as a small and nearly “unnoticeable problem”, but they can escalate very quickly and overwhelm the systems they impact. Wherever feasible, we should be on the lookout for them and take action to rectify them rather than leave them to grow.
Memory Unsafety vs. Memory Leaks
Memory leaks and memory unsafety are the two types of issues that have received the greatest attention in terms of prevention and remediation. It's important to note that fixing one does not automatically fix the other.
Various Types of Memory and How They Operate
Before we go any further, it’s important to understand the different types of memory that our code will use at runtime.
There are two types of memory, as follows, and these memories are structured differently.
- Processor register
- Static
- Stack
- Heap
Both processor register and static memory types are beyond the scope of this post.
Stack Memory and How it Works
The stack stores data in the order in which it is received and removes it in the reverse order. Items can be accessed from the stack in the last in, first out (LIFO) order. Adding data onto the stack is called “pushing,” and removing data off the stack is called “popping.”
All data stored on the stack must have a known, fixed size. Data with an unknown size at compile time or a size that might change later on must be stored on the heap instead.
As developers, we do not have to worry about stack memory allocation and deallocation; the allocation and deallocation of stack memory is “automatically done” by the compiler. It implies that when data on the stack is no longer relevant (out of scope), it is automatically deleted without the need for our intervention.
This kind of memory allocation is also known as temporary memory allocation, because as soon as the function finishes its execution, all the data that belongs to that function is flushed out of the stack “automatically.”
All primitive types in Rust live on the stack. Types like numbers, characters, slices, booleans, fixed-size arrays, tuples containing primitives, and function pointers can all sit on the stack.
Heap Memory and How it Works
Unlike a stack, when we put data on the heap, we request a certain amount of space. The memory allocator locates a large enough unoccupied place in the heap, marks it as in use, and returns a reference to that location’s address. This is referred to as allocating.
Allocating on the heap is slower than pushing to the stack because the allocator never has to hunt for an empty location to put new data. Furthermore, because we must follow a pointer to get to data on the heap, it is slower than accessing data on the stack. Unlike the stack, which is allocated and deallocated at compile time, heap memory is allocated and deallocated during the execution of a program’s instructions.
In some programming languages, to allocate heap memory, we use the keyword new. This new keyword (aka operator) denotes a request for memory allocation on the heap. If sufficient memory is available on the heap, the new operator initialises the memory and returns the unique address of that newly allocated memory.
It’s worth mentioning that heap memory is “explicitly” deallocated by the programmer or the runtime.
How Do Various Other Programming Languages Guarantee Memory Safety?
When it comes to memory management, particularly heap memory, we’d prefer our programming languages to have the following characteristics:
- We’d prefer to release memory as soon as possible when it’s no longer needed, with no runtime overhead.
- We should never maintain a reference to a data that has been freed (aka a dangling reference). Otherwise, crashes and security issues might occur.
Memory safety is ensured in different ways by programming languages by means of:
- Explicit memory deallocation (adopted by Java, Python, and C#)
- Automatic or implicit memory deallocation (adopted by C, C++)
- Region-based memory management
- Linear or unique type systems
Both region-based memory management and linear type systems are beyond the scope of this post.
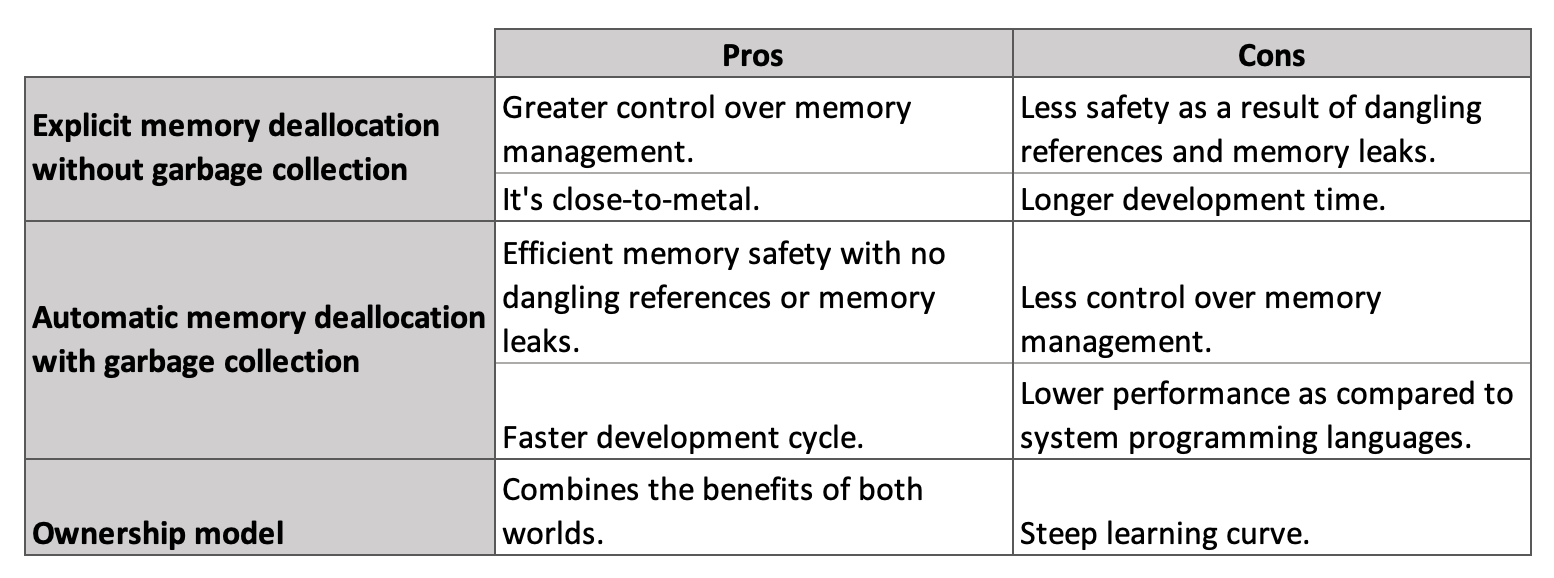
Manual or Explicit Memory Deallocation
Programmers must “manually” release or erase allocated memory when using explicit memory management. A “deallocation” operator (for instance, delete in C) exists in languages with explicit memory deallocation.
Garbage collection is too costly in systems languages like C and C++, therefore explicit memory allocation continues to exist.
Leaving the responsibility of freeing memory to the programmer has the benefit of giving the programmer total control over the life cycle of the variable. However, if deallocation operators are used incorrectly, a software fault may occur during execution. In fact, this manual allocation and releasing process is prone to errors. Some common coding errors include:
- Dangling reference
- Memory leak
Despite this, we preferred manual memory management over garbage collection since it gives us more control and provides better performance. Note that the goal of any system programming language is to get as "close to the metal" as possible. In other words, they favour better performance over convenience features in the tradeoff.
It’s entirely our (developers) responsibility to ensure that no pointer to the value we freed is ever used.
In the recent past, there have been several proven patterns for avoiding these errors, but it all boils down to maintaining rigorous code discipline, which requires applying the right memory management method consistently.
Key takeaways are:
- Have greater control over memory management.
- Less safety as a result of dangling references and memory leaks.
- Results in a longer development time.
Automatic or Implicit Memory Deallocation
Automatic memory management has become an essential feature of all modern programming languages, including Java.
In the case of automatic memory deallocation, the garbage collectors serve as automatic memory managers. These garbage collectors periodically go through the heap and recycle chunks of memory that are not being used. They manage the allocation and release of memory on our behalf. So we don’t have to write code to perform memory management tasks. That’s great since garbage collectors free us from the responsibility of memory management. Another advantage is that it reduces the development time.
Garbage collection, on the other hand, has a number of drawbacks. During garbage collection, the program should pause and spend time determining what it needs to clean up before proceeding.
Furthermore, automatic memory management has higher memory needs. This is due to the fact that a garbage collector performs memory deallocation for us, which consumes both memory and CPU cycles. As a result, automated memory management might degrade application performance, particularly in large applications with limited resources.
Key takeaways are:
- Eliminates the need for developers to release memory manually.
- Provides efficient memory safety with no dangling references or memory leaks.
- Simpler and straightforward code.
- Faster development cycle.
- Have less control over memory management.
- Causes latency as it consumes both memory and CPU cycles.
How Does Rust Guarantee Memory Safety?
Some languages provide garbage collection, which looks for memory that is no longer in use while the program runs; others require the programmer to explicitly allocate and release memory. Both of these models have benefits and drawbacks. Garbage collection, though perhaps the most widely used, has some drawbacks; it makes life easy for developers at the expense of resources and performance.
Having said that, one gives efficient memory management control, while the other provides higher safety by eliminating dangling references and memory leaks. Rust combines the benefits of both worlds.
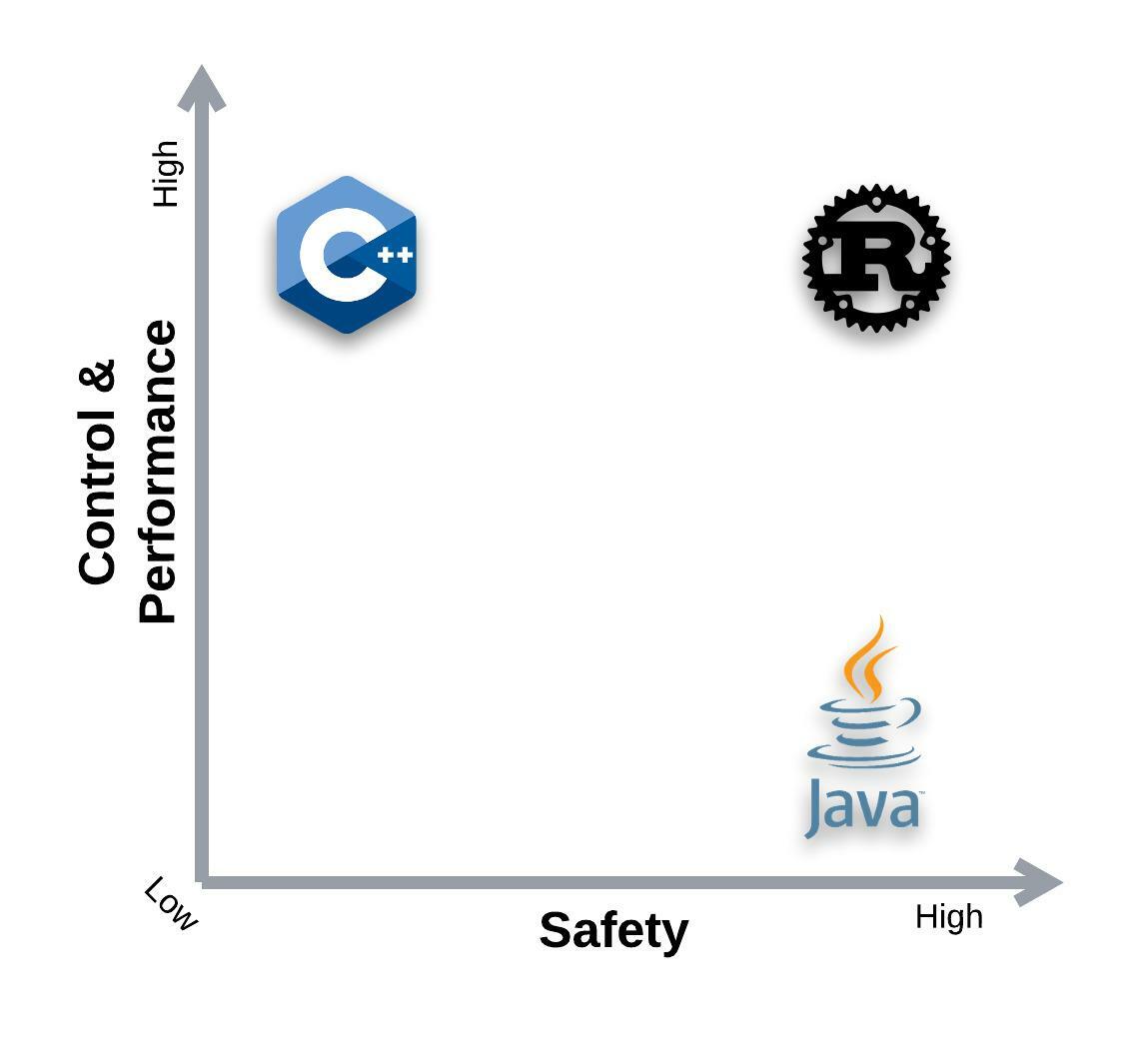
Rust takes a different approach to things than the other two, based on an ownership model with a set of rules that the compiler verifies to ensure memory safety. The program will not compile if any of these rules are violated. In fact, ownership replaces runtime garbage collection with compile-time checks for memory safety.
It takes some time to get used to ownership because it is a new concept for many programmers, like myself.
Ownership
At this point, we have a basic understanding of how data is stored in memory. Let's look at ownership in Rust more closely. Rust’s biggest distinguishing feature is ownership, which ensures memory safety at compile-time.
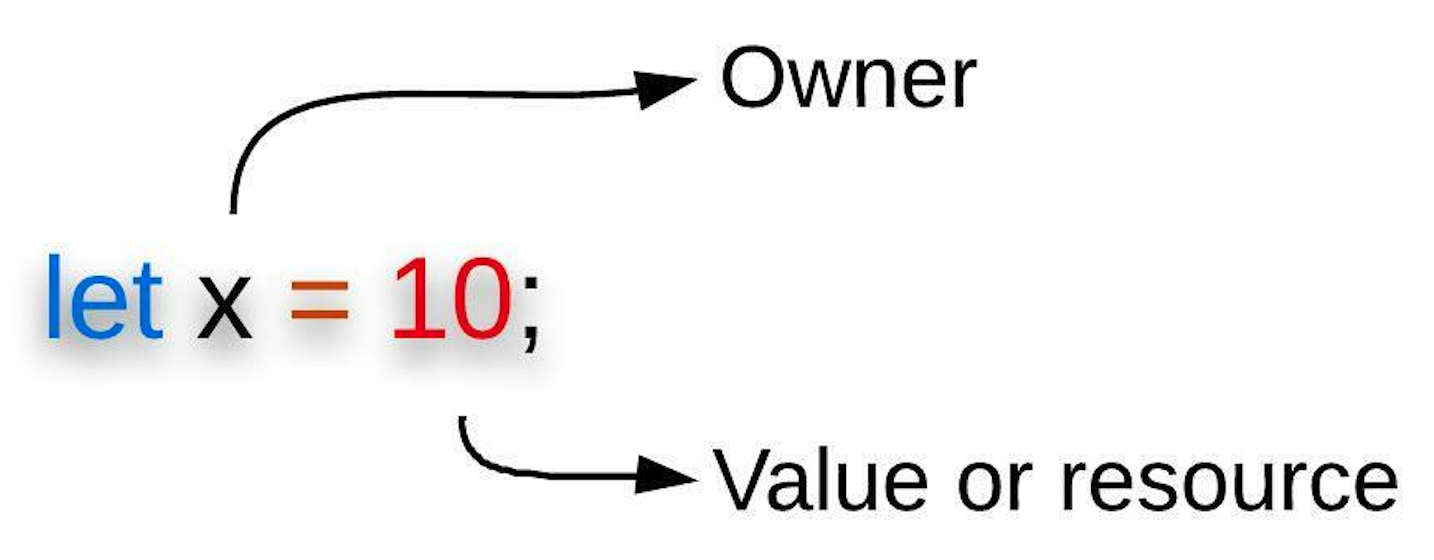
To begin, let's define “ownership” in its most literal sense. Ownership is the state of “owning” and “controlling” legal possession of “something”. With that said, we must identify who the owner is and what the owner owns and controls. In Rust, each value has a variable called its owner. To put it simply, a variable is an owner, and the value of a variable is what the owner owns and controls.
With an ownership model, memory is automatically released (freed) once the variable that owns it goes out of scope. When values go out of scope or their lifetimes end for some other reason, their destructors are called. A destructor, particularly an automated destructor, is a function that removes traces of a value from the program by deleting references and frees up memory.
Borrow Checker
Rust implements ownership through the borrow checker, a static analyzer. The borrow checker is a component in the Rust compiler that keeps track of where data is used throughout the program, and by following ownership rules, it’s able to determine where data needs to be released. Furthermore, the borrow checker ensures that deallocated memory can never be accessed at runtime. It even eliminates the possibility of data races caused by concurrent mutation (modification).
Ownership Rules
As previously stated, the ownership model is built on a set of rules known as the ownership rules, and these rules are relatively straightforward. The Rust compiler (rustc) enforces these rules:
- In Rust, each value has a variable called its owner.
- There can only be one owner at a time.
- When the owner goes out of scope, the value will be dropped.
The following memory errors are protected by these compile-time checking ownership rules:
- Dangling references: This is where a reference points to a memory address that no longer contains the data to which the pointer was referring; this pointer points to null or random data.
- Use after frees: This is where memory is accessed once it has been freed, which can crash. This memory location can also be used by hackers to execute code.
- Double frees: This is where allocated memory is freed, and then freed again. This might cause the program to crash, potentially exposing sensitive information. This also allows a hacker to run whatever code they choose.
- Segmentation faults: This is where the program tries to access memory it's not allowed to access.
- Buffer overrun: This is where the volume of data exceeds the storage capacity of the memory buffer, causing the program to crash.
Before getting into the details of each ownership rule, it's important to understand the distinctions between copy, move, and clone.
copy
A type with a fixed size (particularly primitive types) can be stored on the stack and popped off when its scope ends, and may be quickly and easily copied to create a new, independent variable if another part of the code requires the same value in a different scope. Because copying stack memory is cheap and fast, primitive types with a fixed-size are said to have copy semantics. It cheaply creates a perfect replica (a duplicate).
It's worth noting that primitive types with fixed-size implement the
copytrait to make copies.
let x = "hello";
let y = x;
println!("{}", x) // hello
println!("{}", y) // helloIn Rust, there are two kinds of strings:
String(heap allocated, and growable) and&str(fixed size, and can’t be mutated).
Because x is stored on the stack, copying its value to produce another copy for y is easier. This is not the case for a value that is stored on the heap. This is how the stack frame looks:
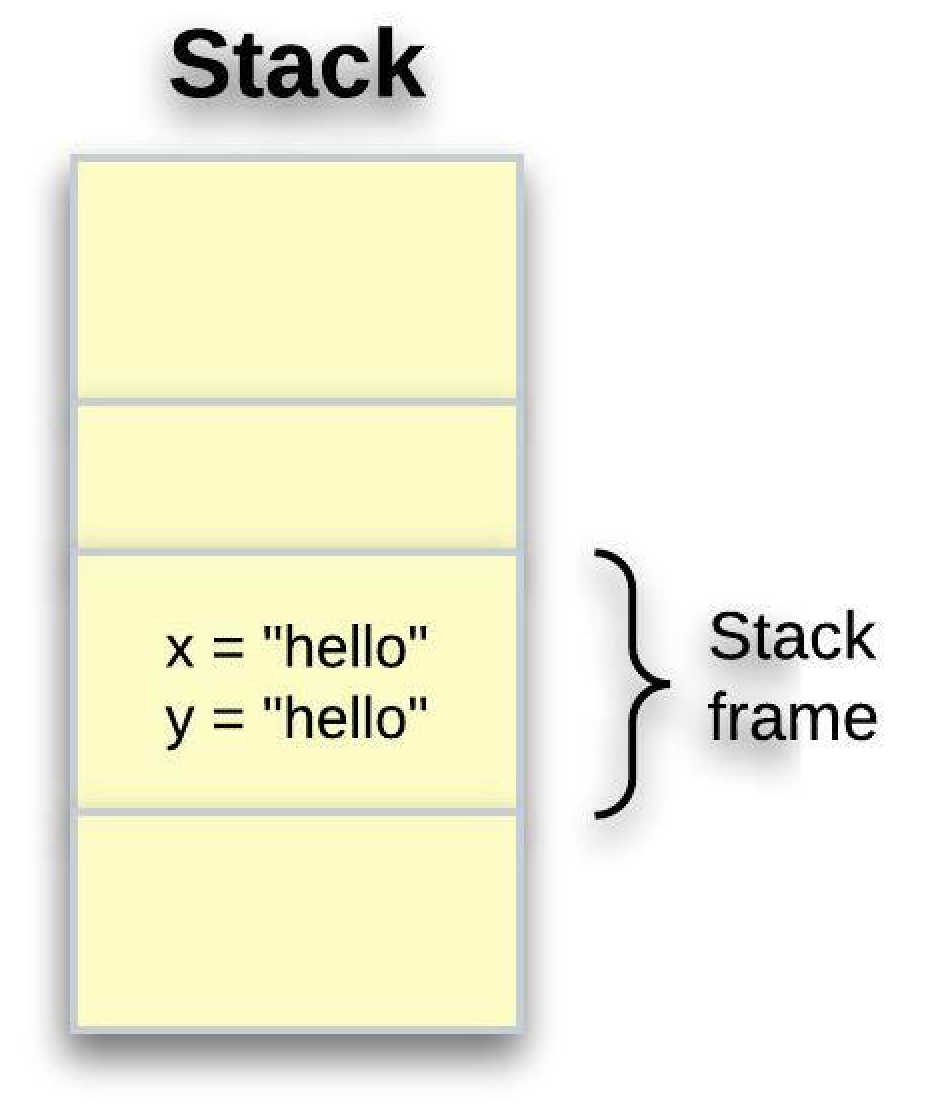
Duplicating data increases program runtime and memory consumption. Therefore, copying isn't a good fit for large chunks of data.
move
In Rust terminology, "move" means the ownership of the memory is transferred to another owner. Consider the case of complex types that are stored on the heap.
let s1 = String::from("hello");
let s2 = s1;We might assume that the second line (i.e. let s2 = s1;) would make a copy of the value in s1 and bind it to s2. But this is not the case.
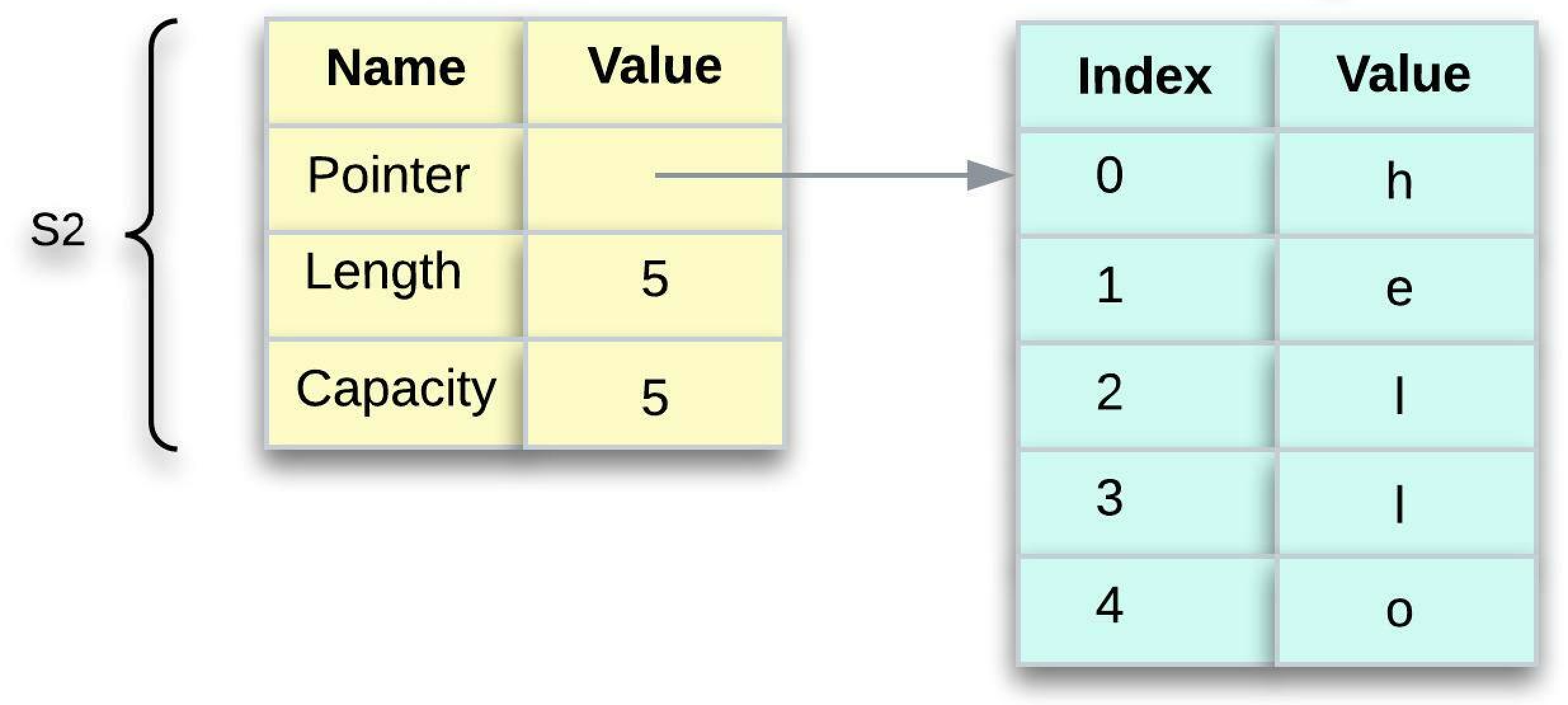
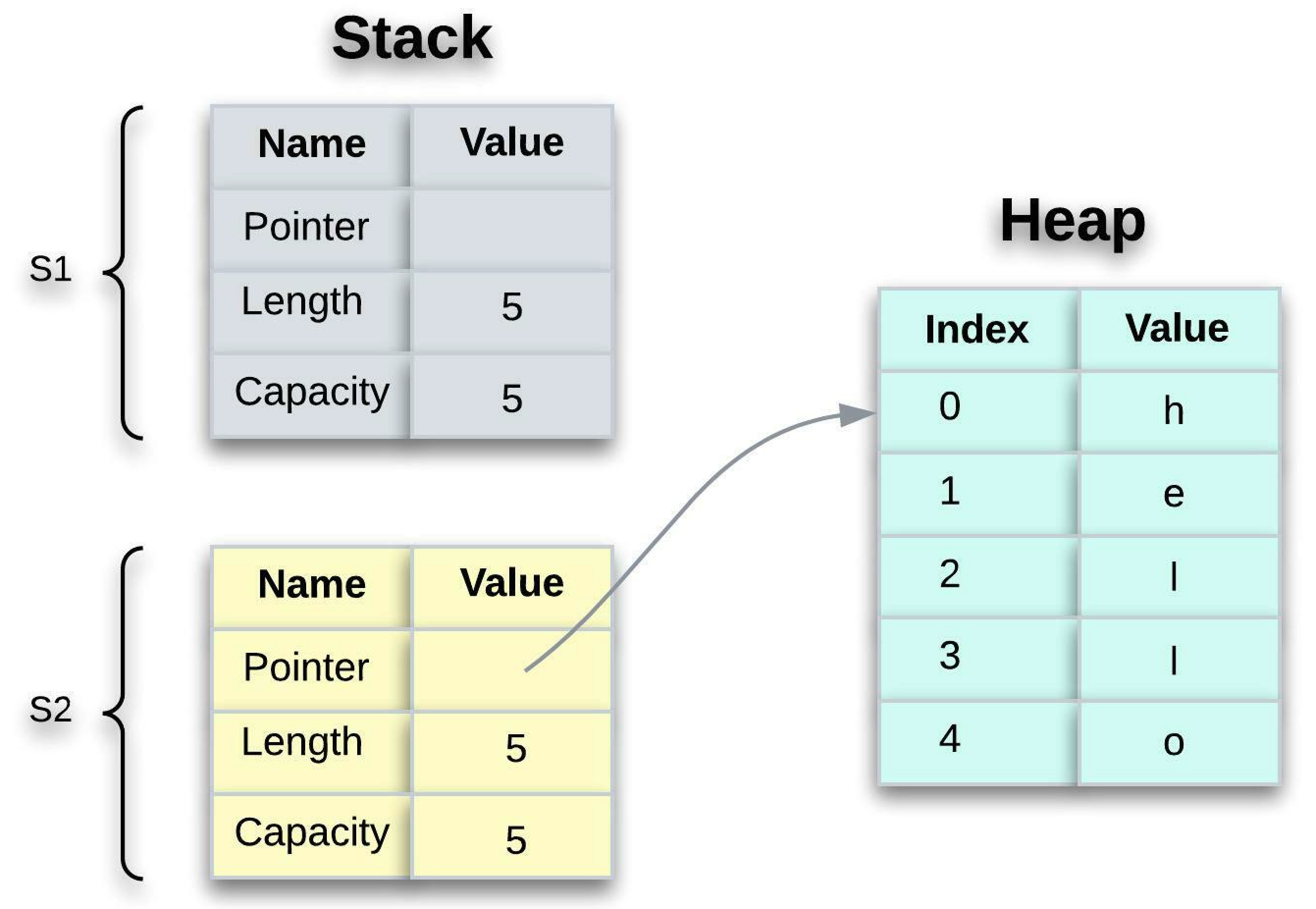
Take a look at the below one to see what’s happening to String under the hood. A String is made up of three parts, which are stored on the stack. The actual contents (hello, in this case) are stored on the heap.
- Pointer - points to the memory that holds the contents of the string.
- Length - it’s how much memory, in bytes, the contents of the
Stringis currently using. - Capacity - it’s the total amount of memory, in bytes, that the
Stringhas received from the allocator.
To put it in other words, the metadata is kept on the stack while the actual data is kept on the heap.
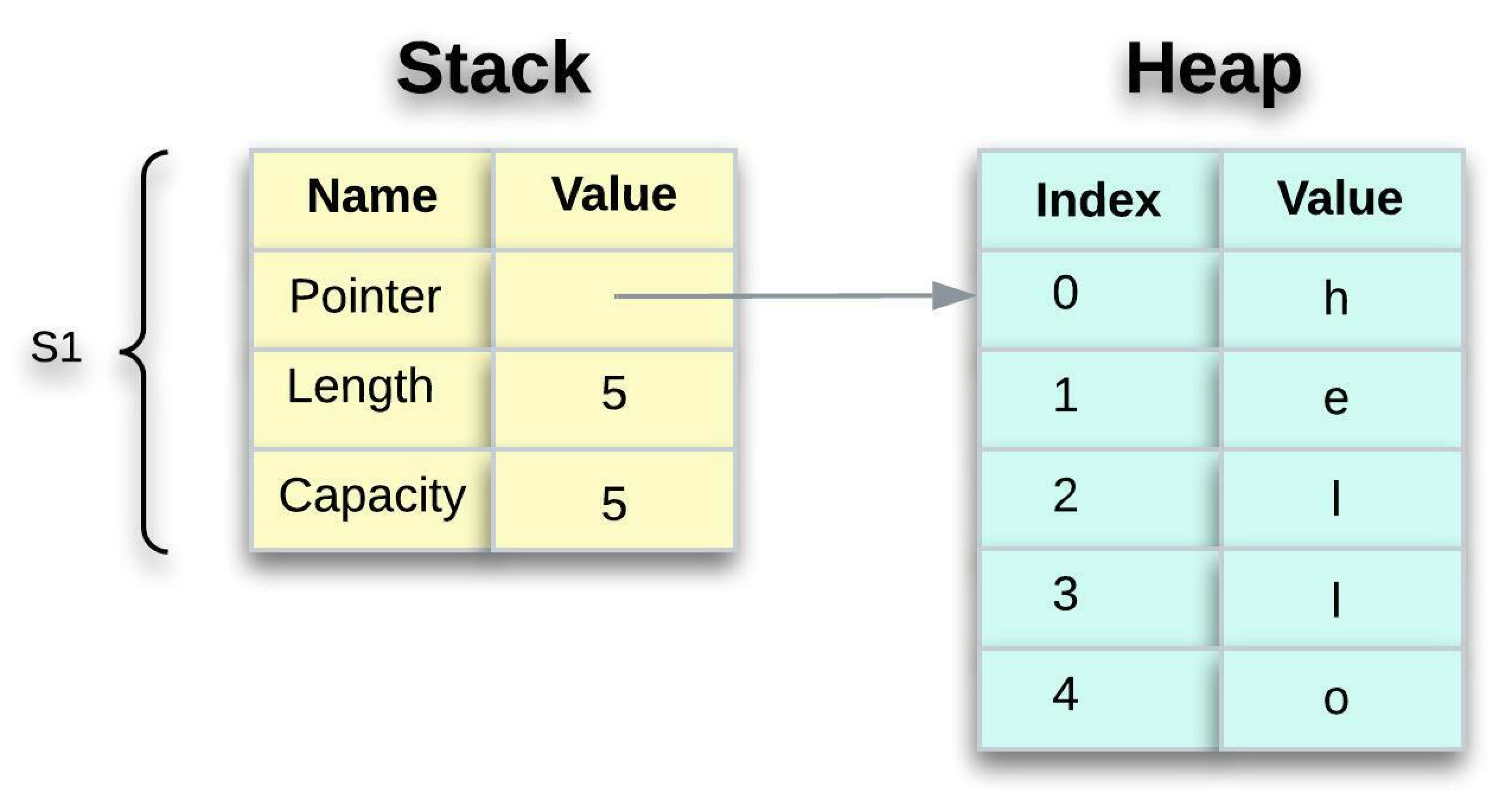
When we assign s1 to s2 , the String metadata is copied, meaning we copy the pointer, the length, and the capacity that are on the stack. We do not copy the data on the heap that the pointer refers to. The data representation in memory looks like the one below:
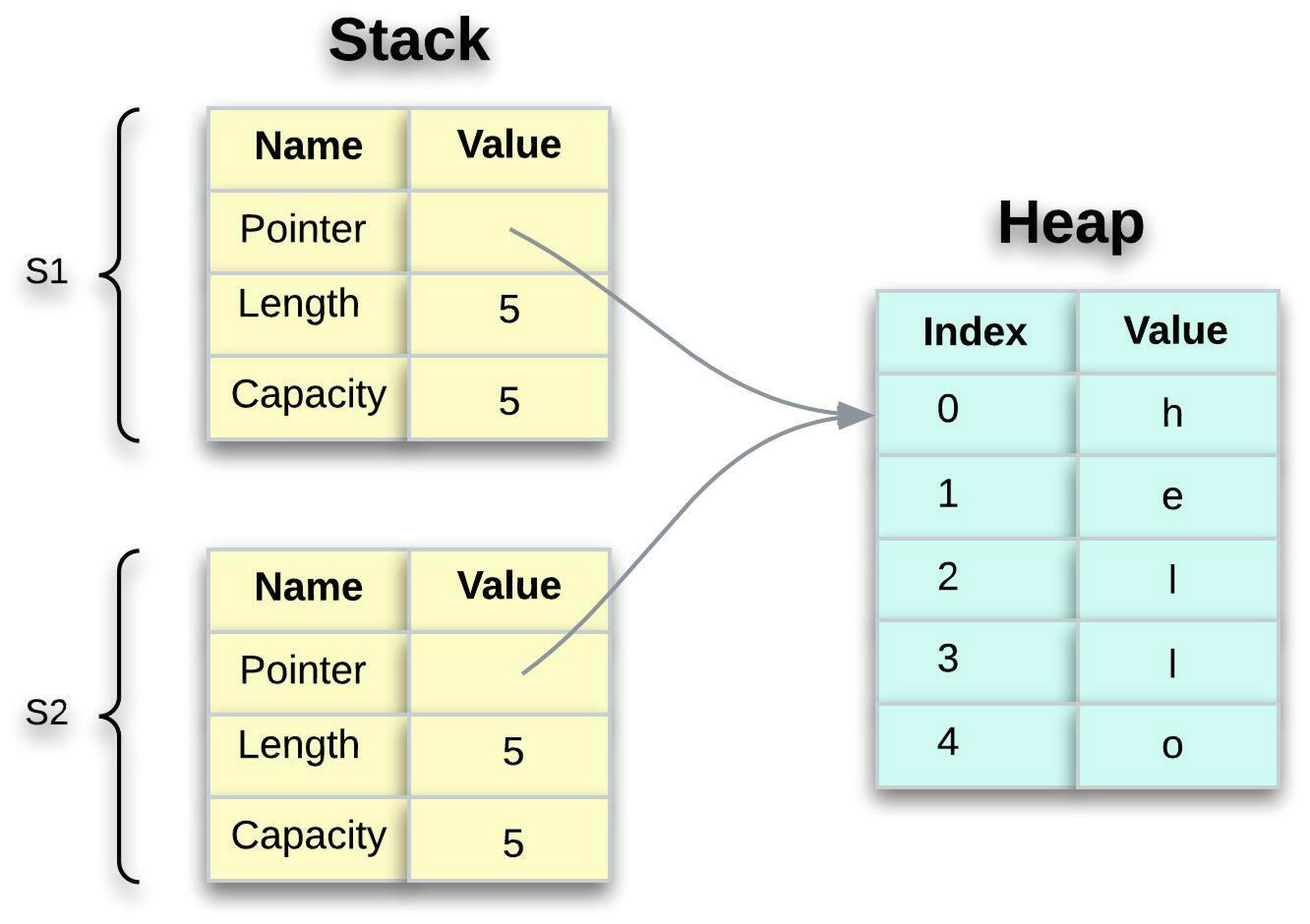
It's worth noting that the representation does not look like the one below, which is what memory would look like if Rust copied the heap data as well. If Rust performed this, the s2 = s1 operation could be extremely slow in terms of runtime performance if the heap data were large.
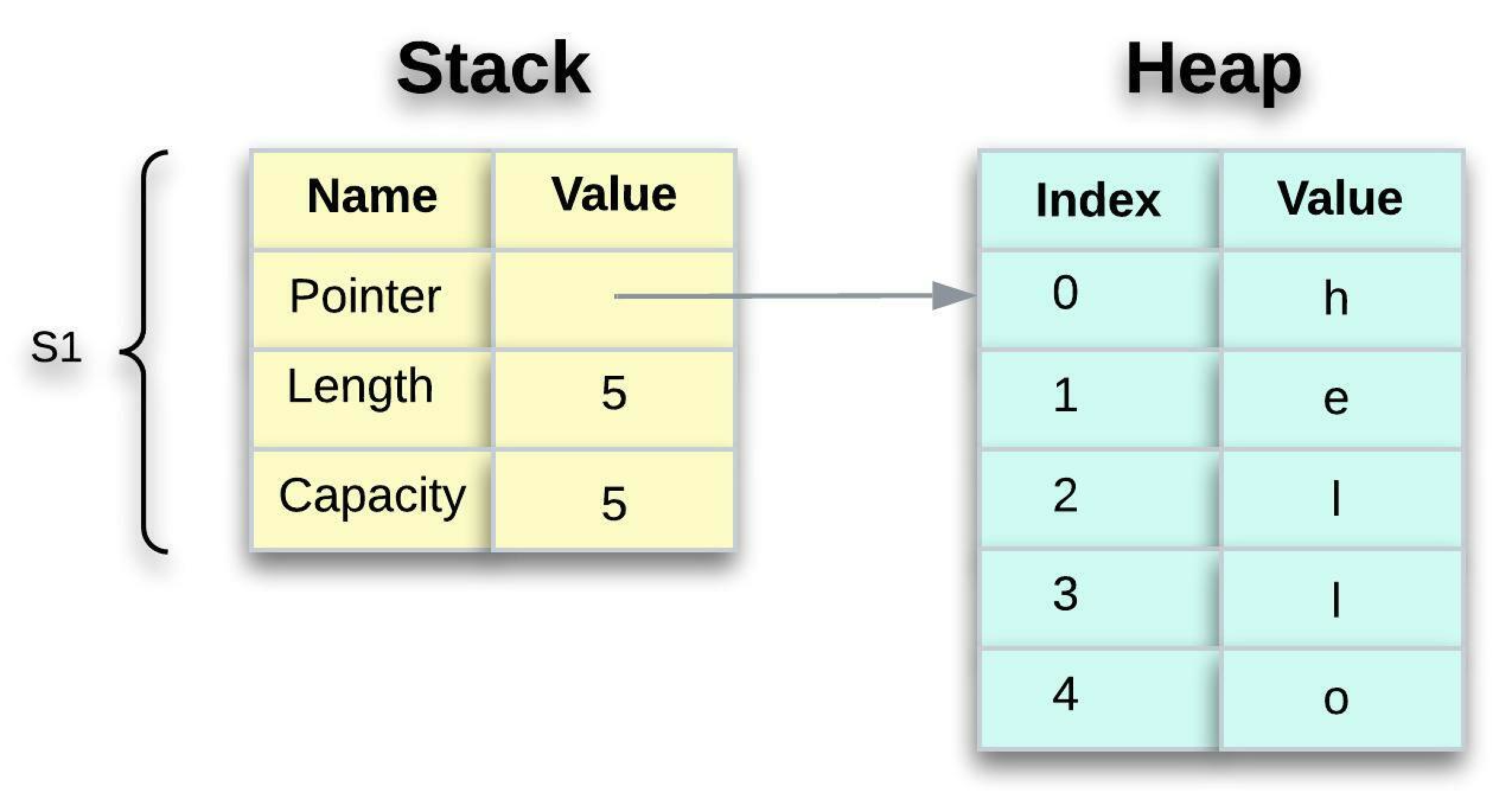
Note that when complex types are no longer in scope, Rust will call the drop function to explicitly deallocate heap memory. However, both data pointers in Figure 6 are pointing to the same location, which is not how Rust works. We will get into the details shortly.
As previously stated, when we assign s1 to s2, variable s2 receives a copy of s1's metadata (pointer, length, and capacity). But what happens to s1 once it's been assigned to s2? Rust no longer considers s1 to be valid. Yes, you read that correctly.
Let's think about this let s2 = s1 assignment for a moment. Consider what happens if Rust still considers s1 as valid after this assignment. When s2 and s1 go out of scope, they will both try to free the same memory. Uh-oh, that’s not good. This is referred to as a double free error, and it is one of the memory safety bugs. Memory corruption can result from freeing memory twice, posing a security risk.
To ensure memory safety, Rust considered s1 invalid after the line let s2 = s1. Therefore, when s1 is no longer in scope, Rust does not need to release anything. Examine what happens if we try to use s1 after s2 has been created.
let s1 = String::from("hello");
let s2 = s1;
println!("{}, world!", s1); // Won't compile. We'll get an error.We’ll get an error like the one below because Rust prevents you from using the invalidated reference:
$ cargo run
Compiling playground v0.0.1 (/playground)
error[E0382]: borrow of moved value: `s1`
--> src/main.rs:6:28
|
3 | let s1 = String::from("hello");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
4 | let s2 = s1;
| -- value moved here
5 |
6 | println!("{}, world!", s1);
| ^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0382`.As Rust "moved" s1 's ownership of the memory to s2 after the line let s2 = s1, it considered s1 invalid. Here is the memory representation after s1 has been invalidated:
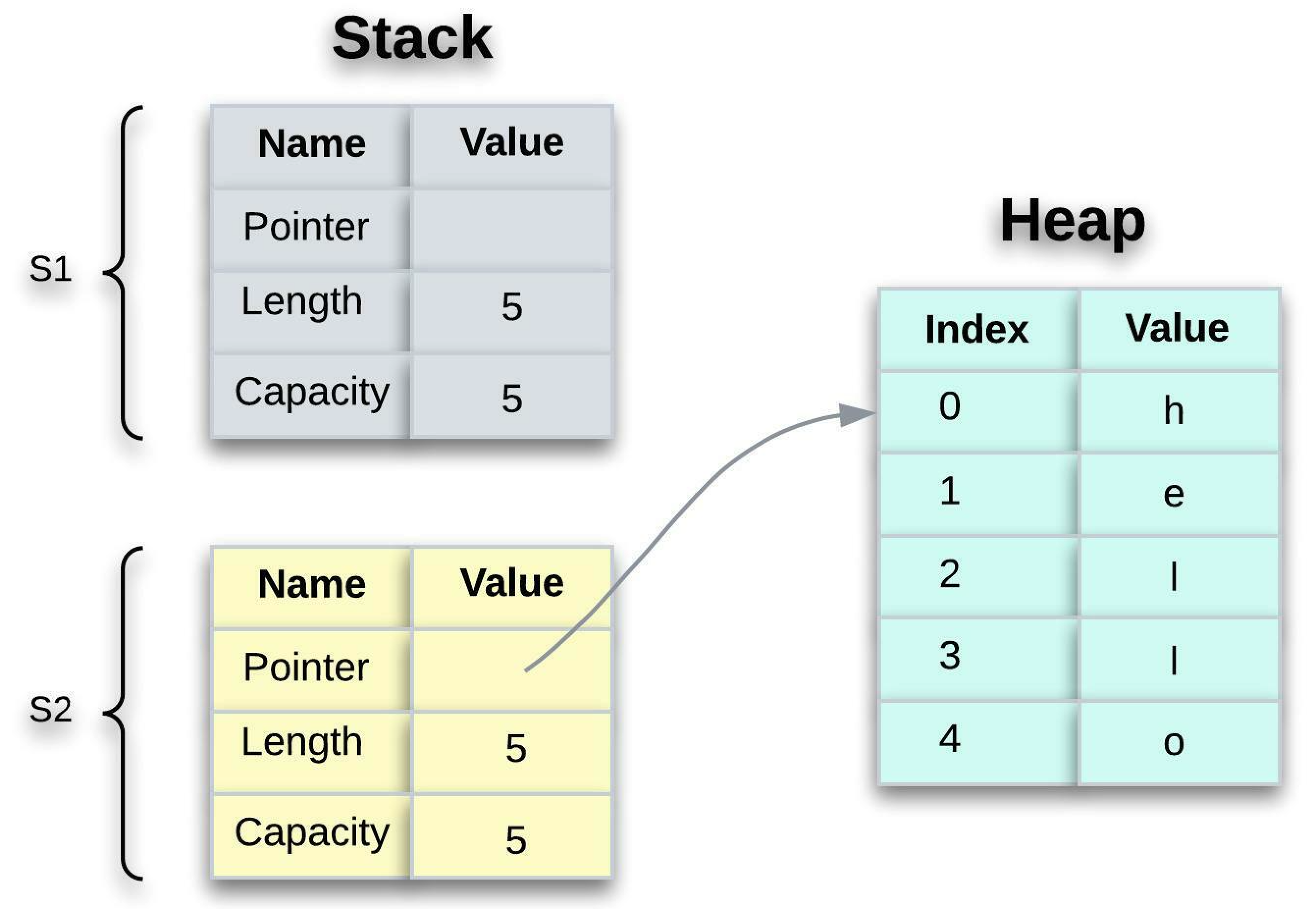
When only s2 remains valid, it alone will free the memory when it goes out of scope. As a result, the potential for a double free error is eliminated in Rust. That's wonderful!
clone
If we do want to deeply copy the heap data of the String, not just the stack data, we can use a method called clone. Here's an example of how to use the clone method:
let s1 = String::from("hello");
let s2 = s1.clone();
println!("s1 = {}, s2 = {}", s1, s2);When using the clone method, the heap data does get copied into s2. This works perfectly and produces the following behaviour:
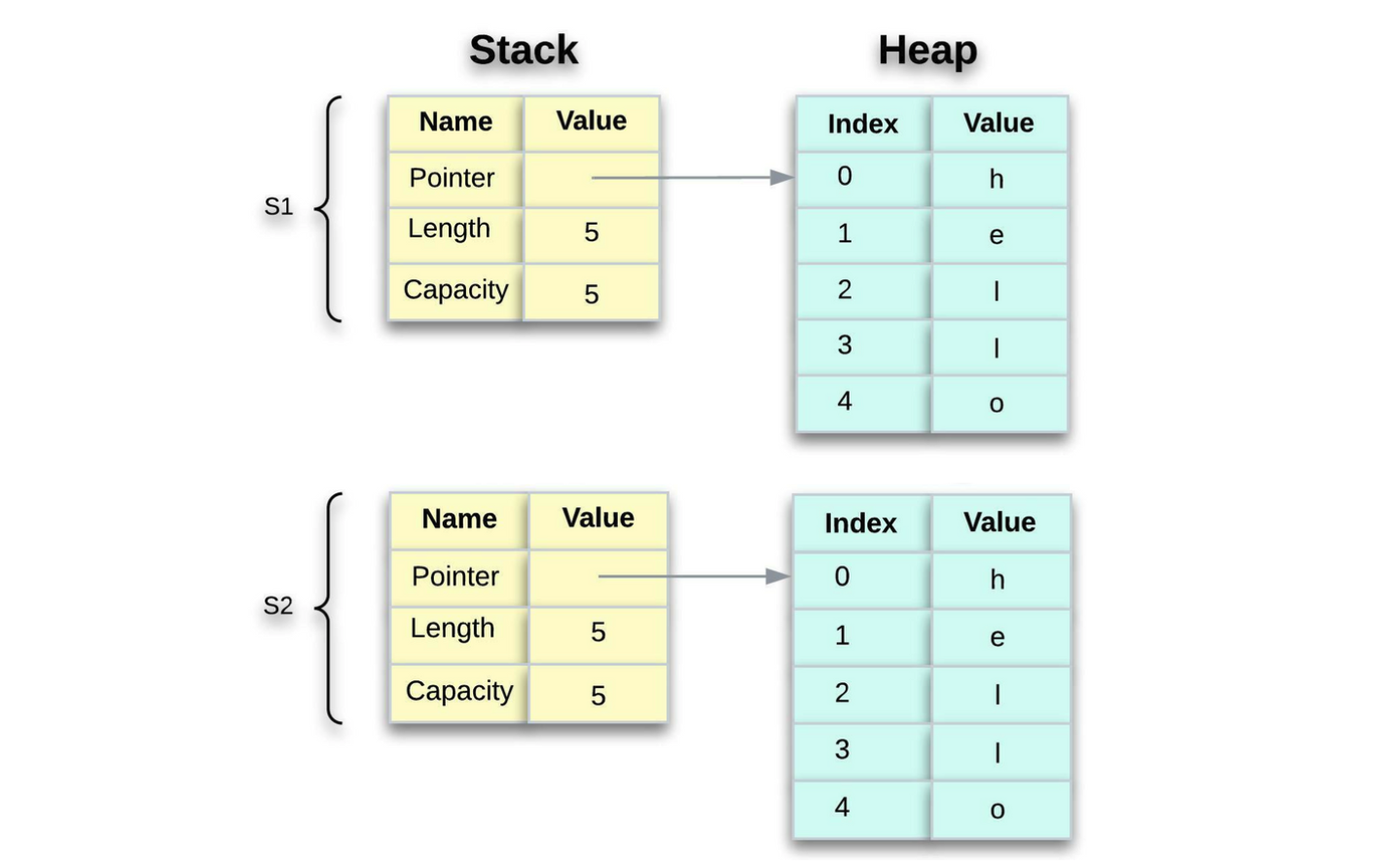
The use of the clone method has serious consequences; it not only copies the data, but it also does not synchronize any changes between the two. In general, clones should be planned carefully and with full awareness of the consequences.
By now, we should be able to distinguish between copy, move, and clone. Let's look at each ownership rule in more detail now.
Ownership Rule 1
Each value has a variable called its owner. It implies that all values are owned by variables. In the example below, variable s owns the pointer to our string, and in the second line, variable x owns a value 1.
let s = String::from("Rule 1");
let n = 1;Ownership Rule 2
There can only be one owner of a value at a given time. One can have many pets, but when it comes to the ownership model, there is only one value at any given moment :-)

Let’s look at the example using primitives, which are fixed-size known at compile time.
let x = 10;
let y = x;
let z = x;We have taken 10 and assigned it to x; in other words, x owns 10. Then we’re taking x and assigning it to y and we’re also assigning it to z. We know that there can only be one owner at a given time, but we’re not getting any errors here. So what's going on here is that the compiler is making copies of x every time we assign it to a new variable.
The stack frame for this would be as follows: x = 10, y = 10 and z = 10. This, however, does not appear to be the case as this: x = 10, y = x, and z = x. As we know, x is the sole owner of this value 10, and neither y nor z can own this value.
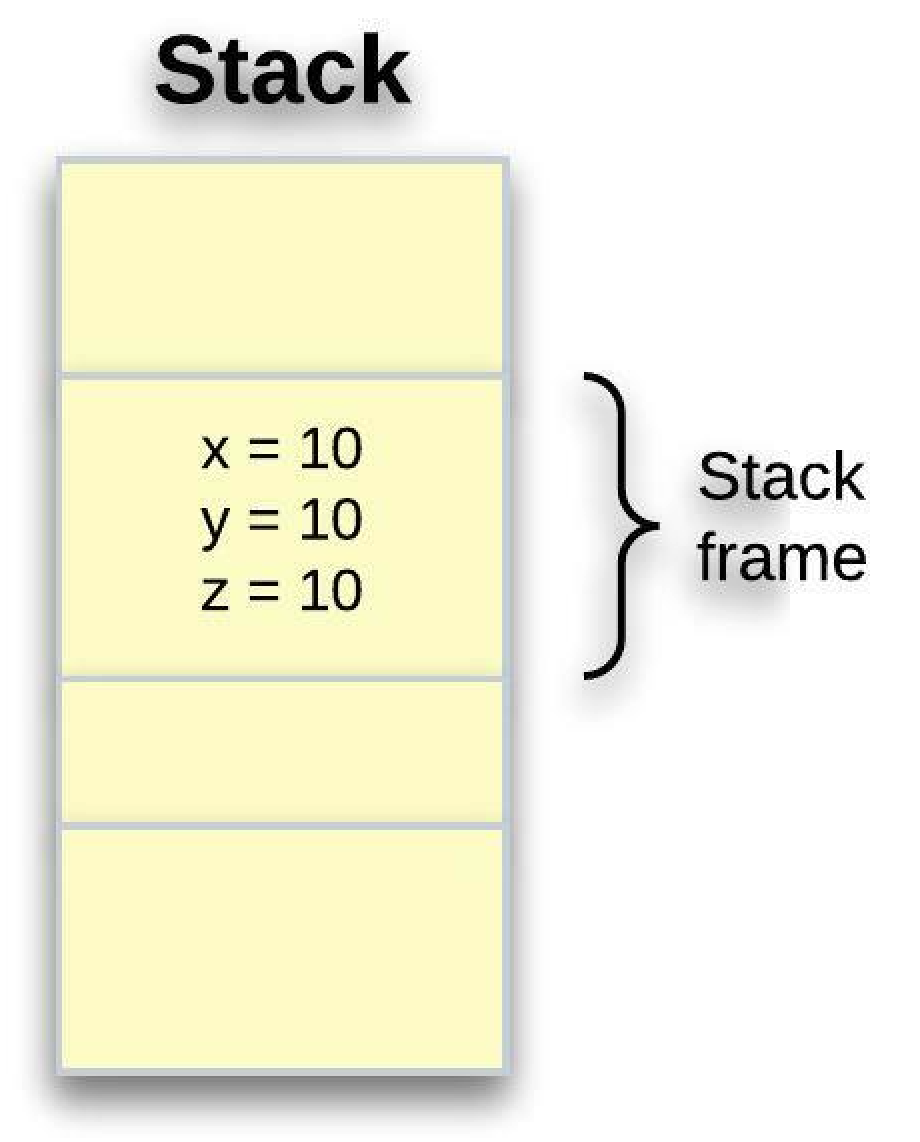
Because copying stack memory is cheap and fast, primitive types with a fixed-size are said to have copy semantics, whereas complex types move ownership, as previously stated. Thus, in this case, the compiler makes the copies.
At this point, the behaviour of variable binding is similar to that of other programming languages. To illustrate the rules of ownership, we need a complex data type.
Let's look at data that is stored on the heap and see how Rust understands when to clean it up; the String type is an excellent example for this use case. We'll focus on String's ownership-related behaviour; these principles, however, also apply to other complex data types.
The complex type, as we know, manages data on the heap, and its contents are unknown at compile time. Let’s look at the same example we have seen before:
let s1 = String::from("hello");
let s2 = s1;
println!("{}, world!", s1); // Won't compile. We'll get an error.In the case of String type, the size might expand and be stored on the heap. This means:
- At runtime, the memory must be requested from the memory allocator (let’s call it first part).
- When we're done using our
String, we need to return (release) this memory back to the allocator (let’s call it second part).
We (developers) took care of the first part: when we call String::from, its implementation requests the memory it needs. This part is almost common across programming languages.
However, the second part is different. In languages with a garbage collector (GC), the GC keeps track of and cleans up memory that is no longer in use, and we don’t have to worry about it. In languages without a garbage collector, it’s our responsibility to identify when memory is no longer needed and call for it to be explicitly released. It has always been a challenging programming task to do this correctly:
- We will waste memory if we forget.
- We will have an invalid variable if we do it too early.
- We will get a bug if we do it twice.
Rust handles memory deallocation in a novel way to make our lives easier: the memory is automatically returned once the variable that owns it goes out of scope.
Let's back to business. In Rust, for complex types, operations like assigning a value to a variable, passing it to a function, or returning it from a function don’t copy the value: they move it. To put it simply, complex types move ownership.
When complex types are no longer in scope, Rust will call the
dropfunction to explicitly deallocate heap memory.
Ownership Rule 3
When the owner goes out of scope, the value will be dropped. Consider the preceding case again:
When complex types are no longer in scope, Rust will call the drop function to explicitly deallocate heap memory.
let s1 = String::from("hello");
let s2 = s1;
println!("{}, world!", s1); // Won't compile. The value of s1 has already been dropped.The value of s1 has dropped after s1 is assigned to s2 (in the let s2 = s1 assignment statement). Thus, s1 is no longer valid after this assignment. Here is the memory representation after s1 has been dropped:
How Ownership Moves
There are three ways to transfer ownership from one variable to another in a Rust program:
- Assigning the value of one variable to another variable (it was already discussed).
- Passing value to a function.
- Returning from a function.
Passing Value to a Function
Passing a value to a function has semantics similar to assigning a value to a variable. Just like assignment, passing a variable to a function causes it to move or copy. Take a look at this example, which shows both the copy and move use cases:
fn main() {
let s = String::from("hello"); // s comes into scope
move_ownership(s); // s's value moves into the function...
// so it's no longer valid from this
// point forward
let x = 5; // x comes into scope
makes_copy(x); // x would move into the function
// It follows copy semantics since it's
// primitive, so we use x afterward
} // Here, x goes out of scope, then s. But because s's value was moved, nothing
// special happens.
fn move_ownership(some_string: String) { // some_string comes into scope
println!("{}", some_string);
} // Here, some_string goes out of scope and `drop` is called.
// The occupied memory is freed.
fn makes_copy(some_integer: i32) { // some_integer comes into scope
println!("{}", some_integer);
} // Here, some_integer goes out of scope. Nothing special happens.If we tried to use s after the call to move_ownership, Rust would throw a compile-time error.
Returning From a Function
Returning values can also transfer ownership. The example below shows a function that returns a value, with annotations identical to those in the previous example.
fn main() {
let s1 = gives_ownership(); // gives_ownership moves its return
// value into s1
let s2 = String::from("hello"); // s2 comes into scope
let s3 = takes_and_gives_back(s2); // s2 is moved into
// takes_and_gives_back, which also
// moves its return value into s3
} // Here, s3 goes out of scope and is dropped. s2 was moved, so nothing
// happens. s1 goes out of scope and is dropped.
fn gives_ownership() -> String { // gives_ownership will move its
// return value into the function
// that calls it
let some_string = String::from("yours"); // some_string comes into scope
some_string // some_string is returned and
// moves out to the calling
// function
}
// This function takes a String and returns it
fn takes_and_gives_back(a_string: String) -> String { // a_string comes into
// scope
a_string // a_string is returned and moves out to the calling function
}The ownership of a variable always follows the same pattern: a value is moved when it is assigned to another variable. Unless ownership of the data has been moved to another variable, when a variable that includes data on the heap goes out of scope, the value will be cleaned away by drop.
Hopefully, this gives us a basic understanding of what an ownership model is and how it influences the way Rust handles values, such as assigning them to one another and passing them into and out of functions.
Hold on. One more thing…
Rust's ownership model, as with all good things, does have certain drawbacks. We quickly realize certain inconveniences once we begin working on Rust. We may have observed that taking ownership and then returning ownership with each function is a little inconvenient.

It's annoying that everything we pass into a function must be returned if we want to use it again, in addition to any other data returned by that function. What if we want a function to use a value without taking ownership of it?
Consider the following example. The below code will result in an error because variable, v can no longer be used by the main function (in println!) that initially owned it once the ownership is transferred to the print_vector function.
fn main() {
let v = vec![10,20,30];
print_vector(v);
println!("{}", v[0]); // this line gives us an error
}
fn print_vector(x: Vec<i32>) {
println!("Inside print_vector function {:?}",x);
}Tracking ownership may seem easy enough, but it can get complicated when we start to deal with large and complex programs. So we need a way to transfer values without transferring ownership, which is where the concept of borrowing comes into play.
Borrowing
Borrowing, in its literal sense, refers to receiving something with the promise of returning it. In the context of Rust, borrowing is a way of accessing value without claiming ownership of it, as it must be returned to its owner at some point.

When we borrow a value, we reference its memory address with the & operator. A & is called a reference. The references themselves are nothing special—under the hood, they're just addresses. For those familiar with C pointers, a reference is a pointer to memory that contains a value that belongs to (aka owned by) another variable. It's worth noting that a reference can't be null in Rust. In fact, a reference is a pointer; it's the most basic type of pointer. There is just one type of pointer in most languages, but Rust has different kinds of pointers, rather than just one. Pointers and their various kinds are a different topic that will be discussed separately.
To put it simply, Rust refers to creating a reference to some value as borrowing the value, which must eventually return to its owner.
Let’s look at a simple example below:
let x = 5;
let y = &x;
println!("Value y={}", y);
println!("Address of y={:p}", y);
println!("Deref of y={}", *y);The above produces the following output:
Value y=5
Address of y=0x7fff6c0f131c
Deref of y=5Here, the y variable borrows the number owned by variable x, while x still owns the value. We call y a reference to x. The borrow ends when y goes out of scope, and because y does not own the value, it is not destroyed. To borrow a value, take a reference by the & operator. The p formatting, {:p} output as a memory location presented as hexadecimal.
Dereference: In the above code, "*" (i.e., an asterisk) is a dereference operator that operates on a reference variable. This dereferencing operator allows us to get the value stored in the memory address of a pointer.
Let's look at how a function can use a value without taking ownership through borrowing:
fn main() {
let v = vec![10,20,30];
print_vector(&v);
println!("{}", v[0]); // can access v here as references can't move the value
}
fn print_vector(x: &Vec<i32>) {
println!("Inside print_vector function {:?}", x);
}We are passing a reference (&v) (aka pass-by-reference) to the print_vector function rather than transferring the ownership (i.e., pass-by-value). As a result, after calling the print_vector function in the main function, we can access v.
Following the Pointer to the Value With the Dereference Operator
As stated previously, a reference is a kind of pointer, and a pointer may be thought of as an arrow pointing to a value stored elsewhere. Consider the below example:
let x = 5;
let y = &x;
assert_eq!(5, x);
assert_eq!(5, *y);In the above code, we create a reference to an i32 type value and then use the dereference operator to follow the reference to the data. The variable x holds an i32 type value, 5. We set y equal to a reference to x.
This is how the stack memory appears:

We can assert that x is equal to 5. However, if we want to make an assertion on the value in y, we must follow the reference to the value it's referring to using *y (hence dereference here). Once we dereference y, we have access to the integer value that y is pointing to, which we can compare to 5.
If we tried to write assert_eq!(5, y); instead, we would get this compilation error:
error[E0277]: can't compare `{integer}` with `&{integer}`
--> src/main.rs:11:5
|
11 | assert_eq!(5, y);
| ^^^^^^^^^^^^^^^^ no implementation for `{integer} == &{integer}`Because they're different types, comparing a number and a reference to a number isn't permitted. Hence, we must use the dereference operator to follow the reference to the value it’s pointing to.
References Are Immutable by Default
Like variable, a reference is immutable by default—it can be made mutable with mut, but only if its owner is also mutable:
let mut x = 5;
let y = &mut x;Immutable references are also known as shared references, whereas mutable references are also known as exclusive references.
Consider the below case. We're granting read-only access to references since we're using the & operator instead of &mut. Even if the source n is mutable, ref_to_n, and another_ref_to_n are not, as they are read-only n borrows.
let mut n = 10;
let ref_to_n = &n;
let another_ref_to_n = &n;The borrow checker will give the below error:
error[E0596]: cannot borrow `x` as mutable, as it is not declared as mutable
--> src/main.rs:4:9
|
3 | let x = 5;
| - help: consider changing this to be mutable: `mut x`
4 | let y = &mut x;
| ^^^^^^ cannot borrow as mutableBorrowing Rules
One could question why a borrowing would not always be preferred over a move. If that's the case, why does Rust even have move semantic, and why doesn't it borrow by default? The reason is that borrowing a value in Rust is not always possible. Borrowing is only permitted in certain cases.
Borrowing has its own set of rules, which the borrow checker strictly enforces during compile time. These rules were put in place to prevent data races. They are as follows:
- The scope of the borrower cannot outlast the scope of the original owner.
- There can be multiple immutable references, but only one mutable reference.
- Owners can have immutable or mutable references, but not both at the same time.
- All references must be valid (can’t be null).
Reference Must Not Outlive the Owner
A reference's scope must be contained within the scope of the owner of the value. Otherwise, the reference may refer to a freed value, resulting in a use-after-free error.
let x;
{
let y = 0;
x = &y;
}
println!("{}", x);The above program tries to dereference x after the owner y goes out of scope. Rust prevents this use-after-free error.
Many Immutable References, but Only One Mutable Reference Allowed
We can have as many immutable references (aka shared references) to a particular piece of data at a time, but only one mutable reference (aka exclusive reference) is allowed at a moment. This rule exists to eliminate data races. When two references point to the same memory location at the same time, at least one of them is writing, and their actions are not synchronized, this is known as a data race.
We may have as many immutable references as we like because they don't change the data. Borrowing, on the other hand, restricts us to just keeping one mutable reference (&mut) at a time to prevent the possibility of data races at compile time.
Let’s look at this one:
fn main() {
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{}, {}", r1, r2);
}The above code attempts to create two mutable references (r1 and r2) to s will fail:
error[E0499]: cannot borrow `s` as mutable more than once at a time
--> src/main.rs:6:14
|
5 | let r1 = &mut s;
| ------ first mutable borrow occurs here
6 | let r2 = &mut s;
| ^^^^^^ second mutable borrow occurs here
7 |
8 | println!("{}, {}", r1, r2);
| -- first borrow later used hereClosing Remarks
Hopefully, this clarifies the concepts of ownership and borrowing. I also briefly touched on the borrow checker, the backbone of ownership and borrowing. As I mentioned at the beginning, ownership is a novel idea that might be difficult to comprehend at first, even for seasoned developers, but gets easier and easier the more you work on it. This is just a rundown of how memory safety is enforced in Rust. I attempted to make this post as easy to understand as possible while yet providing enough information to grasp the concepts. For more details on Rust's ownership feature, check out their online documentation.
Rust is a great choice when performance matters and it solves pain points that bother many other languages, resulting in a significant step forward with a steep learning curve. For the sixth year in a row, Rust has been Stack Overflow's most loved language, implying that many people who have had the chance to use it have fallen in love with it. The Rust community continues to grow.
According to Rust Survey 2021 Results: The year 2021 was undoubtedly one of the most momentous in Rust's history. It saw the founding of the Rust Foundation, the 2021 edition, and a larger community than ever before. Rust appears to be on a strong road as we head into the future.
Happy learning!
Opinions expressed by DZone contributors are their own.
Comments